 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopFM: Learning frOm HistOrical RePresentations of Foundation Model for Recommendation
May 28, 2026Knowledge distillation (KD) transfers a single scalar prediction from a large foundation model (FM) to compact vertical models (VMs), suffering from diminishing transfer ratio -- the fraction of FM improvement captured by the VM -- as a single scalar cannot convey the rich intermediate knowledge that larger FMs learn. To address this bottleneck, we propose LoopFM (Learning frOm HistOrical ReP*resentations of FM), a framework that opens a high-bandwidth transfer channel by structuring FM intermediate embeddings as input features (e.g., user history sequence) for downstream VMs, without requiring real-time FM inference at serving and architectural coupling between FM and VM. We provide a theoretical framework for LoopFM with a gain decomposition and transfer-ratio analysis. On three public benchmarks, LoopFM demonstrates strong AUC improvements (e.g., 6\%+ on TaobaoAd) and complementary knowledge transfer capability with KD. On industrial-scale systems (billions of examples, trillion-parameter FMs), LoopFM approximately doubles the knowledge transfer ratio on top of KD, delivering a +0.5\% conversion improvement in Y1H1, and a +1.03\% and +1.22\% conversion improvement from two individual launches respectively in Y1H2.
Kunlun: Establishing Scaling Laws for Massive-Scale Recommendation Systems through Unified Architecture Design
Feb 13, 2026Deriving predictable scaling laws that govern the relationship between model performance and computational investment is crucial for designing and allocating resources in massive-scale recommendation systems. While such laws are established for large language models, they remain challenging for recommendation systems, especially those processing both user history and context features. We identify poor scaling efficiency as the main barrier to predictable power-law scaling, stemming from inefficient modules with low Model FLOPs Utilization (MFU) and suboptimal resource allocation. We introduce Kunlun, a scalable architecture that systematically improves model efficiency and resource allocation. Our low-level optimizations include Generalized Dot-Product Attention (GDPA), Hierarchical Seed Pooling (HSP), and Sliding Window Attention. Our high-level innovations feature Computation Skip (CompSkip) and Event-level Personalization. These advances increase MFU from 17% to 37% on NVIDIA B200 GPUs and double scaling efficiency over state-of-the-art methods. Kunlun is now deployed in major Meta Ads models, delivering significant production impact.
LOCA-bench: Benchmarking Language Agents Under Controllable and Extreme Context Growth
Feb 08, 2026Large language models (LLMs) are increasingly capable of carrying out long-running, real-world tasks. However, as the amount of context grows, their reliability often deteriorates, a phenomenon known as "context rot". Existing long-context benchmarks primarily focus on single-step settings that evaluate a model's ability to retrieve information from a long snippet. In realistic scenarios, however, LLMs often need to act as agents that explore environments, follow instructions and plans, extract useful information, and predict correct actions under a dynamically growing context. To assess language agents in such settings, we introduce LOCA-bench (a benchmark for LOng-Context Agents). Given a task prompt, LOCA-bench leverages automated and scalable control of environment states to regulate the agent's context length. This design enables LOCA-bench to extend the context length potentially to infinity in a controlled way while keeping the underlying task semantics fixed. LOCA-bench evaluates language agents as a combination of models and scaffolds, including various context management strategies. While agent performance generally degrades as the environment states grow more complex, advanced context management techniques can substantially improve the overall success rate. We open-source LOCA-bench to provide a platform for evaluating models and scaffolds in long-context, agentic scenarios: https://github.com/hkust-nlp/LOCA-bench
SWE-RM: Execution-free Feedback For Software Engineering Agents
Dec 26, 2025
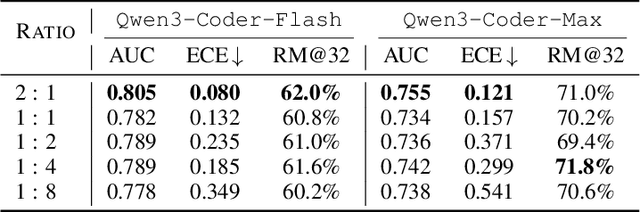

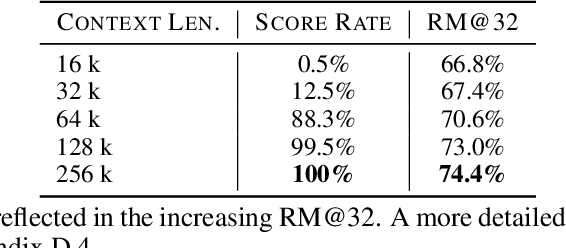
Execution-based feedback like unit testing is widely used in the development of coding agents through test-time scaling (TTS) and reinforcement learning (RL). This paradigm requires scalable and reliable collection of unit test cases to provide accurate feedback, and the resulting feedback is often sparse and cannot effectively distinguish between trajectories that are both successful or both unsuccessful. In contrast, execution-free feedback from reward models can provide more fine-grained signals without depending on unit test cases. Despite this potential, execution-free feedback for realistic software engineering (SWE) agents remains underexplored. Aiming to develop versatile reward models that are effective across TTS and RL, however, we observe that two verifiers with nearly identical TTS performance can nevertheless yield very different results in RL. Intuitively, TTS primarily reflects the model's ability to select the best trajectory, but this ability does not necessarily generalize to RL. To address this limitation, we identify two additional aspects that are crucial for RL training: classification accuracy and calibration. We then conduct comprehensive controlled experiments to investigate how to train a robust reward model that performs well across these metrics. In particular, we analyze the impact of various factors such as training data scale, policy mixtures, and data source composition. Guided by these investigations, we introduce SWE-RM, an accurate and robust reward model adopting a mixture-of-experts architecture with 30B total parameters and 3B activated during inference. SWE-RM substantially improves SWE agents on both TTS and RL performance. For example, it increases the accuracy of Qwen3-Coder-Flash from 51.6% to 62.0%, and Qwen3-Coder-Max from 67.0% to 74.6% on SWE-Bench Verified using TTS, achieving new state-of-the-art performance among open-source models.
The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution
Oct 29, 2025Real-world language agents must handle complex, multi-step workflows across diverse Apps. For instance, an agent may manage emails by coordinating with calendars and file systems, or monitor a production database to detect anomalies and generate reports following an operating manual. However, existing language agent benchmarks often focus on narrow domains or simplified tasks that lack the diversity, realism, and long-horizon complexity required to evaluate agents' real-world performance. To address this gap, we introduce the Tool Decathlon (dubbed as Toolathlon), a benchmark for language agents offering diverse Apps and tools, realistic environment setup, and reliable execution-based evaluation. Toolathlon spans 32 software applications and 604 tools, ranging from everyday platforms such as Google Calendar and Notion to professional ones like WooCommerce, Kubernetes, and BigQuery. Most of the tools are based on a high-quality set of Model Context Protocol (MCP) servers that we may have revised or implemented ourselves. Unlike prior works, which primarily ensure functional realism but offer limited environment state diversity, we provide realistic initial environment states from real software, such as Canvas courses with dozens of students or real financial spreadsheets. This benchmark includes 108 manually sourced or crafted tasks in total, requiring interacting with multiple Apps over around 20 turns on average to complete. Each task is strictly verifiable through dedicated evaluation scripts. Comprehensive evaluation of SOTA models highlights their significant shortcomings: the best-performing model, Claude-4.5-Sonnet, achieves only a 38.6% success rate with 20.2 tool calling turns on average, while the top open-weights model DeepSeek-V3.2-Exp reaches 20.1%. We expect Toolathlon to drive the development of more capable language agents for real-world, long-horizon task execution.
Pitfalls of Rule- and Model-based Verifiers -- A Case Study on Mathematical Reasoning
May 28, 2025Trustworthy verifiers are essential for the success of reinforcement learning with verifiable reward (RLVR), which is the core methodology behind various large reasoning models such as DeepSeek-R1. In complex domains like mathematical reasoning, rule-based verifiers have been widely adopted in previous works to train strong reasoning models. However, the reliability of these verifiers and their impact on the RL training process remain poorly understood. In this work, we take mathematical reasoning as a case study and conduct a comprehensive analysis of various verifiers in both static evaluation and RL training scenarios. First, we find that current open-source rule-based verifiers often fail to recognize equivalent answers presented in different formats across multiple commonly used mathematical datasets, resulting in non-negligible false negative rates. This limitation adversely affects RL training performance and becomes more pronounced as the policy model gets stronger. Subsequently, we investigate model-based verifiers as a potential solution to address these limitations. While the static evaluation shows that model-based verifiers achieve significantly higher verification accuracy, further analysis and RL training results imply that they are highly susceptible to hacking, where they misclassify certain patterns in responses as correct (i.e., false positives). This vulnerability is exploited during policy model optimization, leading to artificially inflated rewards. Our findings underscore the unique risks inherent to both rule-based and model-based verifiers, aiming to offer valuable insights to develop more robust reward systems in reinforcement learning.
Learn to Reason Efficiently with Adaptive Length-based Reward Shaping
May 21, 2025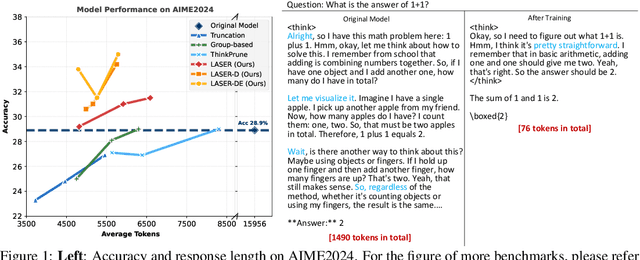
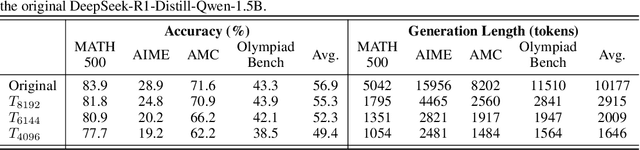
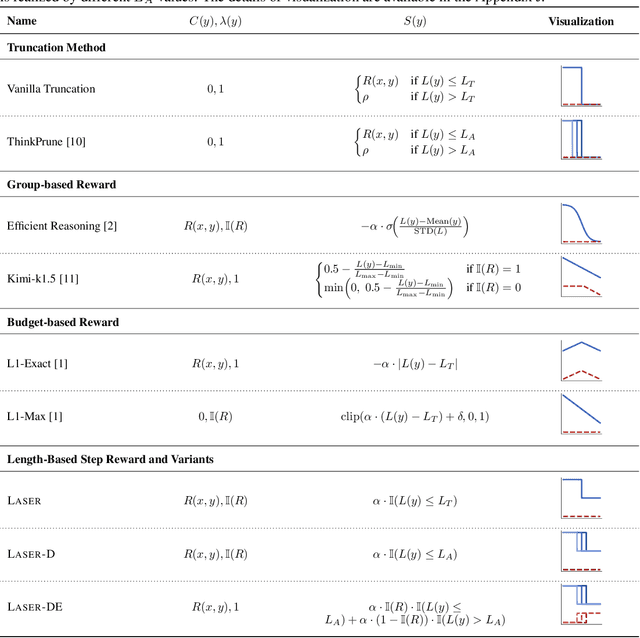
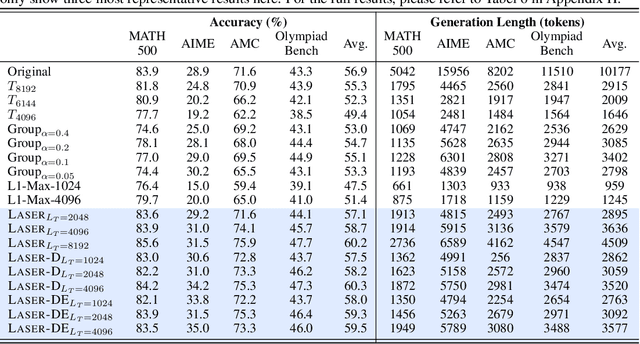
Large Reasoning Models (LRMs) have shown remarkable capabilities in solving complex problems through reinforcement learning (RL), particularly by generating long reasoning traces. However, these extended outputs often exhibit substantial redundancy, which limits the efficiency of LRMs. In this paper, we investigate RL-based approaches to promote reasoning efficiency. Specifically, we first present a unified framework that formulates various efficient reasoning methods through the lens of length-based reward shaping. Building on this perspective, we propose a novel Length-bAsed StEp Reward shaping method (LASER), which employs a step function as the reward, controlled by a target length. LASER surpasses previous methods, achieving a superior Pareto-optimal balance between performance and efficiency. Next, we further extend LASER based on two key intuitions: (1) The reasoning behavior of the model evolves during training, necessitating reward specifications that are also adaptive and dynamic; (2) Rather than uniformly encouraging shorter or longer chains of thought (CoT), we posit that length-based reward shaping should be difficulty-aware i.e., it should penalize lengthy CoTs more for easy queries. This approach is expected to facilitate a combination of fast and slow thinking, leading to a better overall tradeoff. The resulting method is termed LASER-D (Dynamic and Difficulty-aware). Experiments on DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, and DeepSeek-R1-Distill-Qwen-32B show that our approach significantly enhances both reasoning performance and response length efficiency. For instance, LASER-D and its variant achieve a +6.1 improvement on AIME2024 while reducing token usage by 63%. Further analysis reveals our RL-based compression produces more concise reasoning patterns with less redundant "self-reflections". Resources are at https://github.com/hkust-nlp/Laser.
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Mar 24, 2025DeepSeek-R1 has shown that long chain-of-thought (CoT) reasoning can naturally emerge through a simple reinforcement learning (RL) framework with rule-based rewards, where the training may directly start from the base models-a paradigm referred to as zero RL training. Most recent efforts to reproduce zero RL training have primarily focused on the Qwen2.5 model series, which may not be representative as we find the base models already exhibit strong instruction-following and self-reflection abilities. In this work, we investigate zero RL training across 10 diverse base models, spanning different families and sizes including LLama3-8B, Mistral-7B/24B, DeepSeek-Math-7B, Qwen2.5-math-7B, and all Qwen2.5 models from 0.5B to 32B. Leveraging several key design strategies-such as adjusting format reward and controlling query difficulty-we achieve substantial improvements in both reasoning accuracy and response length across most settings. However, by carefully monitoring the training dynamics, we observe that different base models exhibit distinct patterns during training. For instance, the increased response length does not always correlate with the emergence of certain cognitive behaviors such as verification (i.e., the "aha moment"). Notably, we observe the "aha moment" for the first time in small models not from the Qwen family. We share the key designs that enable successful zero RL training, along with our findings and practices. To facilitate further research, we open-source the code, models, and analysis tools.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
Movable Antenna Array Aided Ultra Reliable Covert Communications
Dec 29, 2024



In this paper, we construct a framework of the movable antenna (MA) aided covert communication shielded by the general noise uncertainty for the first time. According to the analysis performance on the derived closed-form expressions of the sum of the probabilities of the detection errors and the communication outage probability, the perfect covertness and the ultra reliability can be achieved by adjusting the antenna position in the MA array. Then, we formulate the communication covertness maximization problem with the constraints of the ultra reliability and the independent discrete movable position to optimize the transmitter's parameter. With the maximal ratio transmitting (MRT) design for the beamforming, we solve the closed-form optimal information transmit power and design a lightweight discrete projected gradient descent (DPGD) algorithm to determine the optimal antenna position. The numerical results show that the optimal achievable covertness and the feasible region of the steering angle with the MA array is significant larger than the one with the fixed-position antenna (FPA) array.