 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2AL: Cohort-Contrastive Auxiliary Learning for Large-scale Recommendation Systems
Oct 02, 2025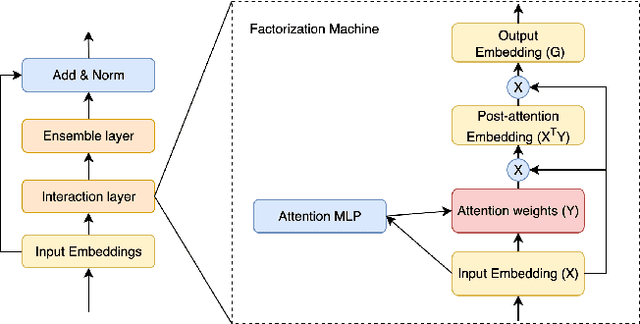
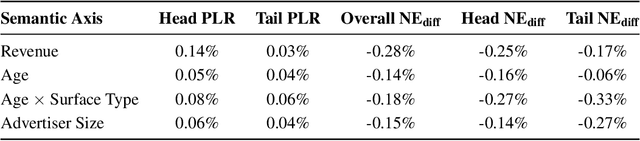
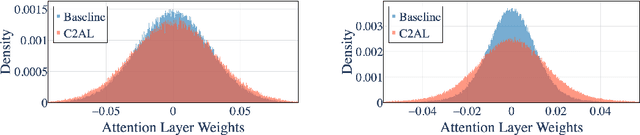

Training large-scale recommendation models under a single global objective implicitly assumes homogeneity across user populations. However, real-world data are composites of heterogeneous cohorts with distinct conditional distributions. As models increase in scale and complexity and as more data is used for training, they become dominated by central distribution patterns, neglecting head and tail regions. This imbalance limits the model's learning ability and can result in inactive attention weights or dead neurons. In this paper, we reveal how the attention mechanism can play a key role in factorization machines for shared embedding selection, and propose to address this challenge by analyzing the substructures in the dataset and exposing those with strong distributional contrast through auxiliary learning. Unlike previous research, which heuristically applies weighted labels or multi-task heads to mitigate such biases, we leverage partially conflicting auxiliary labels to regularize the shared representation. This approach customizes the learning process of attention layers to preserve mutual information with minority cohorts while improving global performance. We evaluated C2AL on massive production datasets with billions of data points each for six SOTA models. Experiments show that the factorization machine is able to capture fine-grained user-ad interactions using the proposed method, achieving up to a 0.16% reduction in normalized entropy overall and delivering gains exceeding 0.30% on targeted minority cohorts.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
Personalized Interpolation: An Efficient Method to Tame Flexible Optimization Window Estimation
Jan 23, 2025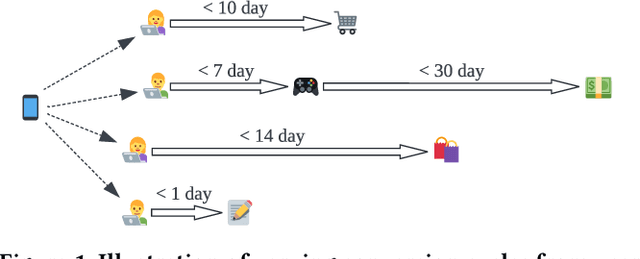
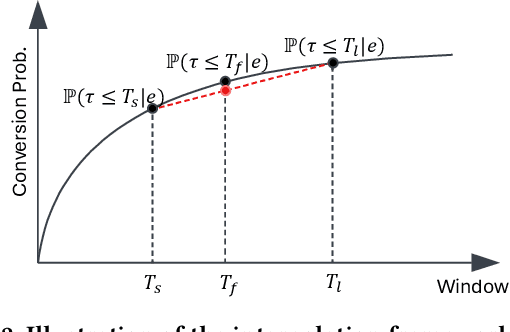
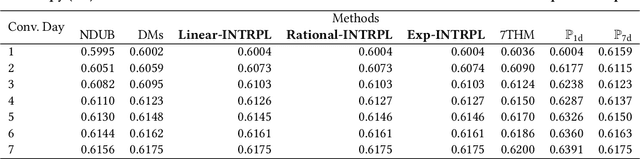
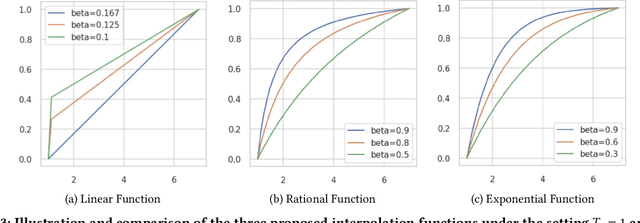
In the realm of online advertising, optimizing conversions is crucial for delivering relevant products to users and enhancing business outcomes. Predicting conversion events is challenging due to variable delays between user interactions, such as impressions or clicks, and the actual conversions. These delays differ significantly across various advertisers and products, necessitating distinct optimization time windows for targeted conversions. To address this, we introduce a novel approach named the \textit{Personalized Interpolation} method, which innovatively builds upon existing fixed conversion window models to estimate flexible conversion windows. This method allows for the accurate estimation of conversions across a variety of delay ranges, thus meeting the diverse needs of advertisers without increasing system complexity. To validate the efficacy of our proposed method, we conducted comprehensive experiments using ads conversion model. Our experiments demonstrate that this method not only achieves high prediction accuracy but also does so more efficiently than other existing solutions. This validation underscores the potential of our Personalized Interpolation method to significantly enhance conversion optimization in real-world online advertising systems, promising improved targeting and effectiveness in advertising strategies.
Towards the Better Ranking Consistency: A Multi-task Learning Framework for Early Stage Ads Ranking
Jul 12, 2023



Dividing ads ranking system into retrieval, early, and final stages is a common practice in large scale ads recommendation to balance the efficiency and accuracy. The early stage ranking often uses efficient models to generate candidates out of a set of retrieved ads. The candidates are then fed into a more computationally intensive but accurate final stage ranking system to produce the final ads recommendation. As the early and final stage ranking use different features and model architectures because of system constraints, a serious ranking consistency issue arises where the early stage has a low ads recall, i.e., top ads in the final stage are ranked low in the early stage. In order to pass better ads from the early to the final stage ranking, we propose a multi-task learning framework for early stage ranking to capture multiple final stage ranking components (i.e. ads clicks and ads quality events) and their task relations. With our multi-task learning framework, we can not only achieve serving cost saving from the model consolidation, but also improve the ads recall and ranking consistency. In the online A/B testing, our framework achieves significantly higher click-through rate (CTR), conversion rate (CVR), total value and better ads-quality (e.g. reduced ads cross-out rate) in a large scale industrial ads ranking system.
DHEN: A Deep and Hierarchical Ensemble Network for Large-Scale Click-Through Rate Prediction
Mar 11, 2022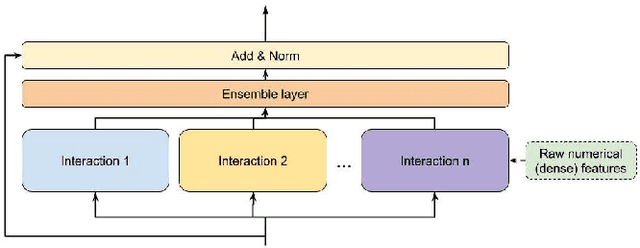
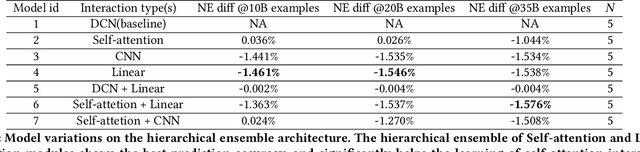
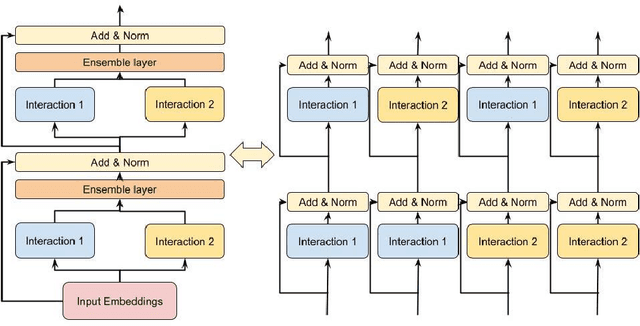

Learning feature interactions is important to the model performance of online advertising services. As a result, extensive efforts have been devoted to designing effective architectures to learn feature interactions. However, we observe that the practical performance of those designs can vary from dataset to dataset, even when the order of interactions claimed to be captured is the same. That indicates different designs may have different advantages and the interactions captured by them have non-overlapping information. Motivated by this observation, we propose DHEN - a deep and hierarchical ensemble architecture that can leverage strengths of heterogeneous interaction modules and learn a hierarchy of the interactions under different orders. To overcome the challenge brought by DHEN's deeper and multi-layer structure in training, we propose a novel co-designed training system that can further improve the training efficiency of DHEN. Experiments of DHEN on large-scale dataset from CTR prediction tasks attained 0.27\% improvement on the Normalized Entropy (NE) of prediction and 1.2x better training throughput than state-of-the-art baseline, demonstrating their effectiveness in practice.
Low-Precision Hardware Architectures Meet Recommendation Model Inference at Scale
May 26, 2021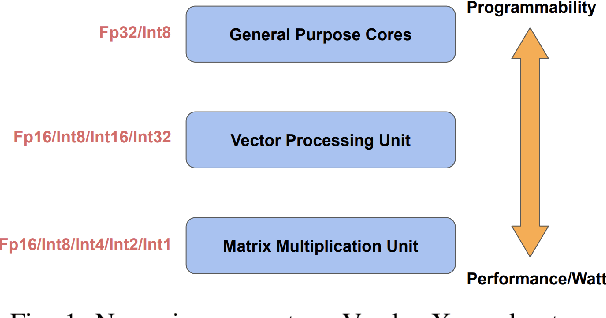
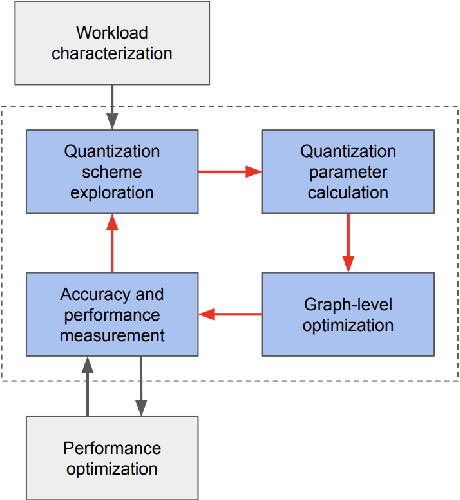
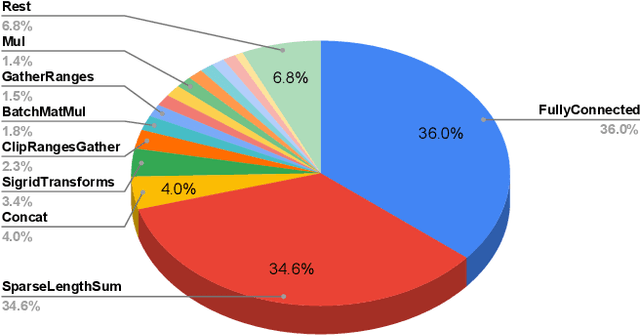
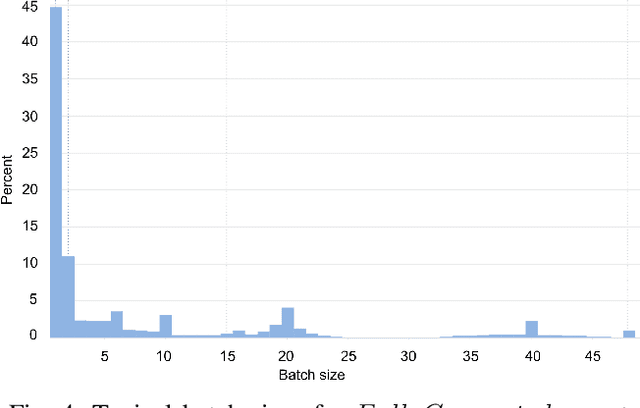
Tremendous success of machine learning (ML) and the unabated growth in ML model complexity motivated many ML-specific designs in both CPU and accelerator architectures to speed up the model inference. While these architectures are diverse, highly optimized low-precision arithmetic is a component shared by most. Impressive compute throughputs are indeed often exhibited by these architectures on benchmark ML models. Nevertheless, production models such as recommendation systems important to Facebook's personalization services are demanding and complex: These systems must serve billions of users per month responsively with low latency while maintaining high prediction accuracy, notwithstanding computations with many tens of billions parameters per inference. Do these low-precision architectures work well with our production recommendation systems? They do. But not without significant effort. We share in this paper our search strategies to adapt reference recommendation models to low-precision hardware, our optimization of low-precision compute kernels, and the design and development of tool chain so as to maintain our models' accuracy throughout their lifespan during which topic trends and users' interests inevitably evolve. Practicing these low-precision technologies helped us save datacenter capacities while deploying models with up to 5X complexity that would otherwise not be deployed on traditional general-purpose CPUs. We believe these lessons from the trenches promote better co-design between hardware architecture and software engineering and advance the state of the art of ML in industry.
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 15, 2021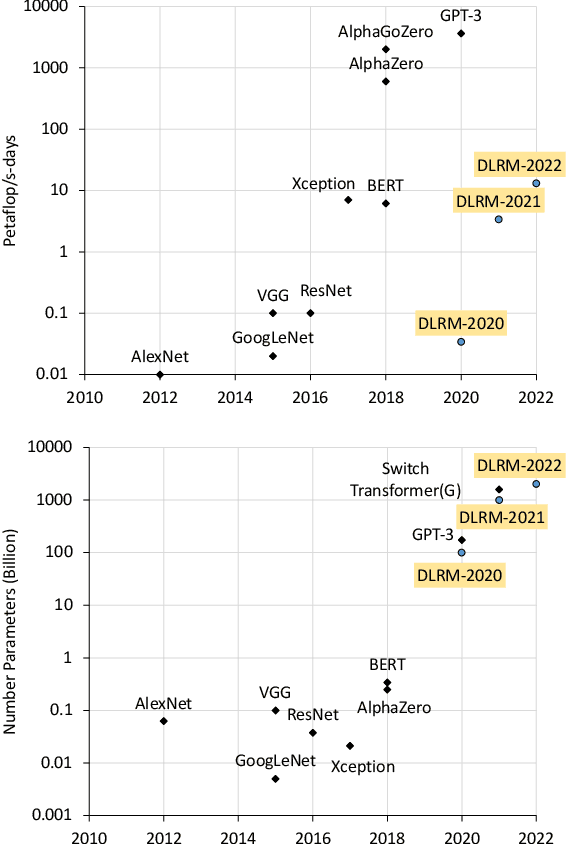

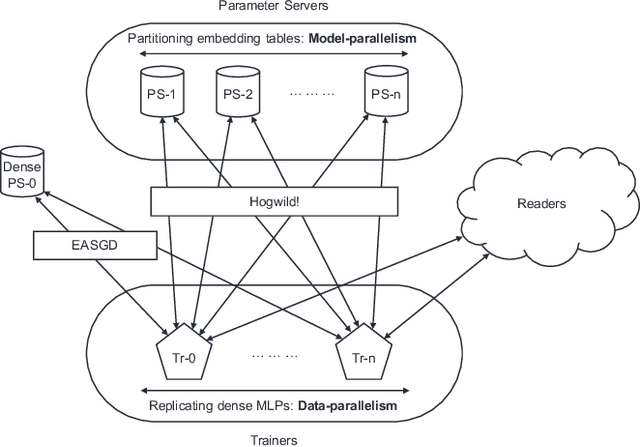
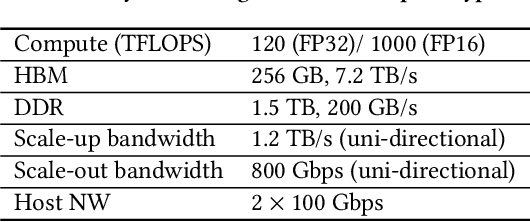
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of Zion platform, namely ZionEX. We demonstrate the capability to train very large DLRMs with up to 12 Trillion parameters and show that we can attain 40X speedup in terms of time to solution over previous systems. We achieve this by (i) designing the ZionEX platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.
Adaptive Dense-to-Sparse Paradigm for Pruning Online Recommendation System with Non-Stationary Data
Oct 21, 2020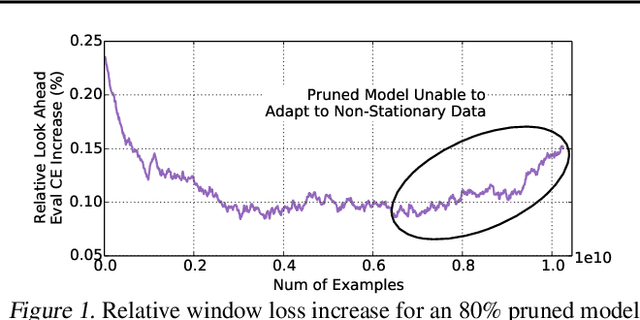
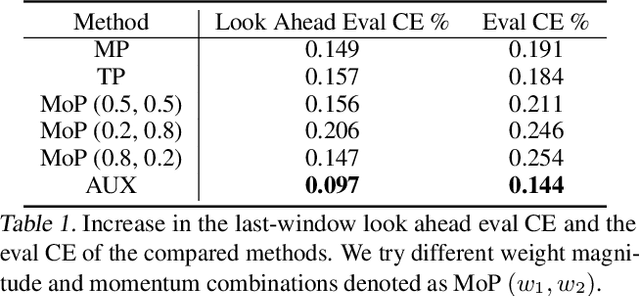
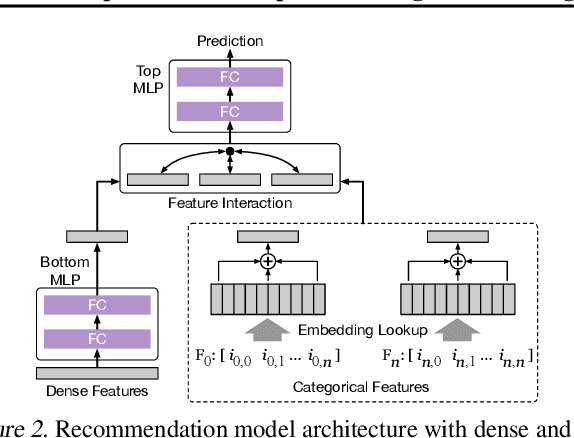
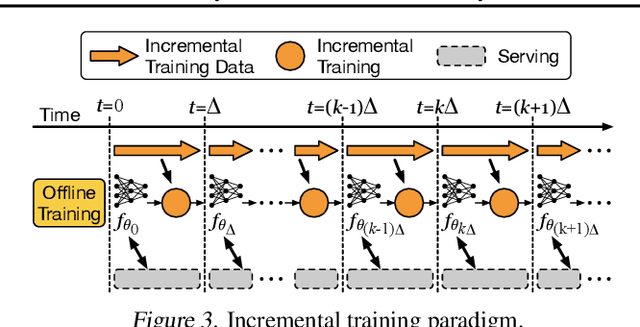
Large scale deep learning provides a tremendous opportunity to improve the quality of content recommendation systems by employing both wider and deeper models, but this comes at great infrastructural cost and carbon footprint in modern data centers. Pruning is an effective technique that reduces both memory and compute demand for model inference. However, pruning for online recommendation systems is challenging due to the continuous data distribution shift (a.k.a non-stationary data). Although incremental training on the full model is able to adapt to the non-stationary data, directly applying it on the pruned model leads to accuracy loss. This is because the sparsity pattern after pruning requires adjustment to learn new patterns. To the best of our knowledge, this is the first work to provide in-depth analysis and discussion of applying pruning to online recommendation systems with non-stationary data distribution. Overall, this work makes the following contributions: 1) We present an adaptive dense to sparse paradigm equipped with a novel pruning algorithm for pruning a large scale recommendation system with non-stationary data distribution; 2) We design the pruning algorithm to automatically learn the sparsity across layers to avoid repeating hand-tuning, which is critical for pruning the heterogeneous architectures of recommendation systems trained with non-stationary data.