 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Multi-View Learning with Conformal Prediction for Aortic Stenosis Classification in Echocardiography
Sep 15, 2024The fundamental problem with ultrasound-guided diagnosis is that the acquired images are often 2-D cross-sections of a 3-D anatomy, potentially missing important anatomical details. This limitation leads to challenges in ultrasound echocardiography, such as poor visualization of heart valves or foreshortening of ventricles. Clinicians must interpret these images with inherent uncertainty, a nuance absent in machine learning's one-hot labels. We propose Re-Training for Uncertainty (RT4U), a data-centric method to introduce uncertainty to weakly informative inputs in the training set. This simple approach can be incorporated to existing state-of-the-art aortic stenosis classification methods to further improve their accuracy. When combined with conformal prediction techniques, RT4U can yield adaptively sized prediction sets which are guaranteed to contain the ground truth class to a high accuracy. We validate the effectiveness of RT4U on three diverse datasets: a public (TMED-2) and a private AS dataset, along with a CIFAR-10-derived toy dataset. Results show improvement on all the datasets.
Disaggregated Multi-Tower: Topology-aware Modeling Technique for Efficient Large-Scale Recommendation
Mar 07, 2024



We study a mismatch between the deep learning recommendation models' flat architecture, common distributed training paradigm and hierarchical data center topology. To address the associated inefficiencies, we propose Disaggregated Multi-Tower (DMT), a modeling technique that consists of (1) Semantic-preserving Tower Transform (SPTT), a novel training paradigm that decomposes the monolithic global embedding lookup process into disjoint towers to exploit data center locality; (2) Tower Module (TM), a synergistic dense component attached to each tower to reduce model complexity and communication volume through hierarchical feature interaction; and (3) Tower Partitioner (TP), a feature partitioner to systematically create towers with meaningful feature interactions and load balanced assignments to preserve model quality and training throughput via learned embeddings. We show that DMT can achieve up to 1.9x speedup compared to the state-of-the-art baselines without losing accuracy across multiple generations of hardware at large data center scales.
DHEN: A Deep and Hierarchical Ensemble Network for Large-Scale Click-Through Rate Prediction
Mar 11, 2022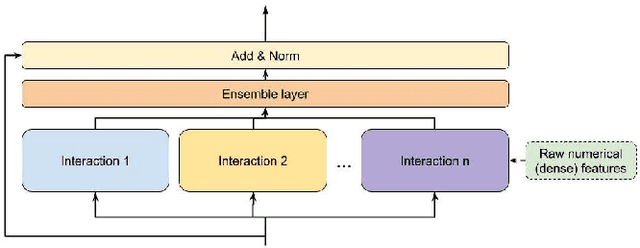
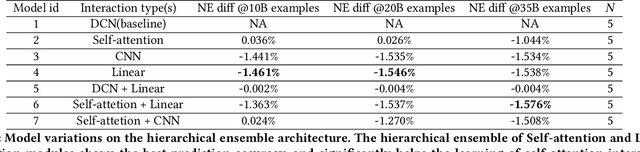
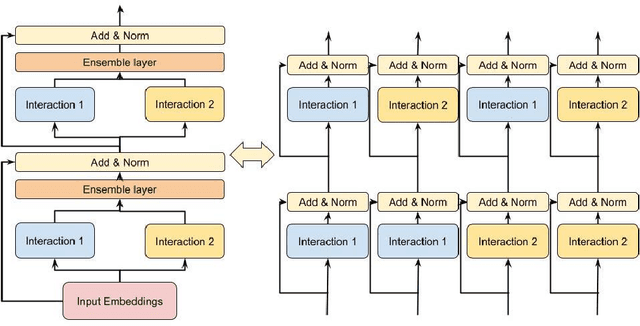

Learning feature interactions is important to the model performance of online advertising services. As a result, extensive efforts have been devoted to designing effective architectures to learn feature interactions. However, we observe that the practical performance of those designs can vary from dataset to dataset, even when the order of interactions claimed to be captured is the same. That indicates different designs may have different advantages and the interactions captured by them have non-overlapping information. Motivated by this observation, we propose DHEN - a deep and hierarchical ensemble architecture that can leverage strengths of heterogeneous interaction modules and learn a hierarchy of the interactions under different orders. To overcome the challenge brought by DHEN's deeper and multi-layer structure in training, we propose a novel co-designed training system that can further improve the training efficiency of DHEN. Experiments of DHEN on large-scale dataset from CTR prediction tasks attained 0.27\% improvement on the Normalized Entropy (NE) of prediction and 1.2x better training throughput than state-of-the-art baseline, demonstrating their effectiveness in practice.
Interpretable Artificial Intelligence through the Lens of Feature Interaction
Mar 01, 2021
Interpretation of deep learning models is a very challenging problem because of their large number of parameters, complex connections between nodes, and unintelligible feature representations. Despite this, many view interpretability as a key solution to trustworthiness, fairness, and safety, especially as deep learning is applied to more critical decision tasks like credit approval, job screening, and recidivism prediction. There is an abundance of good research providing interpretability to deep learning models; however, many of the commonly used methods do not consider a phenomenon called "feature interaction." This work first explains the historical and modern importance of feature interactions and then surveys the modern interpretability methods which do explicitly consider feature interactions. This survey aims to bring to light the importance of feature interactions in the larger context of machine learning interpretability, especially in a modern context where deep learning models heavily rely on feature interactions.
U-LanD: Uncertainty-Driven Video Landmark Detection
Feb 02, 2021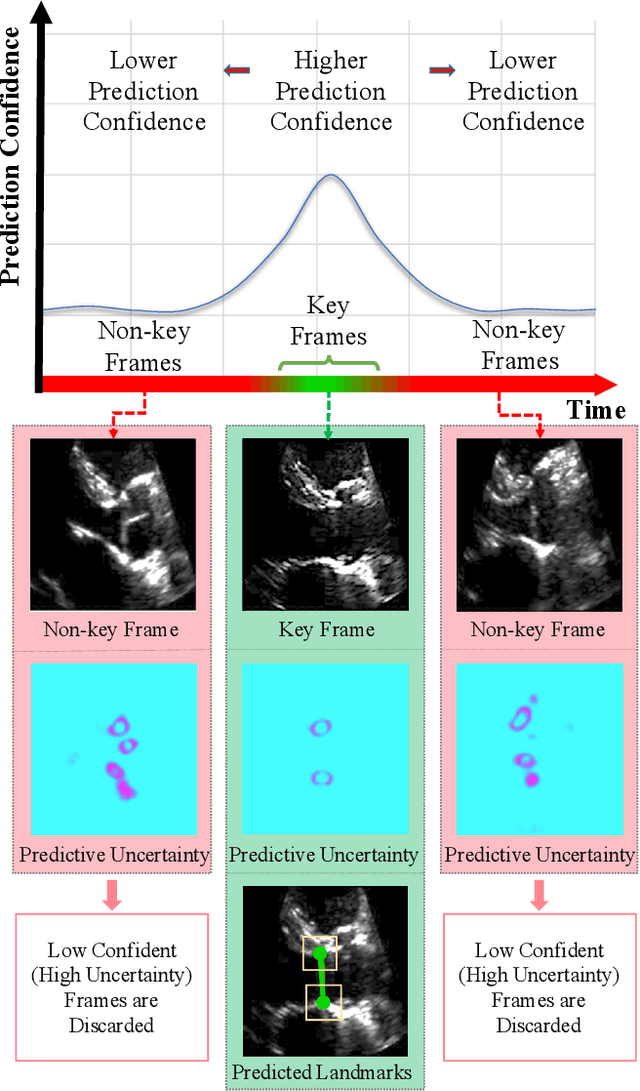
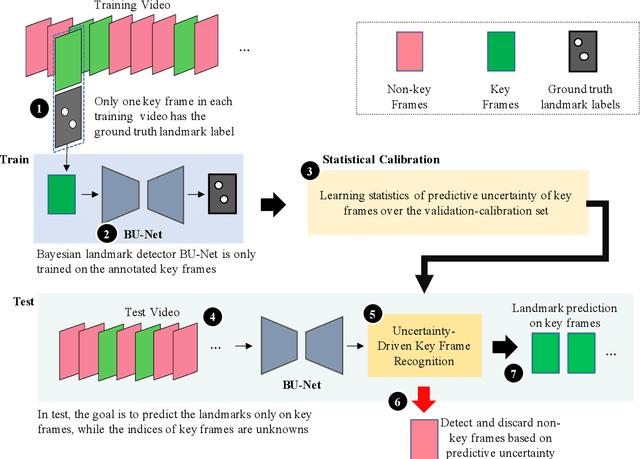
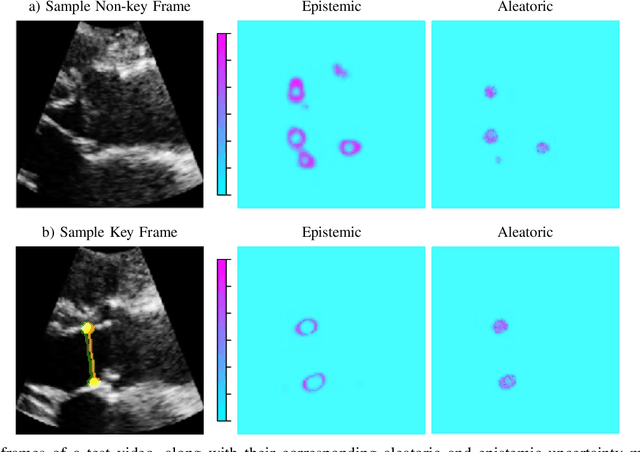
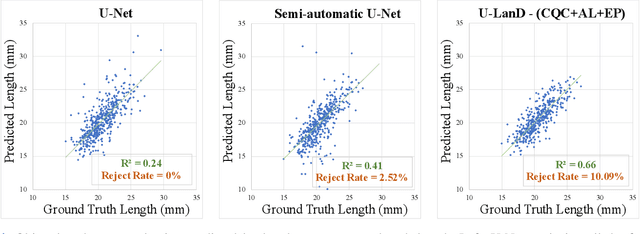
This paper presents U-LanD, a framework for joint detection of key frames and landmarks in videos. We tackle a specifically challenging problem, where training labels are noisy and highly sparse. U-LanD builds upon a pivotal observation: a deep Bayesian landmark detector solely trained on key video frames, has significantly lower predictive uncertainty on those frames vs. other frames in videos. We use this observation as an unsupervised signal to automatically recognize key frames on which we detect landmarks. As a test-bed for our framework, we use ultrasound imaging videos of the heart, where sparse and noisy clinical labels are only available for a single frame in each video. Using data from 4,493 patients, we demonstrate that U-LanD can exceedingly outperform the state-of-the-art non-Bayesian counterpart by a noticeable absolute margin of 42% in R2 score, with almost no overhead imposed on the model size. Our approach is generic and can be potentially applied to other challenging data with noisy and sparse training labels.
Interpretable Deepfake Detection via Dynamic Prototypes
Jun 28, 2020


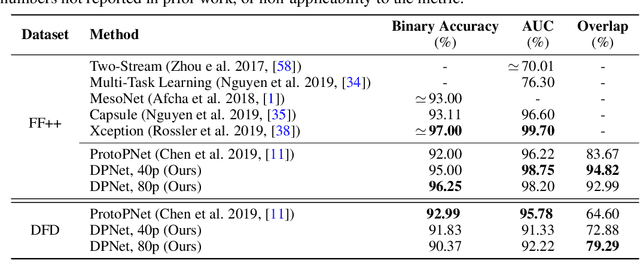
Deepfake is one notorious application of deep learning research, leading to massive amounts of video content on social media ridden with malicious intent. Therefore detecting deepfake videos has emerged as one of the most pressing challenges in AI research. Most state-of-the-art deepfake solutions are based on black-box models that process videos frame-by-frame for inference, and they do not consider temporal dynamics, which are key for detecting and explaining deepfake videos by humans. To this end, we propose Dynamic Prototype Network (DPNet) - a simple, interpretable, yet effective solution that leverages dynamic representations (i.e., prototypes) to explain deepfake visual dynamics. Experiment results show that the explanations of DPNet provide better overlap with the ground truth than state-of-the-art methods with comparable prediction performance. Furthermore, we formulate temporal logic specifications based on these prototypes to check the compliance of our model to desired temporal behaviors.
Feature Interaction Interpretability: A Case for Explaining Ad-Recommendation Systems via Neural Interaction Detection
Jun 19, 2020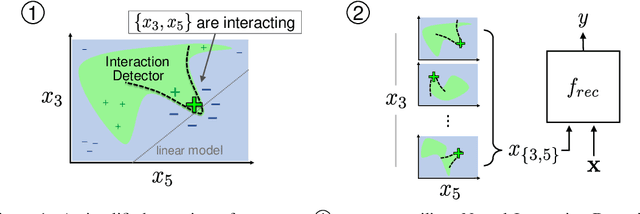


Recommendation is a prevalent application of machine learning that affects many users; therefore, it is important for recommender models to be accurate and interpretable. In this work, we propose a method to both interpret and augment the predictions of black-box recommender systems. In particular, we propose to interpret feature interactions from a source recommender model and explicitly encode these interactions in a target recommender model, where both source and target models are black-boxes. By not assuming the structure of the recommender system, our approach can be used in general settings. In our experiments, we focus on a prominent use of machine learning recommendation: ad-click prediction. We found that our interaction interpretations are both informative and predictive, e.g., significantly outperforming existing recommender models. What's more, the same approach to interpret interactions can provide new insights into domains even beyond recommendation, such as text and image classification.
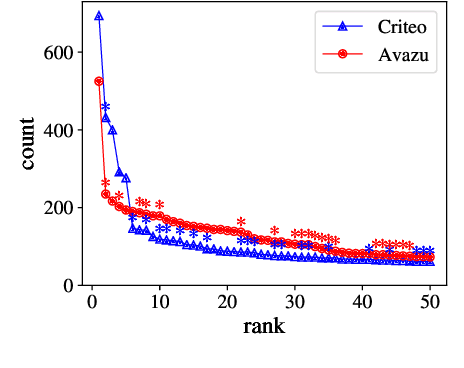
How does this interaction affect me? Interpretable attribution for feature interactions
Jun 19, 2020

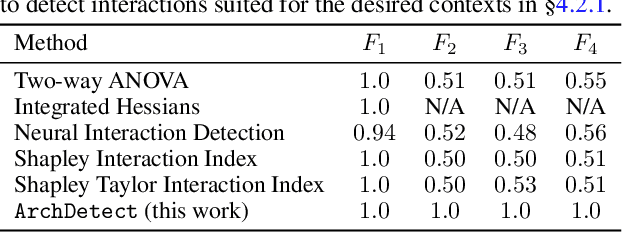

Machine learning transparency calls for interpretable explanations of how inputs relate to predictions. Feature attribution is a way to analyze the impact of features on predictions. Feature interactions are the contextual dependence between features that jointly impact predictions. There are a number of methods that extract feature interactions in prediction models; however, the methods that assign attributions to interactions are either uninterpretable, model-specific, or non-axiomatic. We propose an interaction attribution and detection framework called Archipelago which addresses these problems and is also scalable in real-world settings. Our experiments on standard annotation labels indicate our approach provides significantly more interpretable explanations than comparable methods, which is important for analyzing the impact of interactions on predictions. We also provide accompanying visualizations of our approach that give new insights into deep neural networks.
Extracting Interpretable Concept-Based Decision Trees from CNNs
Jun 16, 2019
In an attempt to gather a deeper understanding of how convolutional neural networks (CNNs) reason about human-understandable concepts, we present a method to infer labeled concept data from hidden layer activations and interpret the concepts through a shallow decision tree. The decision tree can provide information about which concepts a model deems important, as well as provide an understanding of how the concepts interact with each other. Experiments demonstrate that the extracted decision tree is capable of accurately representing the original CNN's classifications at low tree depths, thus encouraging human-in-the-loop understanding of discriminative concepts.
Can I trust you more? Model-Agnostic Hierarchical Explanations
Dec 12, 2018
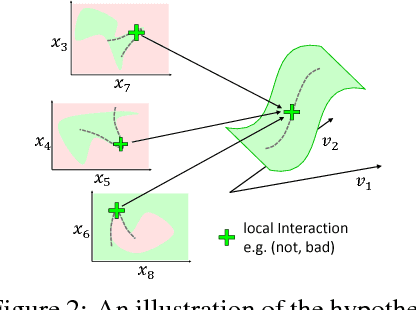
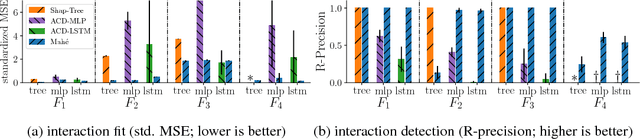

Interactions such as double negation in sentences and scene interactions in images are common forms of complex dependencies captured by state-of-the-art machine learning models. We propose Mah\'e, a novel approach to provide Model-agnostic hierarchical \'explanations of how powerful machine learning models, such as deep neural networks, capture these interactions as either dependent on or free of the context of data instances. Specifically, Mah\'e provides context-dependent explanations by a novel local interpretation algorithm that effectively captures any-order interactions, and obtains context-free explanations through generalizing context-dependent interactions to explain global behaviors. Experimental results show that Mah\'e obtains improved local interaction interpretations over state-of-the-art methods and successfully explains interactions that are context-free.