 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWukong: Towards a Scaling Law for Large-Scale Recommendation
Mar 08, 2024



Scaling laws play an instrumental role in the sustainable improvement in model quality. Unfortunately, recommendation models to date do not exhibit such laws similar to those observed in the domain of large language models, due to the inefficiencies of their upscaling mechanisms. This limitation poses significant challenges in adapting these models to increasingly more complex real-world datasets. In this paper, we propose an effective network architecture based purely on stacked factorization machines, and a synergistic upscaling strategy, collectively dubbed Wukong, to establish a scaling law in the domain of recommendation. Wukong's unique design makes it possible to capture diverse, any-order of interactions simply through taller and wider layers. We conducted extensive evaluations on six public datasets, and our results demonstrate that Wukong consistently outperforms state-of-the-art models quality-wise. Further, we assessed Wukong's scalability on an internal, large-scale dataset. The results show that Wukong retains its superiority in quality over state-of-the-art models, while holding the scaling law across two orders of magnitude in model complexity, extending beyond 100 Gflop or equivalently up to Large Language Model (GPT-3) training compute scale, where prior arts fall short.
AutoML for Large Capacity Modeling of Meta's Ranking Systems
Nov 16, 2023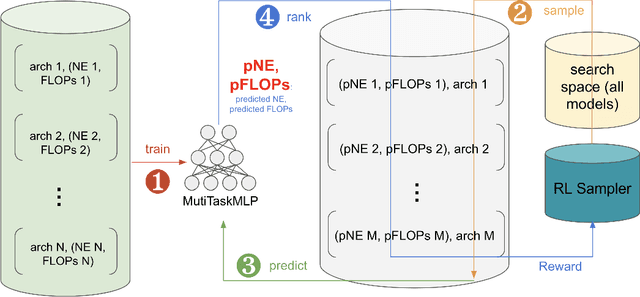
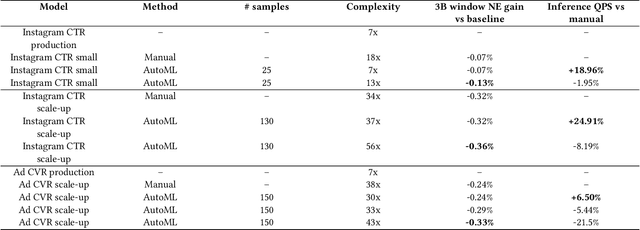
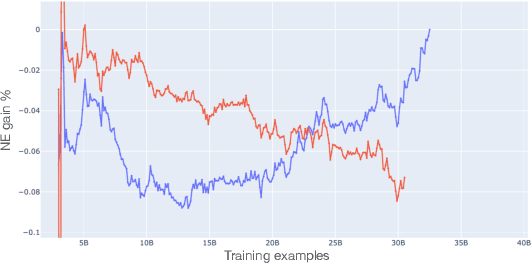

Web-scale ranking systems at Meta serving billions of users is complex. Improving ranking models is essential but engineering heavy. Automated Machine Learning (AutoML) can release engineers from labor intensive work of tuning ranking models; however, it is unknown if AutoML is efficient enough to meet tight production timeline in real-world and, at the same time, bring additional improvements to the strong baselines. Moreover, to achieve higher ranking performance, there is an ever-increasing demand to scale up ranking models to even larger capacity, which imposes more challenges on the efficiency. The large scale of models and tight production schedule requires AutoML to outperform human baselines by only using a small number of model evaluation trials (around 100). We presents a sampling-based AutoML method, focusing on neural architecture search and hyperparameter optimization, addressing these challenges in Meta-scale production when building large capacity models. Our approach efficiently handles large-scale data demands. It leverages a lightweight predictor-based searcher and reinforcement learning to explore vast search spaces, significantly reducing the number of model evaluations. Through experiments in large capacity modeling for CTR and CVR applications, we show that our method achieves outstanding Return on Investment (ROI) versus human tuned baselines, with up to 0.09% Normalized Entropy (NE) loss reduction or $25\%$ Query per Second (QPS) increase by only sampling one hundred models on average from a curated search space. The proposed AutoML method has already made real-world impact where a discovered Instagram CTR model with up to -0.36% NE gain (over existing production baseline) was selected for large-scale online A/B test and show statistically significant gain. These production results proved AutoML efficacy and accelerated its adoption in ranking systems at Meta.