 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
CubicML: Automated ML for Distributed ML Systems Co-design with ML Prediction of Performance
Sep 06, 2024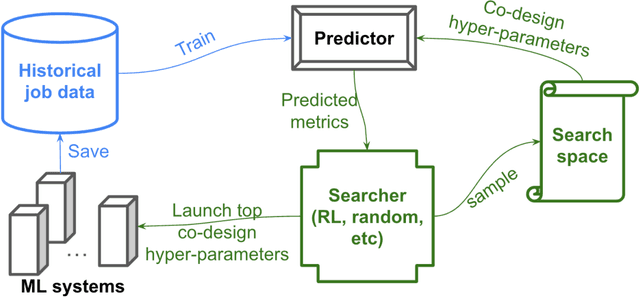
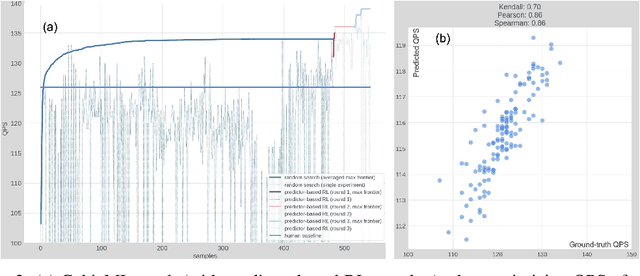
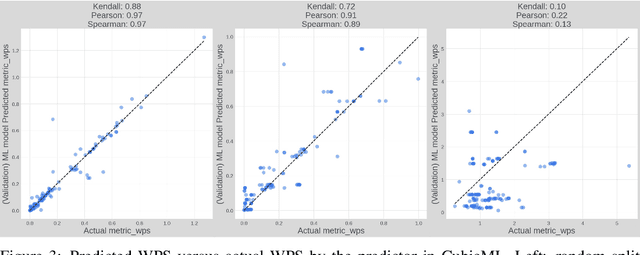
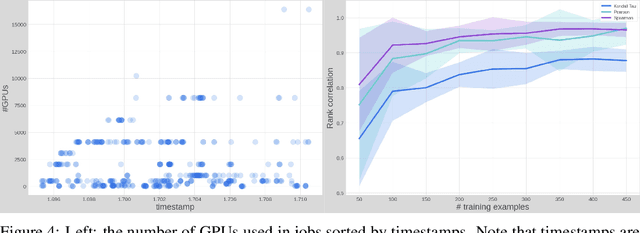
Scaling up deep learning models has been proven effective to improve intelligence of machine learning (ML) models, especially for industry recommendation models and large language models. The co-design of distributed ML systems and algorithms (to maximize training performance) plays a pivotal role for its success. As it scales, the number of co-design hyper-parameters grows rapidly which brings challenges to feasibly find the optimal setup for system performance maximization. In this paper, we propose CubicML which uses ML to automatically optimize training performance of distributed ML systems. In CubicML, we use a ML model as a proxy to predict the training performance for search efficiency and performance modeling flexibility. We proved that CubicML can effectively optimize training speed of in-house ads recommendation models and large language models at Meta.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Rankitect: Ranking Architecture Search Battling World-class Engineers at Meta Scale
Nov 14, 2023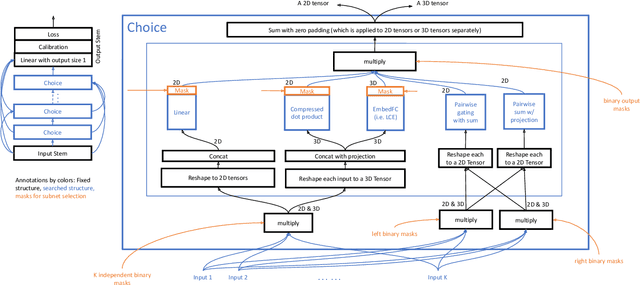
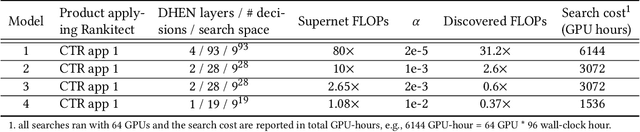
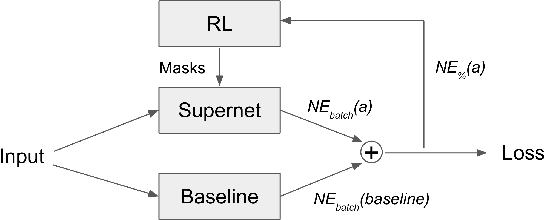
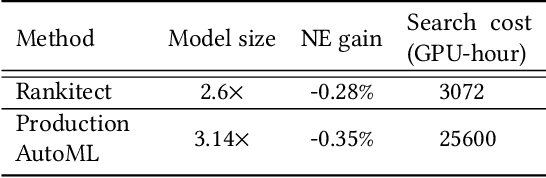
Neural Architecture Search (NAS) has demonstrated its efficacy in computer vision and potential for ranking systems. However, prior work focused on academic problems, which are evaluated at small scale under well-controlled fixed baselines. In industry system, such as ranking system in Meta, it is unclear whether NAS algorithms from the literature can outperform production baselines because of: (1) scale - Meta ranking systems serve billions of users, (2) strong baselines - the baselines are production models optimized by hundreds to thousands of world-class engineers for years since the rise of deep learning, (3) dynamic baselines - engineers may have established new and stronger baselines during NAS search, and (4) efficiency - the search pipeline must yield results quickly in alignment with the productionization life cycle. In this paper, we present Rankitect, a NAS software framework for ranking systems at Meta. Rankitect seeks to build brand new architectures by composing low level building blocks from scratch. Rankitect implements and improves state-of-the-art (SOTA) NAS methods for comprehensive and fair comparison under the same search space, including sampling-based NAS, one-shot NAS, and Differentiable NAS (DNAS). We evaluate Rankitect by comparing to multiple production ranking models at Meta. We find that Rankitect can discover new models from scratch achieving competitive tradeoff between Normalized Entropy loss and FLOPs. When utilizing search space designed by engineers, Rankitect can generate better models than engineers, achieving positive offline evaluation and online A/B test at Meta scale.