 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
The Efficiency vs. Accuracy Trade-off: Optimizing RAG-Enhanced LLM Recommender Systems Using Multi-Head Early Exit
Jan 04, 2025



The deployment of Large Language Models (LLMs) in recommender systems for predicting Click-Through Rates (CTR) necessitates a delicate balance between computational efficiency and predictive accuracy. This paper presents an optimization framework that combines Retrieval-Augmented Generation (RAG) with an innovative multi-head early exit architecture to concurrently enhance both aspects. By integrating Graph Convolutional Networks (GCNs) as efficient retrieval mechanisms, we are able to significantly reduce data retrieval times while maintaining high model performance. The early exit strategy employed allows for dynamic termination of model inference, utilizing real-time predictive confidence assessments across multiple heads. This not only quickens the responsiveness of LLMs but also upholds or improves their accuracy, making it ideal for real-time application scenarios. Our experiments demonstrate how this architecture effectively decreases computation time without sacrificing the accuracy needed for reliable recommendation delivery, establishing a new standard for efficient, real-time LLM deployment in commercial systems.
InterFormer: Towards Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction
Nov 15, 2024
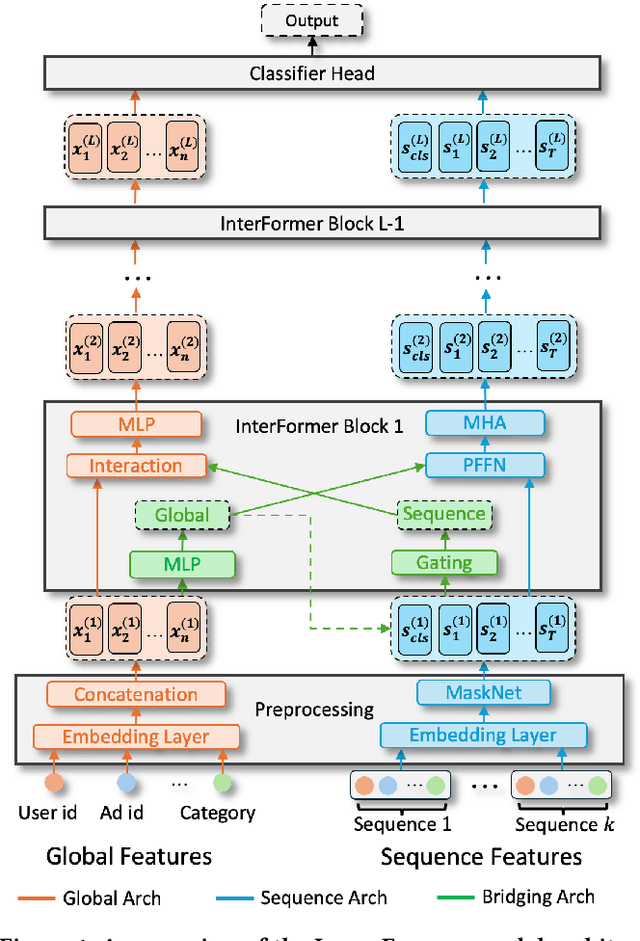
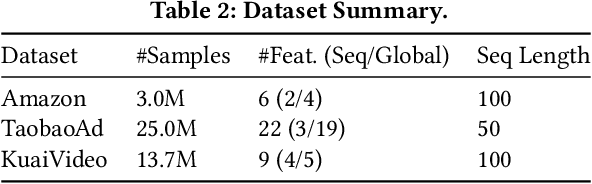
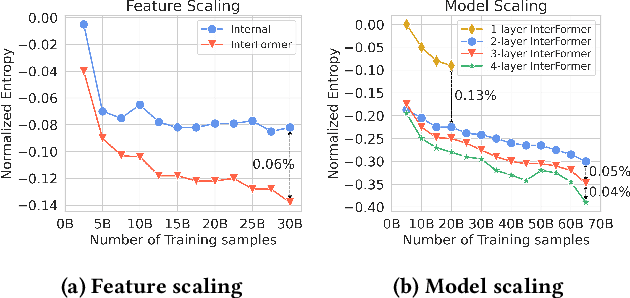
Click-through rate (CTR) prediction, which predicts the probability of a user clicking an ad, is a fundamental task in recommender systems. The emergence of heterogeneous information, such as user profile and behavior sequences, depicts user interests from different aspects. A mutually beneficial integration of heterogeneous information is the cornerstone towards the success of CTR prediction. However, most of the existing methods suffer from two fundamental limitations, including (1) insufficient inter-mode interaction due to the unidirectional information flow between modes, and (2) aggressive information aggregation caused by early summarization, resulting in excessive information loss. To address the above limitations, we propose a novel module named InterFormer to learn heterogeneous information interaction in an interleaving style. To achieve better interaction learning, InterFormer enables bidirectional information flow for mutually beneficial learning across different modes. To avoid aggressive information aggregation, we retain complete information in each data mode and use a separate bridging arch for effective information selection and summarization. Our proposed InterFormer achieves state-of-the-art performance on three public datasets and a large-scale industrial dataset.
Wukong: Towards a Scaling Law for Large-Scale Recommendation
Mar 08, 2024



Scaling laws play an instrumental role in the sustainable improvement in model quality. Unfortunately, recommendation models to date do not exhibit such laws similar to those observed in the domain of large language models, due to the inefficiencies of their upscaling mechanisms. This limitation poses significant challenges in adapting these models to increasingly more complex real-world datasets. In this paper, we propose an effective network architecture based purely on stacked factorization machines, and a synergistic upscaling strategy, collectively dubbed Wukong, to establish a scaling law in the domain of recommendation. Wukong's unique design makes it possible to capture diverse, any-order of interactions simply through taller and wider layers. We conducted extensive evaluations on six public datasets, and our results demonstrate that Wukong consistently outperforms state-of-the-art models quality-wise. Further, we assessed Wukong's scalability on an internal, large-scale dataset. The results show that Wukong retains its superiority in quality over state-of-the-art models, while holding the scaling law across two orders of magnitude in model complexity, extending beyond 100 Gflop or equivalently up to Large Language Model (GPT-3) training compute scale, where prior arts fall short.
Disaggregated Multi-Tower: Topology-aware Modeling Technique for Efficient Large-Scale Recommendation
Mar 07, 2024



We study a mismatch between the deep learning recommendation models' flat architecture, common distributed training paradigm and hierarchical data center topology. To address the associated inefficiencies, we propose Disaggregated Multi-Tower (DMT), a modeling technique that consists of (1) Semantic-preserving Tower Transform (SPTT), a novel training paradigm that decomposes the monolithic global embedding lookup process into disjoint towers to exploit data center locality; (2) Tower Module (TM), a synergistic dense component attached to each tower to reduce model complexity and communication volume through hierarchical feature interaction; and (3) Tower Partitioner (TP), a feature partitioner to systematically create towers with meaningful feature interactions and load balanced assignments to preserve model quality and training throughput via learned embeddings. We show that DMT can achieve up to 1.9x speedup compared to the state-of-the-art baselines without losing accuracy across multiple generations of hardware at large data center scales.
AutoML for Large Capacity Modeling of Meta's Ranking Systems
Nov 16, 2023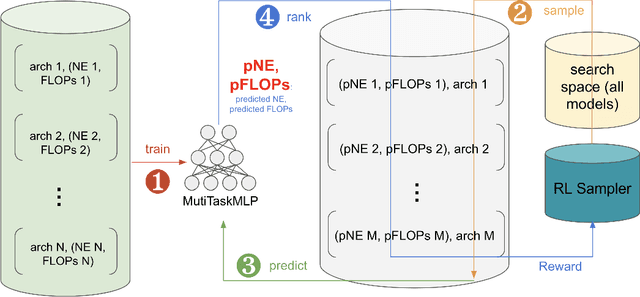
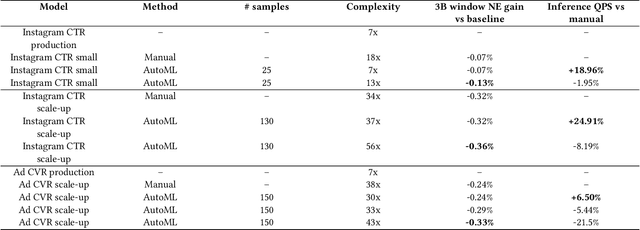
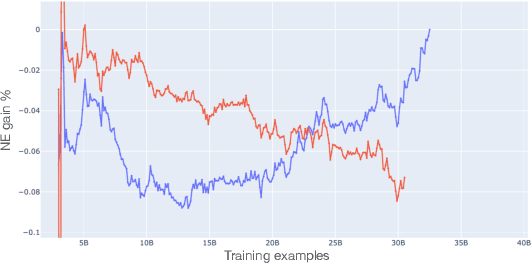

Web-scale ranking systems at Meta serving billions of users is complex. Improving ranking models is essential but engineering heavy. Automated Machine Learning (AutoML) can release engineers from labor intensive work of tuning ranking models; however, it is unknown if AutoML is efficient enough to meet tight production timeline in real-world and, at the same time, bring additional improvements to the strong baselines. Moreover, to achieve higher ranking performance, there is an ever-increasing demand to scale up ranking models to even larger capacity, which imposes more challenges on the efficiency. The large scale of models and tight production schedule requires AutoML to outperform human baselines by only using a small number of model evaluation trials (around 100). We presents a sampling-based AutoML method, focusing on neural architecture search and hyperparameter optimization, addressing these challenges in Meta-scale production when building large capacity models. Our approach efficiently handles large-scale data demands. It leverages a lightweight predictor-based searcher and reinforcement learning to explore vast search spaces, significantly reducing the number of model evaluations. Through experiments in large capacity modeling for CTR and CVR applications, we show that our method achieves outstanding Return on Investment (ROI) versus human tuned baselines, with up to 0.09% Normalized Entropy (NE) loss reduction or $25\%$ Query per Second (QPS) increase by only sampling one hundred models on average from a curated search space. The proposed AutoML method has already made real-world impact where a discovered Instagram CTR model with up to -0.36% NE gain (over existing production baseline) was selected for large-scale online A/B test and show statistically significant gain. These production results proved AutoML efficacy and accelerated its adoption in ranking systems at Meta.
Rankitect: Ranking Architecture Search Battling World-class Engineers at Meta Scale
Nov 14, 2023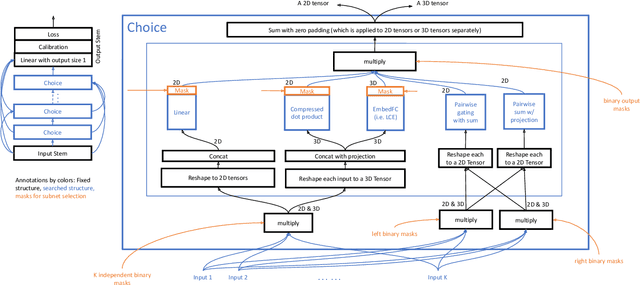
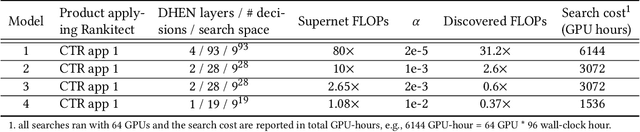
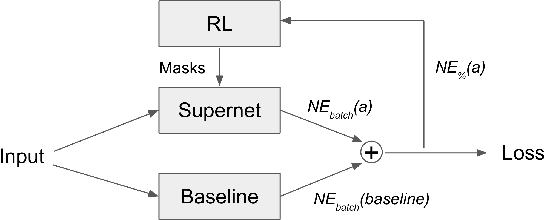
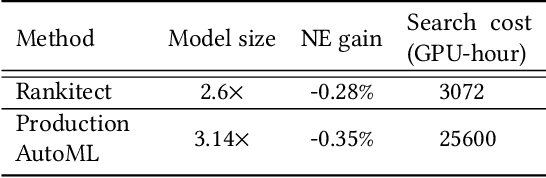
Neural Architecture Search (NAS) has demonstrated its efficacy in computer vision and potential for ranking systems. However, prior work focused on academic problems, which are evaluated at small scale under well-controlled fixed baselines. In industry system, such as ranking system in Meta, it is unclear whether NAS algorithms from the literature can outperform production baselines because of: (1) scale - Meta ranking systems serve billions of users, (2) strong baselines - the baselines are production models optimized by hundreds to thousands of world-class engineers for years since the rise of deep learning, (3) dynamic baselines - engineers may have established new and stronger baselines during NAS search, and (4) efficiency - the search pipeline must yield results quickly in alignment with the productionization life cycle. In this paper, we present Rankitect, a NAS software framework for ranking systems at Meta. Rankitect seeks to build brand new architectures by composing low level building blocks from scratch. Rankitect implements and improves state-of-the-art (SOTA) NAS methods for comprehensive and fair comparison under the same search space, including sampling-based NAS, one-shot NAS, and Differentiable NAS (DNAS). We evaluate Rankitect by comparing to multiple production ranking models at Meta. We find that Rankitect can discover new models from scratch achieving competitive tradeoff between Normalized Entropy loss and FLOPs. When utilizing search space designed by engineers, Rankitect can generate better models than engineers, achieving positive offline evaluation and online A/B test at Meta scale.
DistDNAS: Search Efficient Feature Interactions within 2 Hours
Nov 01, 2023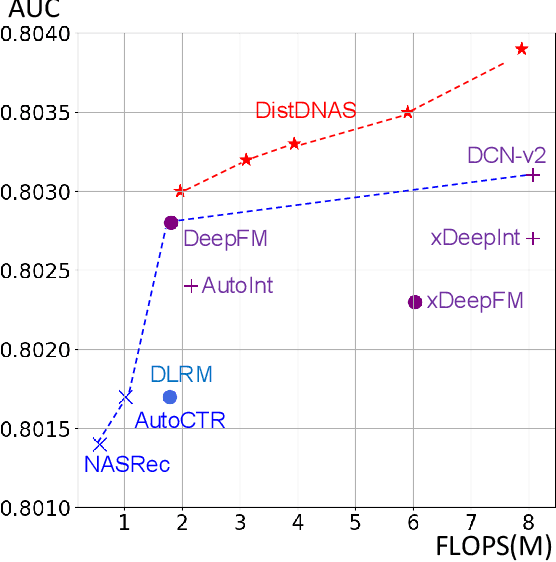

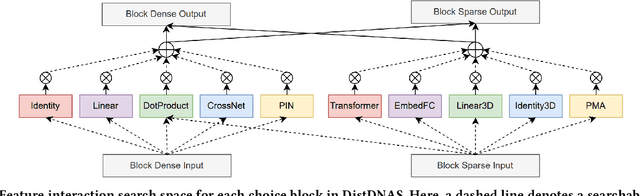

Search efficiency and serving efficiency are two major axes in building feature interactions and expediting the model development process in recommender systems. On large-scale benchmarks, searching for the optimal feature interaction design requires extensive cost due to the sequential workflow on the large volume of data. In addition, fusing interactions of various sources, orders, and mathematical operations introduces potential conflicts and additional redundancy toward recommender models, leading to sub-optimal trade-offs in performance and serving cost. In this paper, we present DistDNAS as a neat solution to brew swift and efficient feature interaction design. DistDNAS proposes a supernet to incorporate interaction modules of varying orders and types as a search space. To optimize search efficiency, DistDNAS distributes the search and aggregates the choice of optimal interaction modules on varying data dates, achieving over 25x speed-up and reducing search cost from 2 days to 2 hours. To optimize serving efficiency, DistDNAS introduces a differentiable cost-aware loss to penalize the selection of redundant interaction modules, enhancing the efficiency of discovered feature interactions in serving. We extensively evaluate the best models crafted by DistDNAS on a 1TB Criteo Terabyte dataset. Experimental evaluations demonstrate 0.001 AUC improvement and 60% FLOPs saving over current state-of-the-art CTR models.
DHEN: A Deep and Hierarchical Ensemble Network for Large-Scale Click-Through Rate Prediction
Mar 11, 2022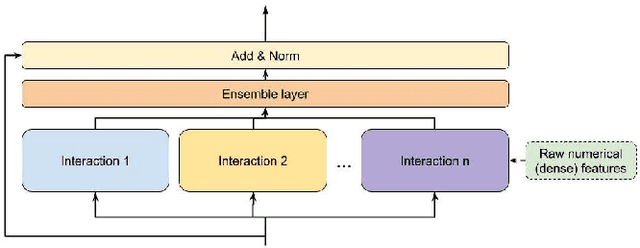
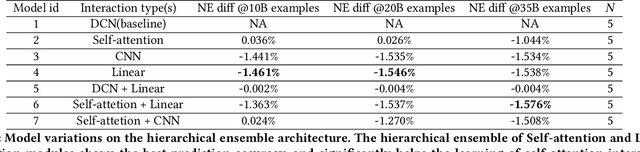
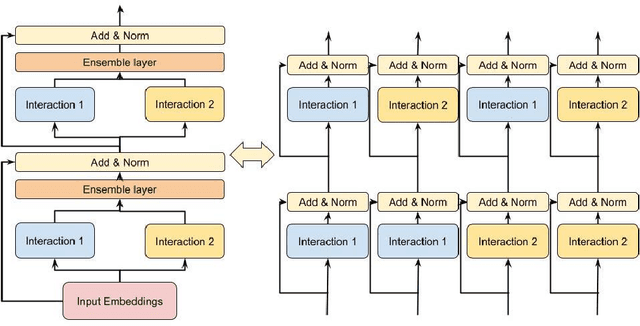

Learning feature interactions is important to the model performance of online advertising services. As a result, extensive efforts have been devoted to designing effective architectures to learn feature interactions. However, we observe that the practical performance of those designs can vary from dataset to dataset, even when the order of interactions claimed to be captured is the same. That indicates different designs may have different advantages and the interactions captured by them have non-overlapping information. Motivated by this observation, we propose DHEN - a deep and hierarchical ensemble architecture that can leverage strengths of heterogeneous interaction modules and learn a hierarchy of the interactions under different orders. To overcome the challenge brought by DHEN's deeper and multi-layer structure in training, we propose a novel co-designed training system that can further improve the training efficiency of DHEN. Experiments of DHEN on large-scale dataset from CTR prediction tasks attained 0.27\% improvement on the Normalized Entropy (NE) of prediction and 1.2x better training throughput than state-of-the-art baseline, demonstrating their effectiveness in practice.