 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing LLMs Explanations to Boost Surrogate Models in Tabular Data Classification
May 09, 2025Large Language Models (LLMs) have shown remarkable ability in solving complex tasks, making them a promising tool for enhancing tabular learning. However, existing LLM-based methods suffer from high resource requirements, suboptimal demonstration selection, and limited interpretability, which largely hinder their prediction performance and application in the real world. To overcome these problems, we propose a novel in-context learning framework for tabular prediction. The core idea is to leverage the explanations generated by LLMs to guide a smaller, locally deployable Surrogate Language Model (SLM) to make interpretable tabular predictions. Specifically, our framework mainly involves three stages: (i) Post Hoc Explanation Generation, where LLMs are utilized to generate explanations for question-answer pairs in candidate demonstrations, providing insights into the reasoning behind the answer. (ii) Post Hoc Explanation-Guided Demonstrations Selection, which utilizes explanations generated by LLMs to guide the process of demonstration selection from candidate demonstrations. (iii) Post Hoc Explanation-Guided Interpretable SLM Prediction, which utilizes the demonstrations obtained in step (ii) as in-context and merges corresponding explanations as rationales to improve the performance of SLM and guide the model to generate interpretable outputs. Experimental results highlight the framework's effectiveness, with an average accuracy improvement of 5.31% across various tabular datasets in diverse domains.
Latte: Transfering LLMs` Latent-level Knowledge for Few-shot Tabular Learning
May 08, 2025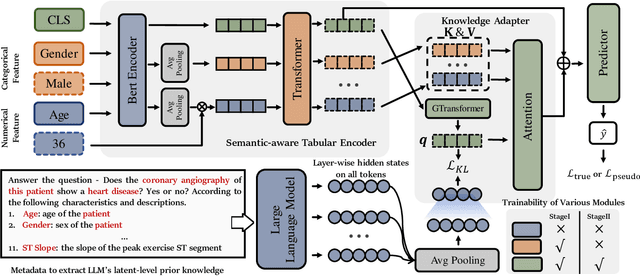
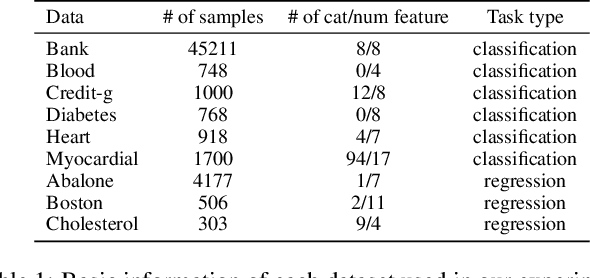
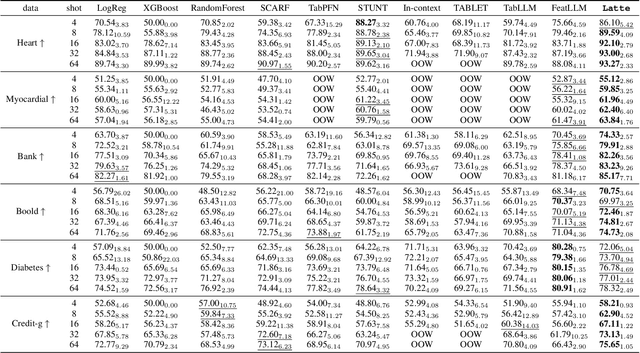

Few-shot tabular learning, in which machine learning models are trained with a limited amount of labeled data, provides a cost-effective approach to addressing real-world challenges. The advent of Large Language Models (LLMs) has sparked interest in leveraging their pre-trained knowledge for few-shot tabular learning. Despite promising results, existing approaches either rely on test-time knowledge extraction, which introduces undesirable latency, or text-level knowledge, which leads to unreliable feature engineering. To overcome these limitations, we propose Latte, a training-time knowledge extraction framework that transfers the latent prior knowledge within LLMs to optimize a more generalized downstream model. Latte enables general knowledge-guided downstream tabular learning, facilitating the weighted fusion of information across different feature values while reducing the risk of overfitting to limited labeled data. Furthermore, Latte is compatible with existing unsupervised pre-training paradigms and effectively utilizes available unlabeled samples to overcome the performance limitations imposed by an extremely small labeled dataset. Extensive experiments on various few-shot tabular learning benchmarks demonstrate the superior performance of Latte, establishing it as a state-of-the-art approach in this domain
Layer-Level Self-Exposure and Patch: Affirmative Token Mitigation for Jailbreak Attack Defense
Jan 05, 2025As large language models (LLMs) are increasingly deployed in diverse applications, including chatbot assistants and code generation, aligning their behavior with safety and ethical standards has become paramount. However, jailbreak attacks, which exploit vulnerabilities to elicit unintended or harmful outputs, threaten LLMs' safety significantly. In this paper, we introduce Layer-AdvPatcher, a novel methodology designed to defend against jailbreak attacks by utilizing an unlearning strategy to patch specific layers within LLMs through self-augmented datasets. Our insight is that certain layer(s), tend to produce affirmative tokens when faced with harmful prompts. By identifying these layers and adversarially exposing them to generate more harmful data, one can understand their inherent and diverse vulnerabilities to attacks. With these exposures, we then "unlearn" these issues, reducing the impact of affirmative tokens and hence minimizing jailbreak risks while keeping the model's responses to safe queries intact. We conduct extensive experiments on two models, four benchmark datasets, and multiple state-of-the-art jailbreak benchmarks to demonstrate the efficacy of our approach. Results indicate that our framework reduces the harmfulness and attack success rate of jailbreak attacks without compromising utility for benign queries compared to recent defense methods.
The Efficiency vs. Accuracy Trade-off: Optimizing RAG-Enhanced LLM Recommender Systems Using Multi-Head Early Exit
Jan 04, 2025



The deployment of Large Language Models (LLMs) in recommender systems for predicting Click-Through Rates (CTR) necessitates a delicate balance between computational efficiency and predictive accuracy. This paper presents an optimization framework that combines Retrieval-Augmented Generation (RAG) with an innovative multi-head early exit architecture to concurrently enhance both aspects. By integrating Graph Convolutional Networks (GCNs) as efficient retrieval mechanisms, we are able to significantly reduce data retrieval times while maintaining high model performance. The early exit strategy employed allows for dynamic termination of model inference, utilizing real-time predictive confidence assessments across multiple heads. This not only quickens the responsiveness of LLMs but also upholds or improves their accuracy, making it ideal for real-time application scenarios. Our experiments demonstrate how this architecture effectively decreases computation time without sacrificing the accuracy needed for reliable recommendation delivery, establishing a new standard for efficient, real-time LLM deployment in commercial systems.
Pioneering Reliable Assessment in Text-to-Image Knowledge Editing: Leveraging a Fine-Grained Dataset and an Innovative Criterion
Sep 26, 2024During pre-training, the Text-to-Image (T2I) diffusion models encode factual knowledge into their parameters. These parameterized facts enable realistic image generation, but they may become obsolete over time, thereby misrepresenting the current state of the world. Knowledge editing techniques aim to update model knowledge in a targeted way. However, facing the dual challenges posed by inadequate editing datasets and unreliable evaluation criterion, the development of T2I knowledge editing encounter difficulties in effectively generalizing injected knowledge. In this work, we design a T2I knowledge editing framework by comprehensively spanning on three phases: First, we curate a dataset \textbf{CAKE}, comprising paraphrase and multi-object test, to enable more fine-grained assessment on knowledge generalization. Second, we propose a novel criterion, \textbf{adaptive CLIP threshold}, to effectively filter out false successful images under the current criterion and achieve reliable editing evaluation. Finally, we introduce \textbf{MPE}, a simple but effective approach for T2I knowledge editing. Instead of tuning parameters, MPE precisely recognizes and edits the outdated part of the conditioning text-prompt to accommodate the up-to-date knowledge. A straightforward implementation of MPE (Based on in-context learning) exhibits better overall performance than previous model editors. We hope these efforts can further promote faithful evaluation of T2I knowledge editing methods.
Cross-Lingual Multi-Hop Knowledge Editing -- Benchmarks, Analysis and a Simple Contrastive Learning based Approach
Jul 14, 2024



Large language models are often expected to constantly adapt to new sources of knowledge and knowledge editing techniques aim to efficiently patch the outdated model knowledge, with minimal modification. Most prior works focus on monolingual knowledge editing in English, even though new information can emerge in any language from any part of the world. We propose the Cross-Lingual Multi-Hop Knowledge Editing paradigm, for measuring and analyzing the performance of various SoTA knowledge editing techniques in a cross-lingual setup. Specifically, we create a parallel cross-lingual benchmark, CROLIN-MQUAKE for measuring the knowledge editing capabilities. Our extensive analysis over various knowledge editing techniques uncover significant gaps in performance between the cross-lingual and English-centric setting. Following this, we propose a significantly improved system for cross-lingual multi-hop knowledge editing, CLEVER-CKE. CLEVER-CKE is based on a retrieve, verify and generate knowledge editing framework, where a retriever is formulated to recall edited facts and support an LLM to adhere to knowledge edits. We develop language-aware and hard-negative based contrastive objectives for improving the cross-lingual and fine-grained fact retrieval and verification process used in this framework. Extensive experiments on three LLMs, eight languages, and two datasets show CLEVER-CKE's significant gains of up to 30% over prior methods.
PokeMQA: Programmable knowledge editing for Multi-hop Question Answering
Dec 23, 2023Multi-hop question answering (MQA) is one of the challenging tasks to evaluate machine's comprehension and reasoning abilities, where large language models (LLMs) have widely achieved the human-comparable performance. Due to the dynamics of knowledge facts in real world, knowledge editing has been explored to update model with the up-to-date facts while avoiding expensive re-training or fine-tuning. Starting from the edited fact, the updated model needs to provide cascading changes in the chain of MQA. The previous art simply adopts a mix-up prompt to instruct LLMs conducting multiple reasoning tasks sequentially, including question decomposition, answer generation, and conflict checking via comparing with edited facts. However, the coupling of these functionally-diverse reasoning tasks inhibits LLMs' advantages in comprehending and answering questions while disturbing them with the unskilled task of conflict checking. We thus propose a framework, Programmable knowledge editing for Multi-hop Question Answering (PokeMQA), to decouple the jobs. Specifically, we prompt LLMs to decompose knowledge-augmented multi-hop question, while interacting with a detached trainable scope detector to modulate LLMs behavior depending on external conflict signal. The experiments on three LLM backbones and two benchmark datasets validate our superiority in knowledge editing of MQA, outperforming all competitors by a large margin in almost all settings and consistently producing reliable reasoning process.