 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelecting Influential Samples for Long Context Alignment via Homologous Models' Guidance and Contextual Awareness Measurement
Oct 21, 2024The expansion of large language models to effectively handle instructions with extremely long contexts has yet to be fully investigated. The primary obstacle lies in constructing a high-quality long instruction-following dataset devised for long context alignment. Existing studies have attempted to scale up the available data volume by synthesizing long instruction-following samples. However, indiscriminately increasing the quantity of data without a well-defined strategy for ensuring data quality may introduce low-quality samples and restrict the final performance. To bridge this gap, we aim to address the unique challenge of long-context alignment, i.e., modeling the long-range dependencies for handling instructions and lengthy input contexts. We propose GATEAU, a novel framework designed to identify the influential and high-quality samples enriched with long-range dependency relations by utilizing crafted Homologous Models' Guidance (HMG) and Contextual Awareness Measurement (CAM). Specifically, HMG attempts to measure the difficulty of generating corresponding responses due to the long-range dependencies, using the perplexity scores of the response from two homologous models with different context windows. Also, the role of CAM is to measure the difficulty of understanding the long input contexts due to long-range dependencies by evaluating whether the model's attention is focused on important segments. Built upon both proposed methods, we select the most challenging samples as the influential data to effectively frame the long-range dependencies, thereby achieving better performance of LLMs. Comprehensive experiments indicate that GATEAU effectively identifies samples enriched with long-range dependency relations and the model trained on these selected samples exhibits better instruction-following and long-context understanding capabilities.
C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models
May 17, 2023



New NLP benchmarks are urgently needed to align with the rapid development of large language models (LLMs). We present C-Eval, the first comprehensive Chinese evaluation suite designed to assess advanced knowledge and reasoning abilities of foundation models in a Chinese context. C-Eval comprises multiple-choice questions across four difficulty levels: middle school, high school, college, and professional. The questions span 52 diverse disciplines, ranging from humanities to science and engineering. C-Eval is accompanied by C-Eval Hard, a subset of very challenging subjects in C-Eval that requires advanced reasoning abilities to solve. We conduct a comprehensive evaluation of the most advanced LLMs on C-Eval, including both English- and Chinese-oriented models. Results indicate that only GPT-4 could achieve an average accuracy of over 60%, suggesting that there is still significant room for improvement for current LLMs. We anticipate C-Eval will help analyze important strengths and shortcomings of foundation models, and foster their development and growth for Chinese users.
Sememe Prediction for BabelNet Synsets using Multilingual and Multimodal Information
Mar 14, 2022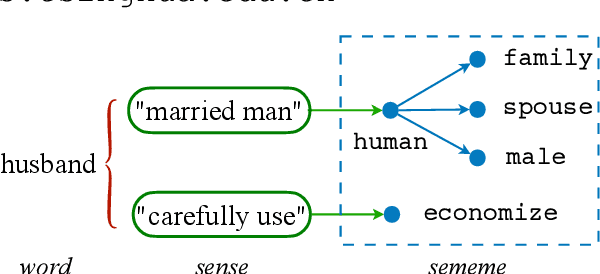
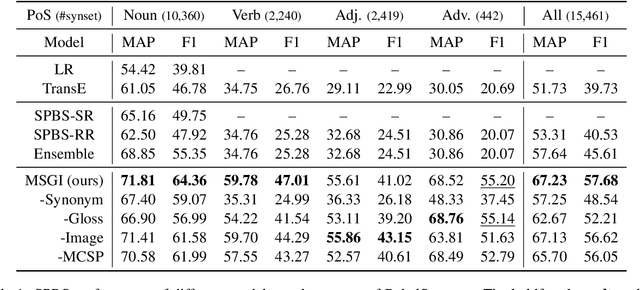


In linguistics, a sememe is defined as the minimum semantic unit of languages. Sememe knowledge bases (KBs), which are built by manually annotating words with sememes, have been successfully applied to various NLP tasks. However, existing sememe KBs only cover a few languages, which hinders the wide utilization of sememes. To address this issue, the task of sememe prediction for BabelNet synsets (SPBS) is presented, aiming to build a multilingual sememe KB based on BabelNet, a multilingual encyclopedia dictionary. By automatically predicting sememes for a BabelNet synset, the words in many languages in the synset would obtain sememe annotations simultaneously. However, previous SPBS methods have not taken full advantage of the abundant information in BabelNet. In this paper, we utilize the multilingual synonyms, multilingual glosses and images in BabelNet for SPBS. We design a multimodal information fusion model to encode and combine this information for sememe prediction. Experimental results show the substantial outperformance of our model over previous methods (about 10 MAP and F1 scores). All the code and data of this paper can be obtained at https://github.com/thunlp/MSGI.