 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
Two-dimensional Sparse Parallelism for Large Scale Deep Learning Recommendation Model Training
Aug 05, 2025The increasing complexity of deep learning recommendation models (DLRM) has led to a growing need for large-scale distributed systems that can efficiently train vast amounts of data. In DLRM, the sparse embedding table is a crucial component for managing sparse categorical features. Typically, these tables in industrial DLRMs contain trillions of parameters, necessitating model parallelism strategies to address memory constraints. However, as training systems expand with massive GPUs, the traditional fully parallelism strategies for embedding table post significant scalability challenges, including imbalance and straggler issues, intensive lookup communication, and heavy embedding activation memory. To overcome these limitations, we propose a novel two-dimensional sparse parallelism approach. Rather than fully sharding tables across all GPUs, our solution introduces data parallelism on top of model parallelism. This enables efficient all-to-all communication and reduces peak memory consumption. Additionally, we have developed the momentum-scaled row-wise AdaGrad algorithm to mitigate performance losses associated with the shift in training paradigms. Our extensive experiments demonstrate that the proposed approach significantly enhances training efficiency while maintaining model performance parity. It achieves nearly linear training speed scaling up to 4K GPUs, setting a new state-of-the-art benchmark for recommendation model training.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
InterFormer: Towards Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction
Nov 15, 2024
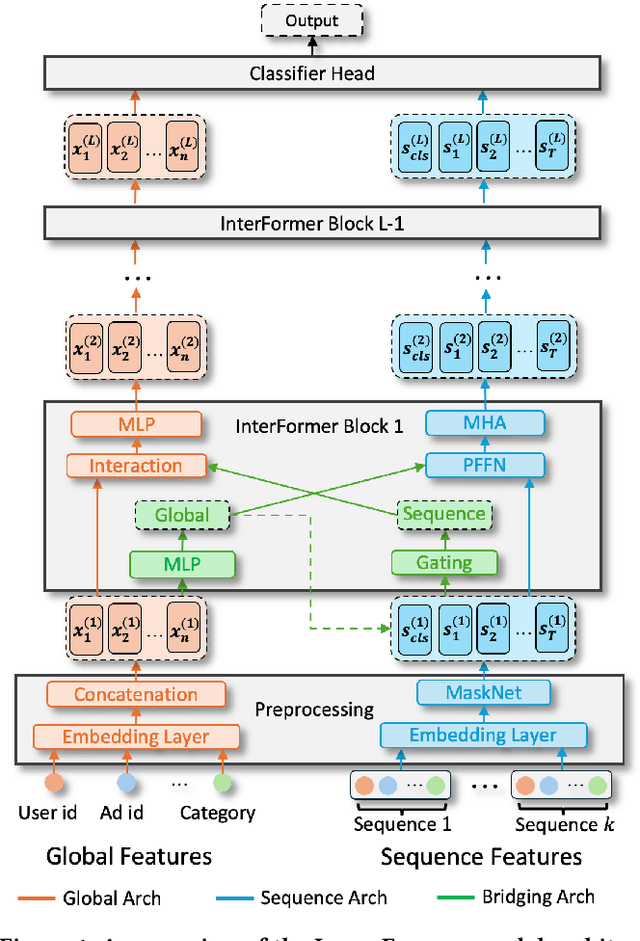
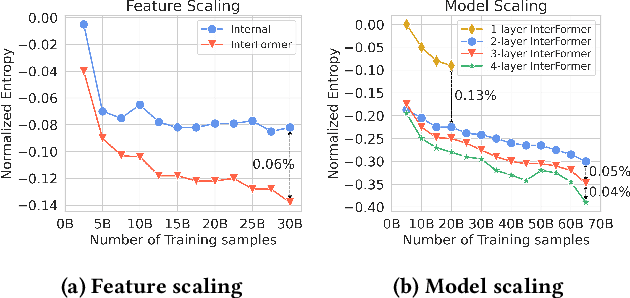
Click-through rate (CTR) prediction, which predicts the probability of a user clicking an ad, is a fundamental task in recommender systems. The emergence of heterogeneous information, such as user profile and behavior sequences, depicts user interests from different aspects. A mutually beneficial integration of heterogeneous information is the cornerstone towards the success of CTR prediction. However, most of the existing methods suffer from two fundamental limitations, including (1) insufficient inter-mode interaction due to the unidirectional information flow between modes, and (2) aggressive information aggregation caused by early summarization, resulting in excessive information loss. To address the above limitations, we propose a novel module named InterFormer to learn heterogeneous information interaction in an interleaving style. To achieve better interaction learning, InterFormer enables bidirectional information flow for mutually beneficial learning across different modes. To avoid aggressive information aggregation, we retain complete information in each data mode and use a separate bridging arch for effective information selection and summarization. Our proposed InterFormer achieves state-of-the-art performance on three public datasets and a large-scale industrial dataset.
Wukong: Towards a Scaling Law for Large-Scale Recommendation
Mar 08, 2024



Scaling laws play an instrumental role in the sustainable improvement in model quality. Unfortunately, recommendation models to date do not exhibit such laws similar to those observed in the domain of large language models, due to the inefficiencies of their upscaling mechanisms. This limitation poses significant challenges in adapting these models to increasingly more complex real-world datasets. In this paper, we propose an effective network architecture based purely on stacked factorization machines, and a synergistic upscaling strategy, collectively dubbed Wukong, to establish a scaling law in the domain of recommendation. Wukong's unique design makes it possible to capture diverse, any-order of interactions simply through taller and wider layers. We conducted extensive evaluations on six public datasets, and our results demonstrate that Wukong consistently outperforms state-of-the-art models quality-wise. Further, we assessed Wukong's scalability on an internal, large-scale dataset. The results show that Wukong retains its superiority in quality over state-of-the-art models, while holding the scaling law across two orders of magnitude in model complexity, extending beyond 100 Gflop or equivalently up to Large Language Model (GPT-3) training compute scale, where prior arts fall short.
Pre-train and Search: Efficient Embedding Table Sharding with Pre-trained Neural Cost Models
May 03, 2023



Sharding a large machine learning model across multiple devices to balance the costs is important in distributed training. This is challenging because partitioning is NP-hard, and estimating the costs accurately and efficiently is difficult. In this work, we explore a "pre-train, and search" paradigm for efficient sharding. The idea is to pre-train a universal and once-for-all neural network to predict the costs of all the possible shards, which serves as an efficient sharding simulator. Built upon this pre-trained cost model, we then perform an online search to identify the best sharding plans given any specific sharding task. We instantiate this idea in deep learning recommendation models (DLRMs) and propose NeuroShard for embedding table sharding. NeuroShard pre-trains neural cost models on augmented tables to cover various sharding scenarios. Then it identifies the best column-wise and table-wise sharding plans with beam search and greedy grid search, respectively. Experiments show that NeuroShard significantly and consistently outperforms the state-of-the-art on the benchmark sharding dataset, achieving up to 23.8% improvement. When deployed in an ultra-large production DLRM with multi-terabyte embedding tables, NeuroShard achieves 11.6% improvement in embedding costs over the state-of-the-art, which translates to 6.6% end-to-end training throughput improvement. To facilitate future research of the "pre-train, and search" paradigm in ML for Systems, we open-source our code at https://github.com/daochenzha/neuroshard
AutoShard: Automated Embedding Table Sharding for Recommender Systems
Aug 12, 2022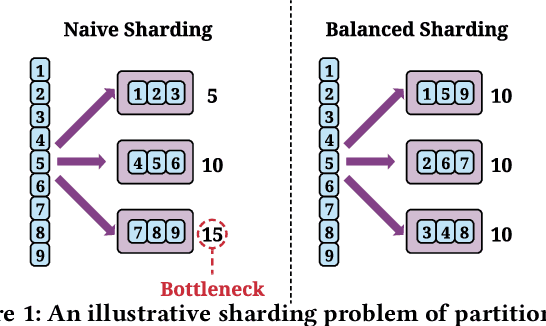
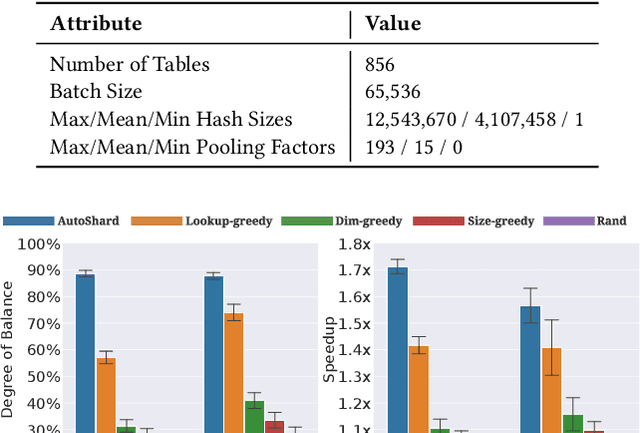

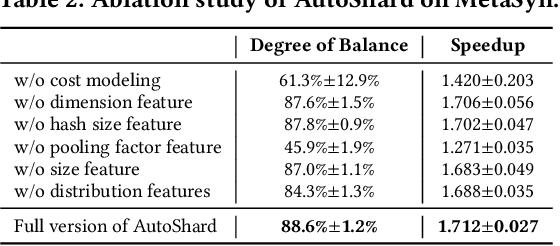
Embedding learning is an important technique in deep recommendation models to map categorical features to dense vectors. However, the embedding tables often demand an extremely large number of parameters, which become the storage and efficiency bottlenecks. Distributed training solutions have been adopted to partition the embedding tables into multiple devices. However, the embedding tables can easily lead to imbalances if not carefully partitioned. This is a significant design challenge of distributed systems named embedding table sharding, i.e., how we should partition the embedding tables to balance the costs across devices, which is a non-trivial task because 1) it is hard to efficiently and precisely measure the cost, and 2) the partition problem is known to be NP-hard. In this work, we introduce our novel practice in Meta, namely AutoShard, which uses a neural cost model to directly predict the multi-table costs and leverages deep reinforcement learning to solve the partition problem. Experimental results on an open-sourced large-scale synthetic dataset and Meta's production dataset demonstrate the superiority of AutoShard over the heuristics. Moreover, the learned policy of AutoShard can transfer to sharding tasks with various numbers of tables and different ratios of the unseen tables without any fine-tuning. Furthermore, AutoShard can efficiently shard hundreds of tables in seconds. The effectiveness, transferability, and efficiency of AutoShard make it desirable for production use. Our algorithms have been deployed in Meta production environment. A prototype is available at https://github.com/daochenzha/autoshard
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 15, 2021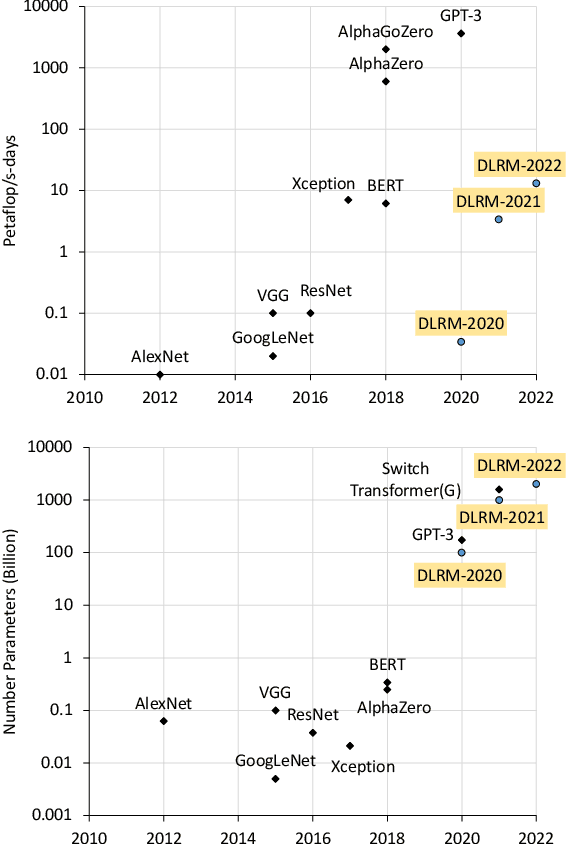

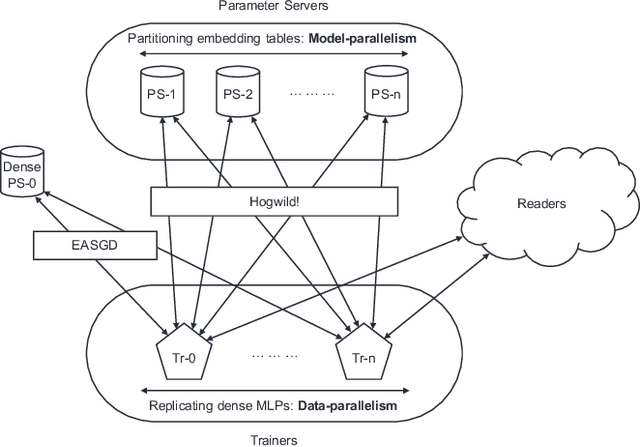
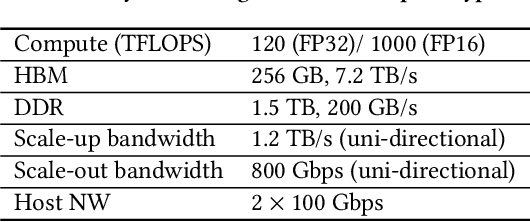
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of Zion platform, namely ZionEX. We demonstrate the capability to train very large DLRMs with up to 12 Trillion parameters and show that we can attain 40X speedup in terms of time to solution over previous systems. We achieve this by (i) designing the ZionEX platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.
Understanding Training Efficiency of Deep Learning Recommendation Models at Scale
Nov 11, 2020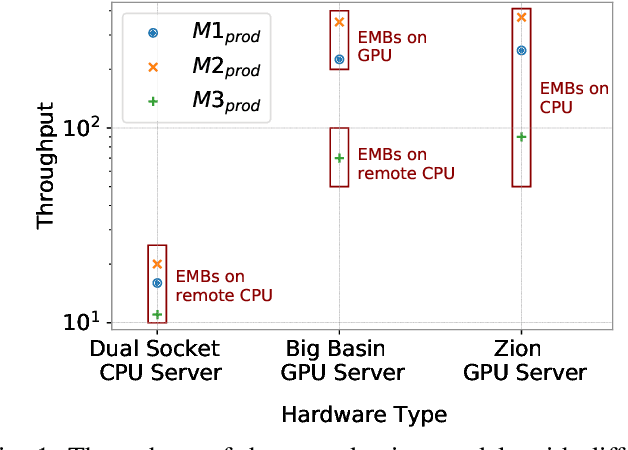
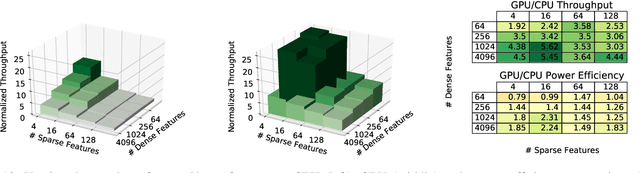
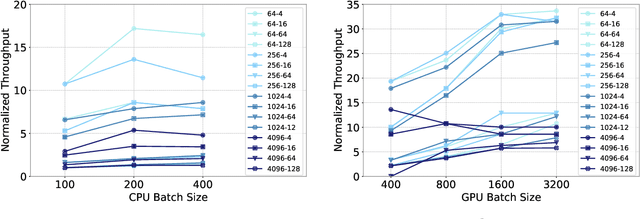
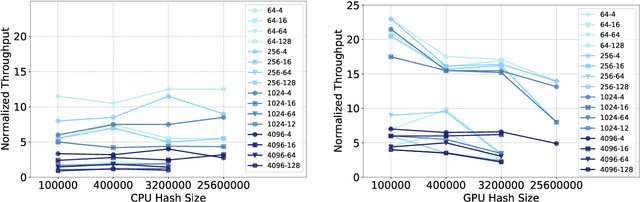
The use of GPUs has proliferated for machine learning workflows and is now considered mainstream for many deep learning models. Meanwhile, when training state-of-the-art personal recommendation models, which consume the highest number of compute cycles at our large-scale datacenters, the use of GPUs came with various challenges due to having both compute-intensive and memory-intensive components. GPU performance and efficiency of these recommendation models are largely affected by model architecture configurations such as dense and sparse features, MLP dimensions. Furthermore, these models often contain large embedding tables that do not fit into limited GPU memory. The goal of this paper is to explain the intricacies of using GPUs for training recommendation models, factors affecting hardware efficiency at scale, and learnings from a new scale-up GPU server design, Zion.