 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Accelerating Communication in Deep Learning Recommendation Model Training with Dual-Level Adaptive Lossy Compression
Jul 05, 2024DLRM is a state-of-the-art recommendation system model that has gained widespread adoption across various industry applications. The large size of DLRM models, however, necessitates the use of multiple devices/GPUs for efficient training. A significant bottleneck in this process is the time-consuming all-to-all communication required to collect embedding data from all devices. To mitigate this, we introduce a method that employs error-bounded lossy compression to reduce the communication data size and accelerate DLRM training. We develop a novel error-bounded lossy compression algorithm, informed by an in-depth analysis of embedding data features, to achieve high compression ratios. Moreover, we introduce a dual-level adaptive strategy for error-bound adjustment, spanning both table-wise and iteration-wise aspects, to balance the compression benefits with the potential impacts on accuracy. We further optimize our compressor for PyTorch tensors on GPUs, minimizing compression overhead. Evaluation shows that our method achieves a 1.38$\times$ training speedup with a minimal accuracy impact.
Wukong: Towards a Scaling Law for Large-Scale Recommendation
Mar 08, 2024



Scaling laws play an instrumental role in the sustainable improvement in model quality. Unfortunately, recommendation models to date do not exhibit such laws similar to those observed in the domain of large language models, due to the inefficiencies of their upscaling mechanisms. This limitation poses significant challenges in adapting these models to increasingly more complex real-world datasets. In this paper, we propose an effective network architecture based purely on stacked factorization machines, and a synergistic upscaling strategy, collectively dubbed Wukong, to establish a scaling law in the domain of recommendation. Wukong's unique design makes it possible to capture diverse, any-order of interactions simply through taller and wider layers. We conducted extensive evaluations on six public datasets, and our results demonstrate that Wukong consistently outperforms state-of-the-art models quality-wise. Further, we assessed Wukong's scalability on an internal, large-scale dataset. The results show that Wukong retains its superiority in quality over state-of-the-art models, while holding the scaling law across two orders of magnitude in model complexity, extending beyond 100 Gflop or equivalently up to Large Language Model (GPT-3) training compute scale, where prior arts fall short.
Disaggregated Multi-Tower: Topology-aware Modeling Technique for Efficient Large-Scale Recommendation
Mar 07, 2024



We study a mismatch between the deep learning recommendation models' flat architecture, common distributed training paradigm and hierarchical data center topology. To address the associated inefficiencies, we propose Disaggregated Multi-Tower (DMT), a modeling technique that consists of (1) Semantic-preserving Tower Transform (SPTT), a novel training paradigm that decomposes the monolithic global embedding lookup process into disjoint towers to exploit data center locality; (2) Tower Module (TM), a synergistic dense component attached to each tower to reduce model complexity and communication volume through hierarchical feature interaction; and (3) Tower Partitioner (TP), a feature partitioner to systematically create towers with meaningful feature interactions and load balanced assignments to preserve model quality and training throughput via learned embeddings. We show that DMT can achieve up to 1.9x speedup compared to the state-of-the-art baselines without losing accuracy across multiple generations of hardware at large data center scales.
Rankitect: Ranking Architecture Search Battling World-class Engineers at Meta Scale
Nov 14, 2023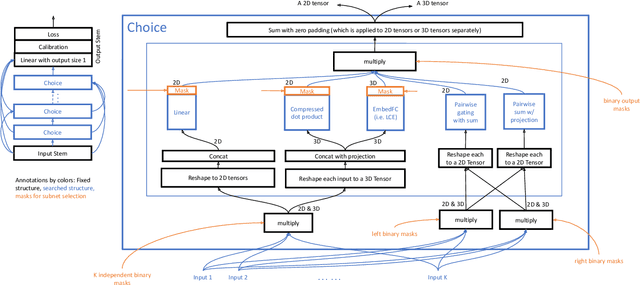
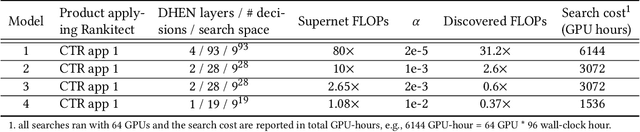
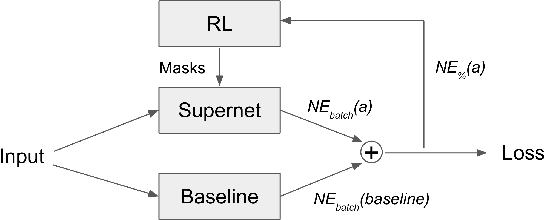
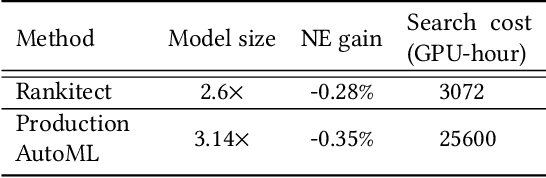
Neural Architecture Search (NAS) has demonstrated its efficacy in computer vision and potential for ranking systems. However, prior work focused on academic problems, which are evaluated at small scale under well-controlled fixed baselines. In industry system, such as ranking system in Meta, it is unclear whether NAS algorithms from the literature can outperform production baselines because of: (1) scale - Meta ranking systems serve billions of users, (2) strong baselines - the baselines are production models optimized by hundreds to thousands of world-class engineers for years since the rise of deep learning, (3) dynamic baselines - engineers may have established new and stronger baselines during NAS search, and (4) efficiency - the search pipeline must yield results quickly in alignment with the productionization life cycle. In this paper, we present Rankitect, a NAS software framework for ranking systems at Meta. Rankitect seeks to build brand new architectures by composing low level building blocks from scratch. Rankitect implements and improves state-of-the-art (SOTA) NAS methods for comprehensive and fair comparison under the same search space, including sampling-based NAS, one-shot NAS, and Differentiable NAS (DNAS). We evaluate Rankitect by comparing to multiple production ranking models at Meta. We find that Rankitect can discover new models from scratch achieving competitive tradeoff between Normalized Entropy loss and FLOPs. When utilizing search space designed by engineers, Rankitect can generate better models than engineers, achieving positive offline evaluation and online A/B test at Meta scale.
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Apr 21, 2023It is widely acknowledged that large models have the potential to deliver superior performance across a broad range of domains. Despite the remarkable progress made in the field of machine learning systems research, which has enabled the development and exploration of large models, such abilities remain confined to a small group of advanced users and industry leaders, resulting in an implicit technical barrier for the wider community to access and leverage these technologies. In this paper, we introduce PyTorch Fully Sharded Data Parallel (FSDP) as an industry-grade solution for large model training. FSDP has been closely co-designed with several key PyTorch core components including Tensor implementation, dispatcher system, and CUDA memory caching allocator, to provide non-intrusive user experiences and high training efficiency. Additionally, FSDP natively incorporates a range of techniques and settings to optimize resource utilization across a variety of hardware configurations. The experimental results demonstrate that FSDP is capable of achieving comparable performance to Distributed Data Parallel while providing support for significantly larger models with near-linear scalability in terms of TFLOPS.
DHEN: A Deep and Hierarchical Ensemble Network for Large-Scale Click-Through Rate Prediction
Mar 11, 2022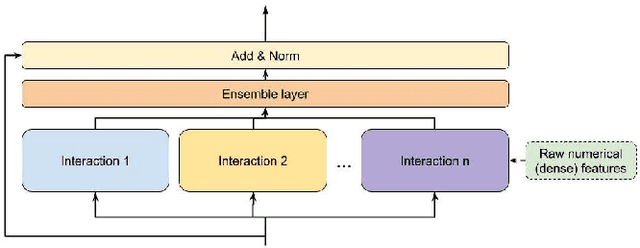
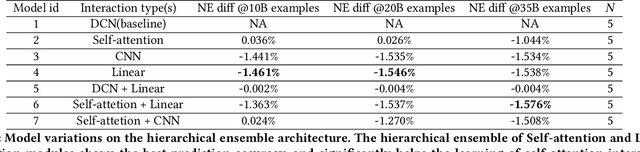
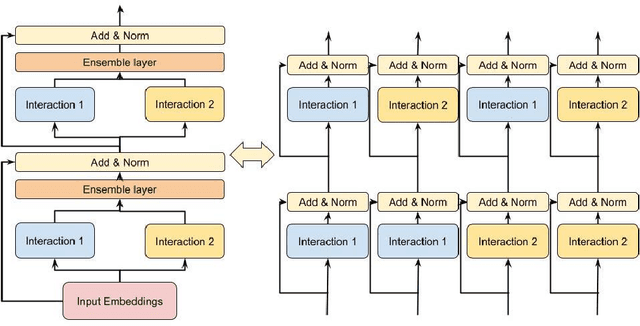

Learning feature interactions is important to the model performance of online advertising services. As a result, extensive efforts have been devoted to designing effective architectures to learn feature interactions. However, we observe that the practical performance of those designs can vary from dataset to dataset, even when the order of interactions claimed to be captured is the same. That indicates different designs may have different advantages and the interactions captured by them have non-overlapping information. Motivated by this observation, we propose DHEN - a deep and hierarchical ensemble architecture that can leverage strengths of heterogeneous interaction modules and learn a hierarchy of the interactions under different orders. To overcome the challenge brought by DHEN's deeper and multi-layer structure in training, we propose a novel co-designed training system that can further improve the training efficiency of DHEN. Experiments of DHEN on large-scale dataset from CTR prediction tasks attained 0.27\% improvement on the Normalized Entropy (NE) of prediction and 1.2x better training throughput than state-of-the-art baseline, demonstrating their effectiveness in practice.