 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Rubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following
Nov 13, 2025Recent progress in large language models (LLMs) has led to impressive performance on a range of tasks, yet advanced instruction following (IF)-especially for complex, multi-turn, and system-prompted instructions-remains a significant challenge. Rigorous evaluation and effective training for such capabilities are hindered by the lack of high-quality, human-annotated benchmarks and reliable, interpretable reward signals. In this work, we introduce AdvancedIF (we will release this benchmark soon), a comprehensive benchmark featuring over 1,600 prompts and expert-curated rubrics that assess LLMs ability to follow complex, multi-turn, and system-level instructions. We further propose RIFL (Rubric-based Instruction-Following Learning), a novel post-training pipeline that leverages rubric generation, a finetuned rubric verifier, and reward shaping to enable effective reinforcement learning for instruction following. Extensive experiments demonstrate that RIFL substantially improves the instruction-following abilities of LLMs, achieving a 6.7% absolute gain on AdvancedIF and strong results on public benchmarks. Our ablation studies confirm the effectiveness of each component in RIFL. This work establishes rubrics as a powerful tool for both training and evaluating advanced IF in LLMs, paving the way for more capable and reliable AI systems.
LlamaRL: A Distributed Asynchronous Reinforcement Learning Framework for Efficient Large-scale LLM Trainin
May 29, 2025Reinforcement Learning (RL) has become the most effective post-training approach for improving the capabilities of Large Language Models (LLMs). In practice, because of the high demands on latency and memory, it is particularly challenging to develop an efficient RL framework that reliably manages policy models with hundreds to thousands of billions of parameters. In this paper, we present LlamaRL, a fully distributed, asynchronous RL framework optimized for efficient training of large-scale LLMs with various model sizes (8B, 70B, and 405B parameters) on GPU clusters ranging from a handful to thousands of devices. LlamaRL introduces a streamlined, single-controller architecture built entirely on native PyTorch, enabling modularity, ease of use, and seamless scalability to thousands of GPUs. We also provide a theoretical analysis of LlamaRL's efficiency, including a formal proof that its asynchronous design leads to strict RL speed-up. Empirically, by leveraging best practices such as colocated model offloading, asynchronous off-policy training, and distributed direct memory access for weight synchronization, LlamaRL achieves significant efficiency gains -- up to 10.7x speed-up compared to DeepSpeed-Chat-like systems on a 405B-parameter policy model. Furthermore, the efficiency advantage continues to grow with increasing model scale, demonstrating the framework's suitability for future large-scale RL training.
Self-Generated Critiques Boost Reward Modeling for Language Models
Nov 25, 2024



Reward modeling is crucial for aligning large language models (LLMs) with human preferences, especially in reinforcement learning from human feedback (RLHF). However, current reward models mainly produce scalar scores and struggle to incorporate critiques in a natural language format. We hypothesize that predicting both critiques and the scalar reward would improve reward modeling ability. Motivated by this, we propose Critic-RM, a framework that improves reward models using self-generated critiques without extra supervision. Critic-RM employs a two-stage process: generating and filtering high-quality critiques, followed by joint fine-tuning on reward prediction and critique generation. Experiments across benchmarks show that Critic-RM improves reward modeling accuracy by 3.7%-7.3% compared to standard reward models and LLM judges, demonstrating strong performance and data efficiency. Additional studies further validate the effectiveness of generated critiques in rectifying flawed reasoning steps with 2.5%-3.2% gains in improving reasoning accuracy.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
Dec 22, 2023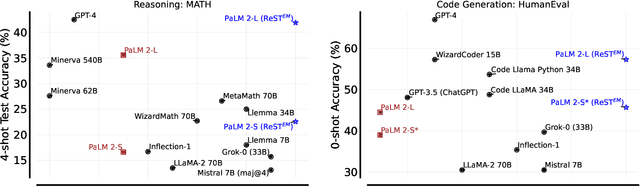
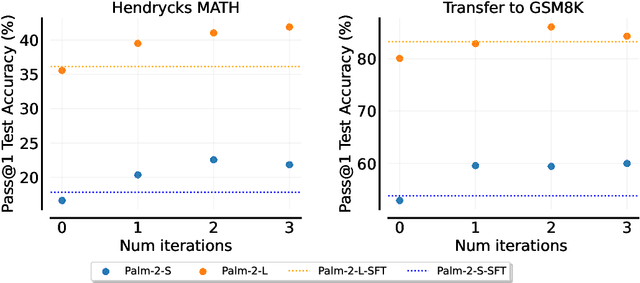
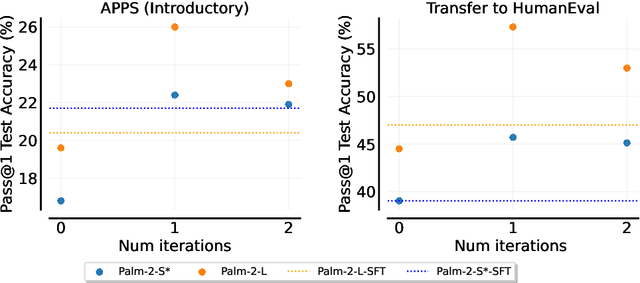
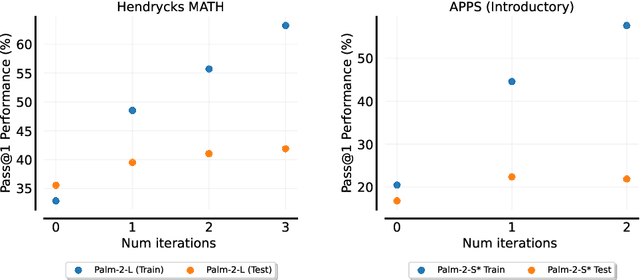
Fine-tuning language models~(LMs) on human-generated data remains a prevalent practice. However, the performance of such models is often limited by the quantity and diversity of high-quality human data. In this paper, we explore whether we can go beyond human data on tasks where we have access to scalar feedback, for example, on math problems where one can verify correctness. To do so, we investigate a simple self-training method based on expectation-maximization, which we call ReST$^{EM}$, where we (1) generate samples from the model and filter them using binary feedback, (2) fine-tune the model on these samples, and (3) repeat this process a few times. Testing on advanced MATH reasoning and APPS coding benchmarks using PaLM-2 models, we find that ReST$^{EM}$ scales favorably with model size and significantly surpasses fine-tuning only on human data. Overall, our findings suggest self-training with feedback can substantially reduce dependence on human-generated data.
Frontier Language Models are not Robust to Adversarial Arithmetic, or "What do I need to say so you agree 2+2=5?
Nov 15, 2023



We introduce and study the problem of adversarial arithmetic, which provides a simple yet challenging testbed for language model alignment. This problem is comprised of arithmetic questions posed in natural language, with an arbitrary adversarial string inserted before the question is complete. Even in the simple setting of 1-digit addition problems, it is easy to find adversarial prompts that make all tested models (including PaLM2, GPT4, Claude2) misbehave, and even to steer models to a particular wrong answer. We additionally provide a simple algorithm for finding successful attacks by querying those same models, which we name "prompt inversion rejection sampling" (PIRS). We finally show that models can be partially hardened against these attacks via reinforcement learning and via agentic constitutional loops. However, we were not able to make a language model fully robust against adversarial arithmetic attacks.
MLGO: a Machine Learning Guided Compiler Optimizations Framework
Jan 13, 2021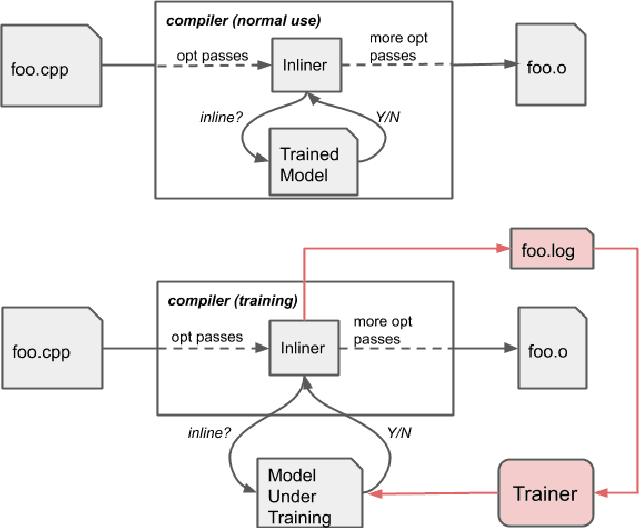
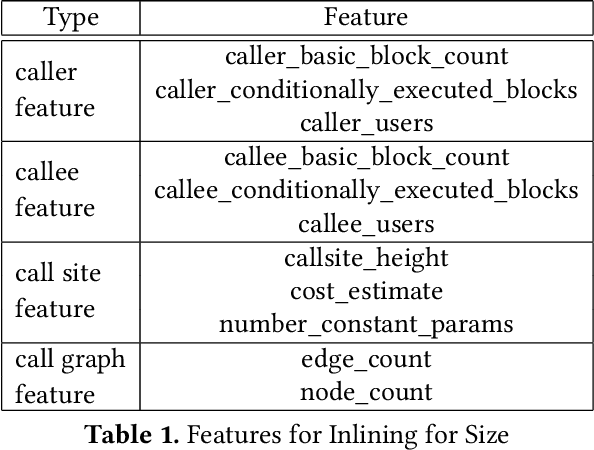
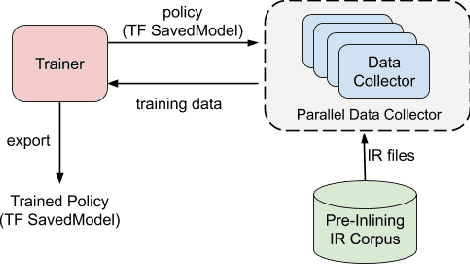
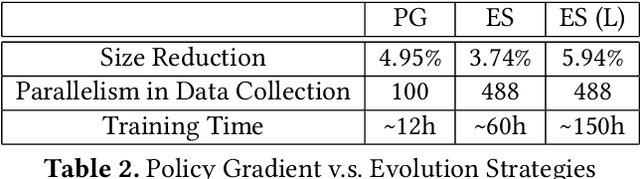
Leveraging machine-learning (ML) techniques for compiler optimizations has been widely studied and explored in academia. However, the adoption of ML in general-purpose, industry strength compilers has yet to happen. We propose MLGO, a framework for integrating ML techniques systematically in an industrial compiler -- LLVM. As a case study, we present the details and results of replacing the heuristics-based inlining-for-size optimization in LLVM with machine learned models. To the best of our knowledge, this work is the first full integration of ML in a complex compiler pass in a real-world setting. It is available in the main LLVM repository. We use two different ML algorithms: Policy Gradient and Evolution Strategies, to train the inlining-for-size model, and achieve up to 7\% size reduction, when compared to state of the art LLVM -Oz. The same model, trained on one corpus, generalizes well to a diversity of real-world targets, as well as to the same set of targets after months of active development. This property of the trained models is beneficial to deploy ML techniques in real-world settings.