 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Boosting LLM Reasoning via Spontaneous Self-Correction
Jun 07, 2025



While large language models (LLMs) have demonstrated remarkable success on a broad range of tasks, math reasoning remains a challenging one. One of the approaches for improving math reasoning is self-correction, which designs self-improving loops to let the model correct its own mistakes. However, existing self-correction approaches treat corrections as standalone post-generation refinements, relying on extra prompt and system designs to elicit self-corrections, instead of performing real-time, spontaneous self-corrections in a single pass. To address this, we propose SPOC, a spontaneous self-correction approach that enables LLMs to generate interleaved solutions and verifications in a single inference pass, with generation dynamically terminated based on verification outcomes, thereby effectively scaling inference time compute. SPOC considers a multi-agent perspective by assigning dual roles -- solution proposer and verifier -- to the same model. We adopt a simple yet effective approach to generate synthetic data for fine-tuning, enabling the model to develop capabilities for self-verification and multi-agent collaboration. We further improve its solution proposal and verification accuracy through online reinforcement learning. Experiments on mathematical reasoning benchmarks show that SPOC significantly improves performance. Notably, SPOC boosts the accuracy of Llama-3.1-8B and 70B Instruct models, achieving gains of 8.8% and 11.6% on MATH500, 10.0% and 20.0% on AMC23, and 3.3% and 6.7% on AIME24, respectively.
Reinforcement Learning-based Token Pruning in Vision Transformers: A Markov Game Approach
Mar 30, 2025



Vision Transformers (ViTs) have computational costs scaling quadratically with the number of tokens, calling for effective token pruning policies. Most existing policies are handcrafted, lacking adaptivity to varying inputs. Moreover, they fail to consider the sequential nature of token pruning across multiple layers. In this work, for the first time (as far as we know), we exploit Reinforcement Learning (RL) to data-adaptively learn a pruning policy. Formulating token pruning as a sequential decision-making problem, we model it as a Markov Game and utilize Multi-Agent Proximal Policy Optimization (MAPPO) where each agent makes an individualized pruning decision for a single token. We also develop reward functions that enable simultaneous collaboration and competition of these agents to balance efficiency and accuracy. On the well-known ImageNet-1k dataset, our method improves the inference speed by up to 44% while incurring only a negligible accuracy drop of 0.4%. The source code is available at https://github.com/daashuai/rl4evit.
Self-Generated Critiques Boost Reward Modeling for Language Models
Nov 25, 2024



Reward modeling is crucial for aligning large language models (LLMs) with human preferences, especially in reinforcement learning from human feedback (RLHF). However, current reward models mainly produce scalar scores and struggle to incorporate critiques in a natural language format. We hypothesize that predicting both critiques and the scalar reward would improve reward modeling ability. Motivated by this, we propose Critic-RM, a framework that improves reward models using self-generated critiques without extra supervision. Critic-RM employs a two-stage process: generating and filtering high-quality critiques, followed by joint fine-tuning on reward prediction and critique generation. Experiments across benchmarks show that Critic-RM improves reward modeling accuracy by 3.7%-7.3% compared to standard reward models and LLM judges, demonstrating strong performance and data efficiency. Additional studies further validate the effectiveness of generated critiques in rectifying flawed reasoning steps with 2.5%-3.2% gains in improving reasoning accuracy.
Law of the Weakest Link: Cross Capabilities of Large Language Models
Sep 30, 2024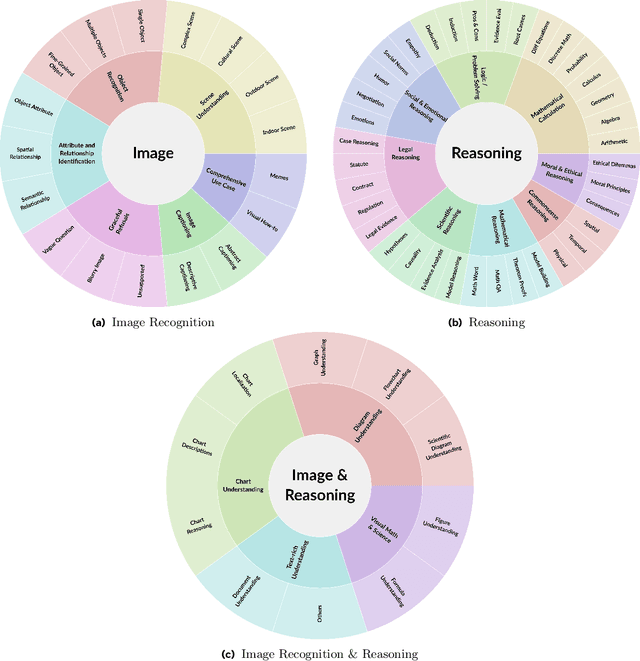
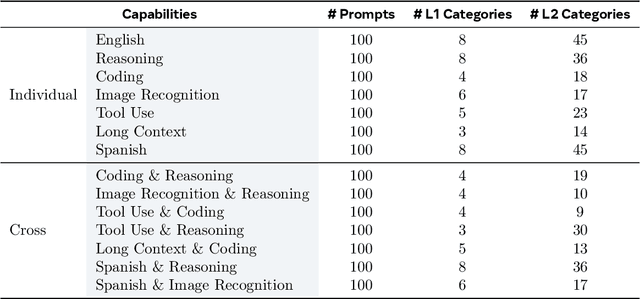
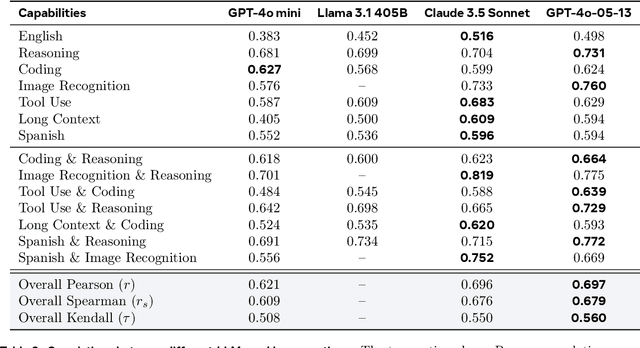
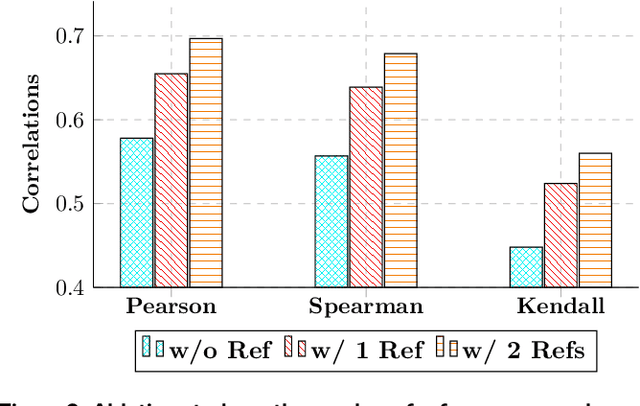
The development and evaluation of Large Language Models (LLMs) have largely focused on individual capabilities. However, this overlooks the intersection of multiple abilities across different types of expertise that are often required for real-world tasks, which we term cross capabilities. To systematically explore this concept, we first define seven core individual capabilities and then pair them to form seven common cross capabilities, each supported by a manually constructed taxonomy. Building on these definitions, we introduce CrossEval, a benchmark comprising 1,400 human-annotated prompts, with 100 prompts for each individual and cross capability. To ensure reliable evaluation, we involve expert annotators to assess 4,200 model responses, gathering 8,400 human ratings with detailed explanations to serve as reference examples. Our findings reveal that, in both static evaluations and attempts to enhance specific abilities, current LLMs consistently exhibit the "Law of the Weakest Link," where cross-capability performance is significantly constrained by the weakest component. Specifically, across 58 cross-capability scores from 17 models, 38 scores are lower than all individual capabilities, while 20 fall between strong and weak, but closer to the weaker ability. These results highlight the under-performance of LLMs in cross-capability tasks, making the identification and improvement of the weakest capabilities a critical priority for future research to optimize performance in complex, multi-dimensional scenarios.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Scaling User Modeling: Large-scale Online User Representations for Ads Personalization in Meta
Nov 16, 2023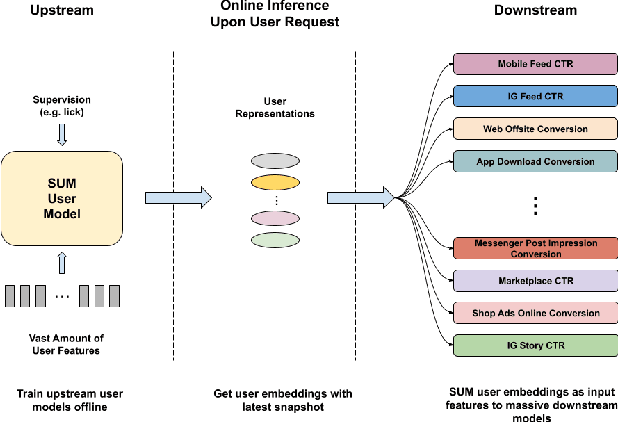
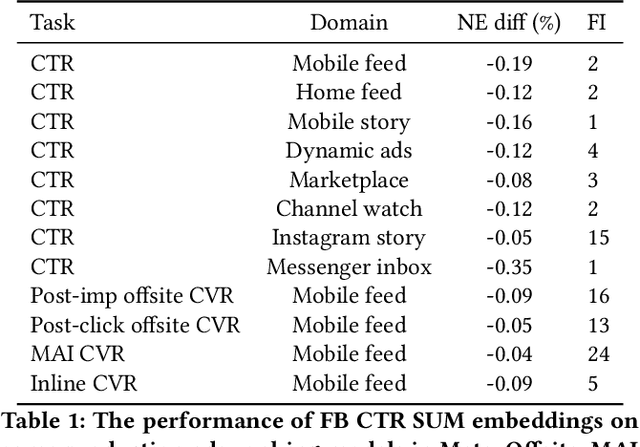
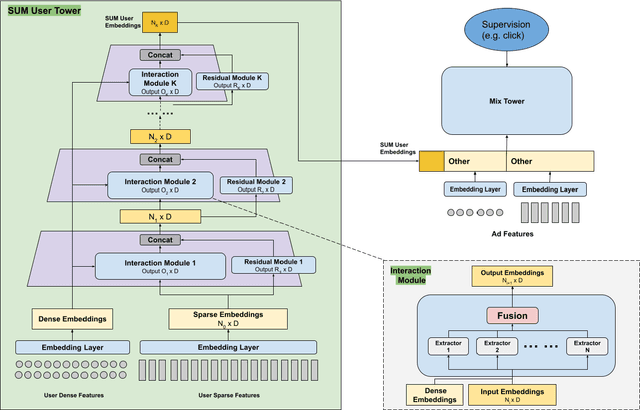

Effective user representations are pivotal in personalized advertising. However, stringent constraints on training throughput, serving latency, and memory, often limit the complexity and input feature set of online ads ranking models. This challenge is magnified in extensive systems like Meta's, which encompass hundreds of models with diverse specifications, rendering the tailoring of user representation learning for each model impractical. To address these challenges, we present Scaling User Modeling (SUM), a framework widely deployed in Meta's ads ranking system, designed to facilitate efficient and scalable sharing of online user representation across hundreds of ads models. SUM leverages a few designated upstream user models to synthesize user embeddings from massive amounts of user features with advanced modeling techniques. These embeddings then serve as inputs to downstream online ads ranking models, promoting efficient representation sharing. To adapt to the dynamic nature of user features and ensure embedding freshness, we designed SUM Online Asynchronous Platform (SOAP), a latency free online serving system complemented with model freshness and embedding stabilization, which enables frequent user model updates and online inference of user embeddings upon each user request. We share our hands-on deployment experiences for the SUM framework and validate its superiority through comprehensive experiments. To date, SUM has been launched to hundreds of ads ranking models in Meta, processing hundreds of billions of user requests daily, yielding significant online metric gains and infrastructure cost savings.
Towards the Better Ranking Consistency: A Multi-task Learning Framework for Early Stage Ads Ranking
Jul 12, 2023



Dividing ads ranking system into retrieval, early, and final stages is a common practice in large scale ads recommendation to balance the efficiency and accuracy. The early stage ranking often uses efficient models to generate candidates out of a set of retrieved ads. The candidates are then fed into a more computationally intensive but accurate final stage ranking system to produce the final ads recommendation. As the early and final stage ranking use different features and model architectures because of system constraints, a serious ranking consistency issue arises where the early stage has a low ads recall, i.e., top ads in the final stage are ranked low in the early stage. In order to pass better ads from the early to the final stage ranking, we propose a multi-task learning framework for early stage ranking to capture multiple final stage ranking components (i.e. ads clicks and ads quality events) and their task relations. With our multi-task learning framework, we can not only achieve serving cost saving from the model consolidation, but also improve the ads recall and ranking consistency. In the online A/B testing, our framework achieves significantly higher click-through rate (CTR), conversion rate (CVR), total value and better ads-quality (e.g. reduced ads cross-out rate) in a large scale industrial ads ranking system.
How to Build User Simulators to Train RL-based Dialog Systems
Sep 03, 2019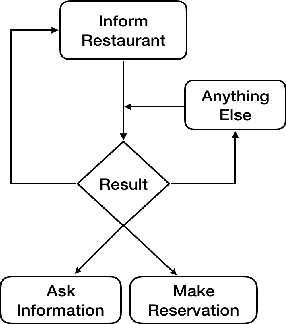

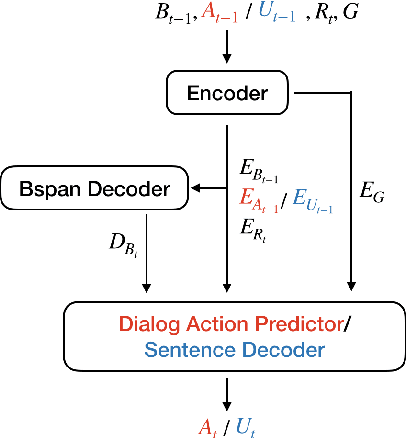

User simulators are essential for training reinforcement learning (RL) based dialog models. The performance of the simulator directly impacts the RL policy. However, building a good user simulator that models real user behaviors is challenging. We propose a method of standardizing user simulator building that can be used by the community to compare dialog system quality using the same set of user simulators fairly. We present implementations of six user simulators trained with different dialog planning and generation methods. We then calculate a set of automatic metrics to evaluate the quality of these simulators both directly and indirectly. We also ask human users to assess the simulators directly and indirectly by rating the simulated dialogs and interacting with the trained systems. This paper presents a comprehensive evaluation framework for user simulator study and provides a better understanding of the pros and cons of different user simulators, as well as their impacts on the trained systems.
Persuasion for Good: Towards a Personalized Persuasive Dialogue System for Social Good
Jun 16, 2019
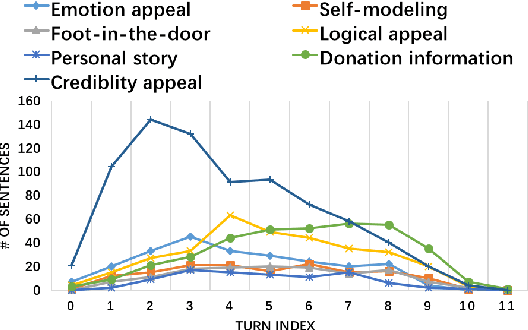
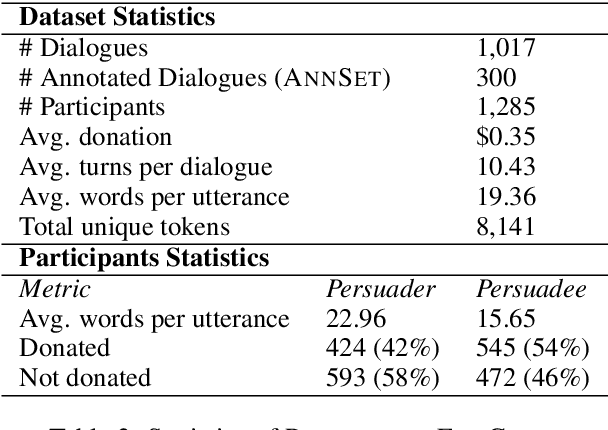
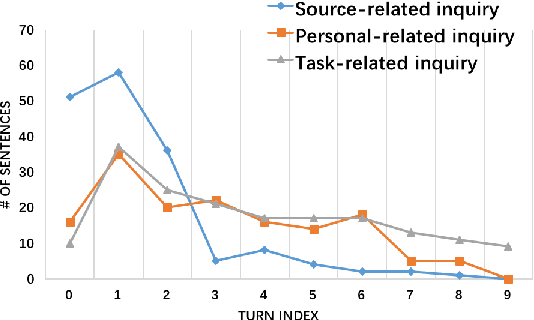
Developing intelligent persuasive conversational agents to change people's opinions and actions for social good is the frontier in advancing the ethical development of automated dialogue systems. To do so, the first step is to understand the intricate organization of strategic disclosures and appeals employed in human persuasion conversations. We designed an online persuasion task where one participant was asked to persuade the other to donate to a specific charity. We collected a large dataset with 1,017 dialogues and annotated emerging persuasion strategies from a subset. Based on the annotation, we built a baseline classifier with context information and sentence-level features to predict the 10 persuasion strategies used in the corpus. Furthermore, to develop an understanding of personalized persuasion processes, we analyzed the relationships between individuals' demographic and psychological backgrounds including personality, morality, value systems, and their willingness for donation. Then, we analyzed which types of persuasion strategies led to a greater amount of donation depending on the individuals' personal backgrounds. This work lays the ground for developing a personalized persuasive dialogue system.