 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Out-of-Context Multimodal Misinformation with interpretable neural-symbolic model
Apr 15, 2023Recent years have witnessed the sustained evolution of misinformation that aims at manipulating public opinions. Unlike traditional rumors or fake news editors who mainly rely on generated and/or counterfeited images, text and videos, current misinformation creators now more tend to use out-of-context multimedia contents (e.g. mismatched images and captions) to deceive the public and fake news detection systems. This new type of misinformation increases the difficulty of not only detection but also clarification, because every individual modality is close enough to true information. To address this challenge, in this paper we explore how to achieve interpretable cross-modal de-contextualization detection that simultaneously identifies the mismatched pairs and the cross-modal contradictions, which is helpful for fact-check websites to document clarifications. The proposed model first symbolically disassembles the text-modality information to a set of fact queries based on the Abstract Meaning Representation of the caption and then forwards the query-image pairs into a pre-trained large vision-language model select the ``evidences" that are helpful for us to detect misinformation. Extensive experiments indicate that the proposed methodology can provide us with much more interpretable predictions while maintaining the accuracy same as the state-of-the-art model on this task.
DSLOB: A Synthetic Limit Order Book Dataset for Benchmarking Forecasting Algorithms under Distributional Shift
Nov 17, 2022In electronic trading markets, limit order books (LOBs) provide information about pending buy/sell orders at various price levels for a given security. Recently, there has been a growing interest in using LOB data for resolving downstream machine learning tasks (e.g., forecasting). However, dealing with out-of-distribution (OOD) LOB data is challenging since distributional shifts are unlabeled in current publicly available LOB datasets. Therefore, it is critical to build a synthetic LOB dataset with labeled OOD samples serving as a testbed for developing models that generalize well to unseen scenarios. In this work, we utilize a multi-agent market simulator to build a synthetic LOB dataset, named DSLOB, with and without market stress scenarios, which allows for the design of controlled distributional shift benchmarking. Using the proposed synthetic dataset, we provide a holistic analysis on the forecasting performance of three different state-of-the-art forecasting methods. Our results reflect the need for increased researcher efforts to develop algorithms with robustness to distributional shifts in high-frequency time series data.
PSML: A Multi-scale Time-series Dataset for Machine Learning in Decarbonized Energy Grids
Oct 12, 2021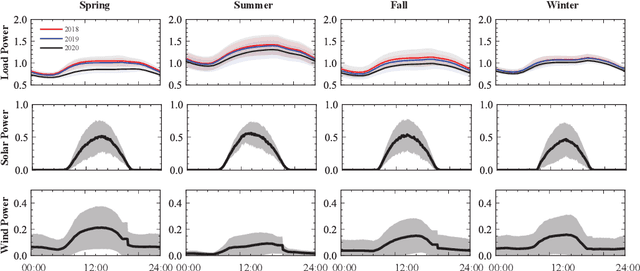
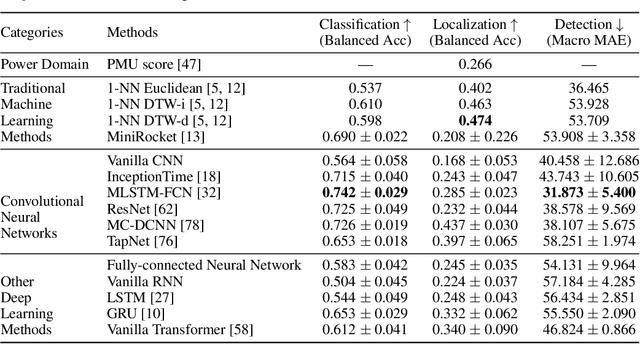
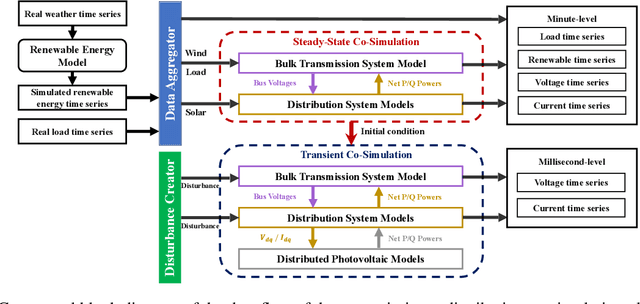
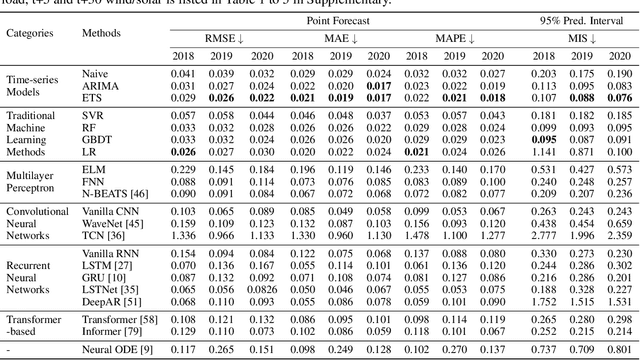
The electric grid is a key enabling infrastructure for the ambitious transition towards carbon neutrality as we grapple with climate change. With deepening penetration of renewable energy resources and electrified transportation, the reliable and secure operation of the electric grid becomes increasingly challenging. In this paper, we present PSML, a first-of-its-kind open-access multi-scale time-series dataset, to aid in the development of data-driven machine learning (ML) based approaches towards reliable operation of future electric grids. The dataset is generated through a novel transmission + distribution (T+D) co-simulation designed to capture the increasingly important interactions and uncertainties of the grid dynamics, containing electric load, renewable generation, weather, voltage and current measurements at multiple spatio-temporal scales. Using PSML, we provide state-of-the-art ML baselines on three challenging use cases of critical importance to achieve: (i) early detection, accurate classification and localization of dynamic disturbance events; (ii) robust hierarchical forecasting of load and renewable energy with the presence of uncertainties and extreme events; and (iii) realistic synthetic generation of physical-law-constrained measurement time series. We envision that this dataset will enable advances for ML in dynamic systems, while simultaneously allowing ML researchers to contribute towards carbon-neutral electricity and mobility.
An Examination of Fairness of AI Models for Deepfake Detection
May 02, 2021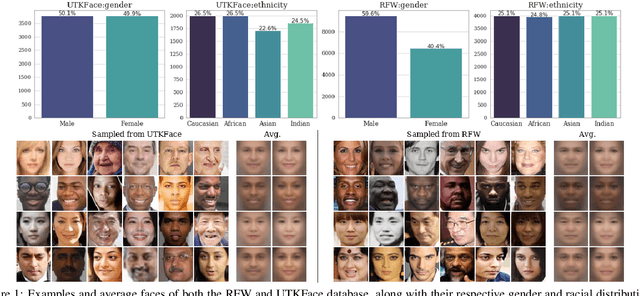


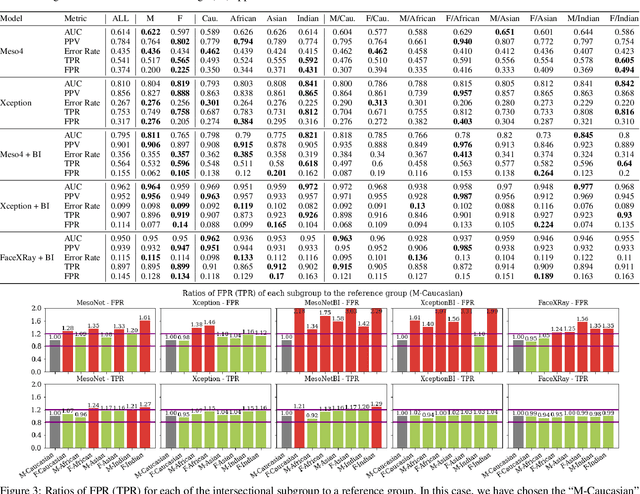
Recent studies have demonstrated that deep learning models can discriminate based on protected classes like race and gender. In this work, we evaluate bias present in deepfake datasets and detection models across protected subgroups. Using facial datasets balanced by race and gender, we examine three popular deepfake detectors and find large disparities in predictive performances across races, with up to 10.7% difference in error rate between subgroups. A closer look reveals that the widely used FaceForensics++ dataset is overwhelmingly composed of Caucasian subjects, with the majority being female Caucasians. Our investigation of the racial distribution of deepfakes reveals that the methods used to create deepfakes as positive training signals tend to produce "irregular" faces - when a person's face is swapped onto another person of a different race or gender. This causes detectors to learn spurious correlations between the foreground faces and fakeness. Moreover, when detectors are trained with the Blended Image (BI) dataset from Face X-Rays, we find that those detectors develop systematic discrimination towards certain racial subgroups, primarily female Asians.
MIMIC-IF: Interpretability and Fairness Evaluation of Deep Learning Models on MIMIC-IV Dataset
Feb 12, 2021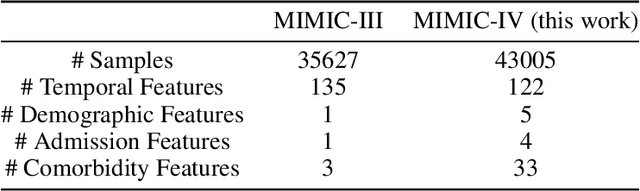
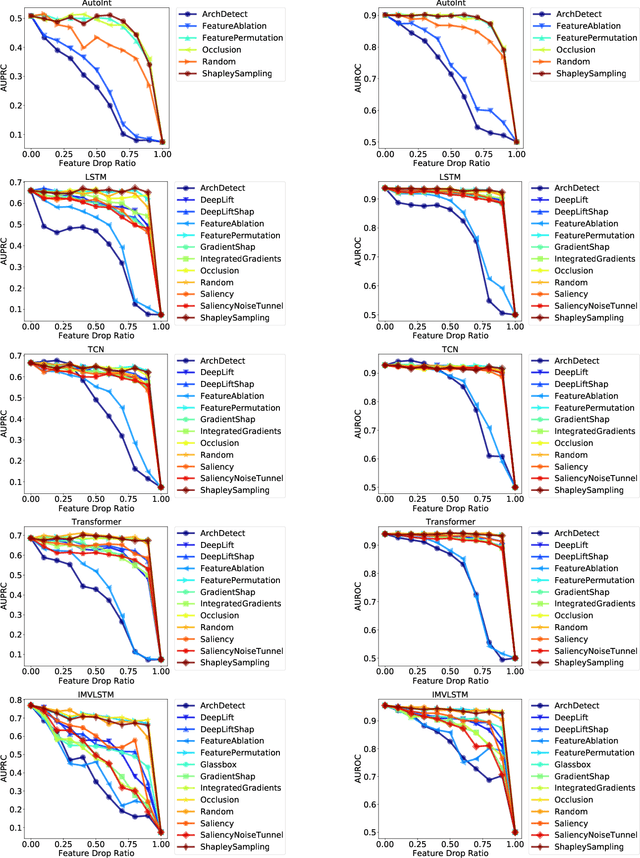

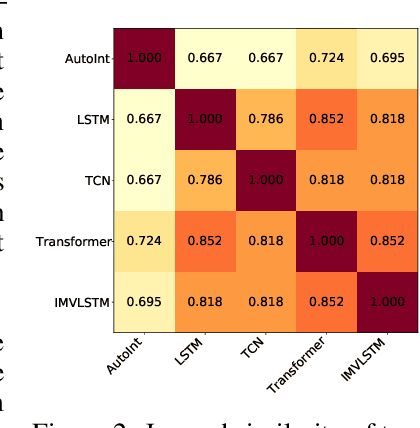
The recent release of large-scale healthcare datasets has greatly propelled the research of data-driven deep learning models for healthcare applications. However, due to the nature of such deep black-boxed models, concerns about interpretability, fairness, and biases in healthcare scenarios where human lives are at stake call for a careful and thorough examinations of both datasets and models. In this work, we focus on MIMIC-IV (Medical Information Mart for Intensive Care, version IV), the largest publicly available healthcare dataset, and conduct comprehensive analyses of dataset representation bias as well as interpretability and prediction fairness of deep learning models for in-hospital mortality prediction. In terms of interpretabilty, we observe that (1) the best performing interpretability method successfully identifies critical features for mortality prediction on various prediction models; (2) demographic features are important for prediction. In terms of fairness, we observe that (1) there exists disparate treatment in prescribing mechanical ventilation among patient groups across ethnicity, gender and age; (2) all of the studied mortality predictors are generally fair while the IMV-LSTM (Interpretable Multi-Variable Long Short-Term Memory) model provides the most accurate and unbiased predictions across all protected groups. We further draw concrete connections between interpretability methods and fairness metrics by showing how feature importance from interpretability methods can be beneficial in quantifying potential disparities in mortality predictors.
Interpretable Deepfake Detection via Dynamic Prototypes
Jun 28, 2020


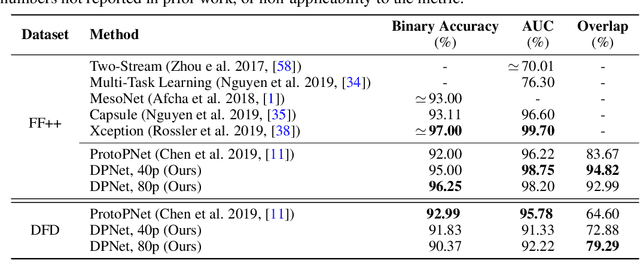
Deepfake is one notorious application of deep learning research, leading to massive amounts of video content on social media ridden with malicious intent. Therefore detecting deepfake videos has emerged as one of the most pressing challenges in AI research. Most state-of-the-art deepfake solutions are based on black-box models that process videos frame-by-frame for inference, and they do not consider temporal dynamics, which are key for detecting and explaining deepfake videos by humans. To this end, we propose Dynamic Prototype Network (DPNet) - a simple, interpretable, yet effective solution that leverages dynamic representations (i.e., prototypes) to explain deepfake visual dynamics. Experiment results show that the explanations of DPNet provide better overlap with the ground truth than state-of-the-art methods with comparable prediction performance. Furthermore, we formulate temporal logic specifications based on these prototypes to check the compliance of our model to desired temporal behaviors.