 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-LanD: Uncertainty-Driven Video Landmark Detection
Feb 02, 2021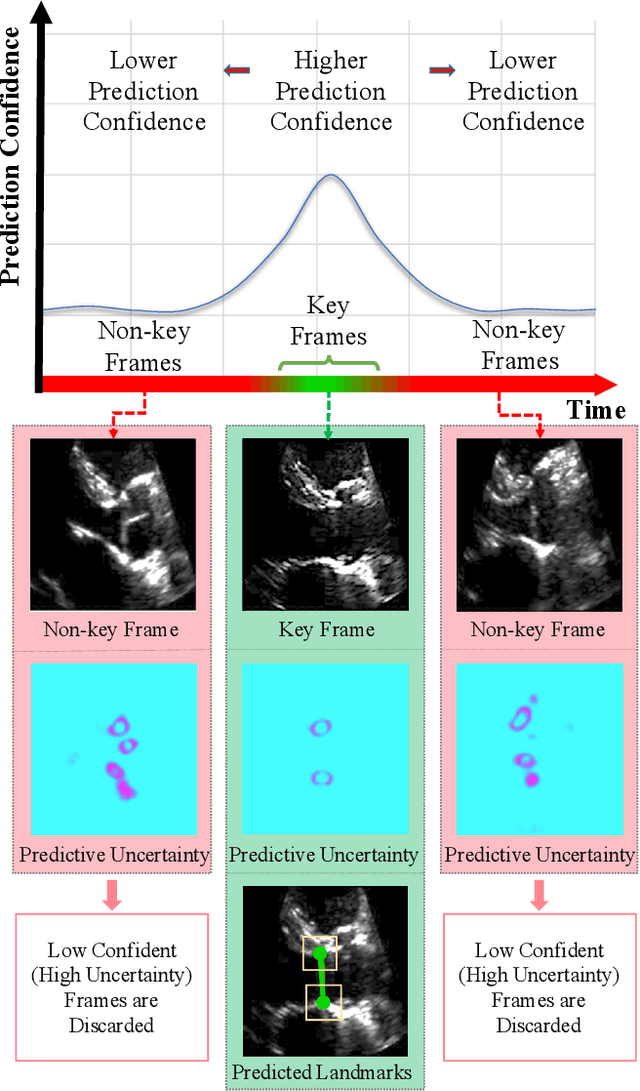
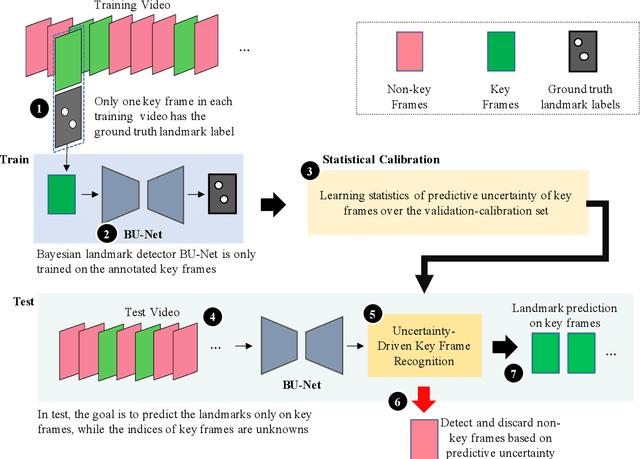
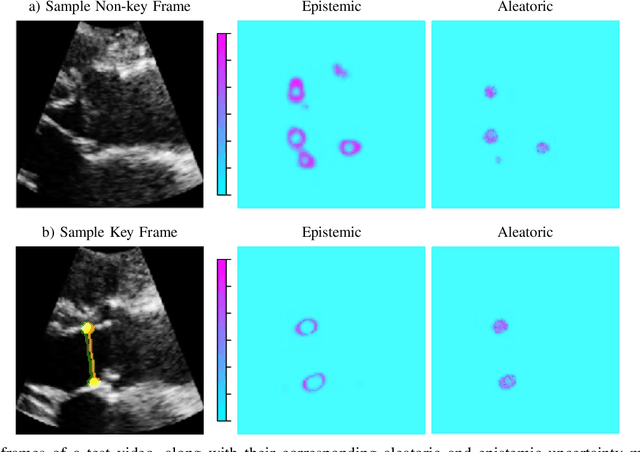
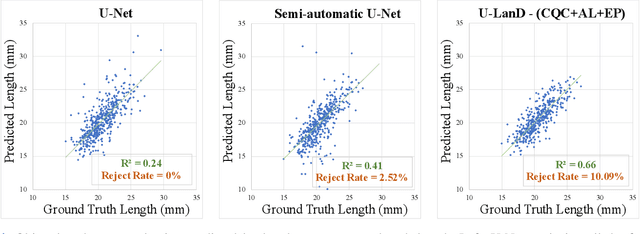
This paper presents U-LanD, a framework for joint detection of key frames and landmarks in videos. We tackle a specifically challenging problem, where training labels are noisy and highly sparse. U-LanD builds upon a pivotal observation: a deep Bayesian landmark detector solely trained on key video frames, has significantly lower predictive uncertainty on those frames vs. other frames in videos. We use this observation as an unsupervised signal to automatically recognize key frames on which we detect landmarks. As a test-bed for our framework, we use ultrasound imaging videos of the heart, where sparse and noisy clinical labels are only available for a single frame in each video. Using data from 4,493 patients, we demonstrate that U-LanD can exceedingly outperform the state-of-the-art non-Bayesian counterpart by a noticeable absolute margin of 42% in R2 score, with almost no overhead imposed on the model size. Our approach is generic and can be potentially applied to other challenging data with noisy and sparse training labels.