 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeCaMIL: Causality-Aware Multiple Instance Learning for Fair and Interpretable Whole Slide Image Diagnosis
Nov 14, 2025Multiple instance learning (MIL) has emerged as the dominant paradigm for whole slide image (WSI) analysis in computational pathology, achieving strong diagnostic performance through patch-level feature aggregation. However, existing MIL methods face critical limitations: (1) they rely on attention mechanisms that lack causal interpretability, and (2) they fail to integrate patient demographics (age, gender, race), leading to fairness concerns across diverse populations. These shortcomings hinder clinical translation, where algorithmic bias can exacerbate health disparities. We introduce \textbf{MeCaMIL}, a causality-aware MIL framework that explicitly models demographic confounders through structured causal graphs. Unlike prior approaches treating demographics as auxiliary features, MeCaMIL employs principled causal inference -- leveraging do-calculus and collider structures -- to disentangle disease-relevant signals from spurious demographic correlations. Extensive evaluation on three benchmarks demonstrates state-of-the-art performance across CAMELYON16 (ACC/AUC/F1: 0.939/0.983/0.946), TCGA-Lung (0.935/0.979/0.931), and TCGA-Multi (0.977/0.993/0.970, five cancer types). Critically, MeCaMIL achieves superior fairness -- demographic disparity variance drops by over 65% relative reduction on average across attributes, with notable improvements for underserved populations. The framework generalizes to survival prediction (mean C-index: 0.653, +0.017 over best baseline across five cancer types). Ablation studies confirm causal graph structure is essential -- alternative designs yield 0.048 lower accuracy and 4.2x times worse fairness. These results establish MeCaMIL as a principled framework for fair, interpretable, and clinically actionable AI in digital pathology. Code will be released upon acceptance.
Two-Stage Decoupling Framework for Variable-Length Glaucoma Prognosis
Sep 15, 2025Glaucoma is one of the leading causes of irreversible blindness worldwide. Glaucoma prognosis is essential for identifying at-risk patients and enabling timely intervention to prevent blindness. Many existing approaches rely on historical sequential data but are constrained by fixed-length inputs, limiting their flexibility. Additionally, traditional glaucoma prognosis methods often employ end-to-end models, which struggle with the limited size of glaucoma datasets. To address these challenges, we propose a Two-Stage Decoupling Framework (TSDF) for variable-length glaucoma prognosis. In the first stage, we employ a feature representation module that leverages self-supervised learning to aggregate multiple glaucoma datasets for training, disregarding differences in their supervisory information. This approach enables datasets of varying sizes to learn better feature representations. In the second stage, we introduce a temporal aggregation module that incorporates an attention-based mechanism to process sequential inputs of varying lengths, ensuring flexible and efficient utilization of all available data. This design significantly enhances model performance while maintaining a compact parameter size. Extensive experiments on two benchmark glaucoma datasets:the Ocular Hypertension Treatment Study (OHTS) and the Glaucoma Real-world Appraisal Progression Ensemble (GRAPE),which differ significantly in scale and clinical settings,demonstrate the effectiveness and robustness of our approach.
Rethinking Layer-wise Gaussian Noise Injection: Bridging Implicit Objectives and Privacy Budget Allocation
Sep 04, 2025
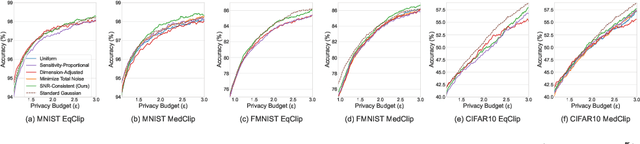
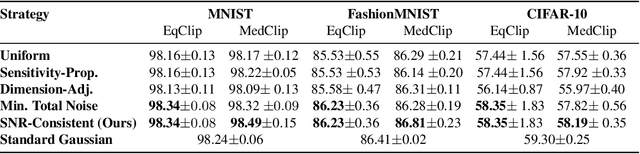
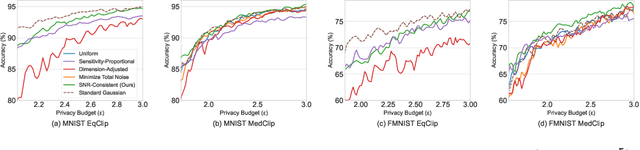
Layer-wise Gaussian mechanisms (LGM) enhance flexibility in differentially private deep learning by injecting noise into partitioned gradient vectors. However, existing methods often rely on heuristic noise allocation strategies, lacking a rigorous understanding of their theoretical grounding in connecting noise allocation to formal privacy-utility tradeoffs. In this paper, we present a unified analytical framework that systematically connects layer-wise noise injection strategies with their implicit optimization objectives and associated privacy budget allocations. Our analysis reveals that several existing approaches optimize ill-posed objectives -- either ignoring inter-layer signal-to-noise ratio (SNR) consistency or leading to inefficient use of the privacy budget. In response, we propose a SNR-Consistent noise allocation strategy that unifies both aspects, yielding a noise allocation scheme that achieves better signal preservation and more efficient privacy budget utilization. Extensive experiments in both centralized and federated learning settings demonstrate that our method consistently outperforms existing allocation strategies, achieving better privacy-utility tradeoffs. Our framework not only offers diagnostic insights into prior methods but also provides theoretical guidance for designing adaptive and effective noise injection schemes in deep models.
R-KV: Redundancy-aware KV Cache Compression for Training-Free Reasoning Models Acceleration
May 30, 2025Reasoning models have demonstrated impressive performance in self-reflection and chain-of-thought reasoning. However, they often produce excessively long outputs, leading to prohibitively large key-value (KV) caches during inference. While chain-of-thought inference significantly improves performance on complex reasoning tasks, it can also lead to reasoning failures when deployed with existing KV cache compression approaches. To address this, we propose Redundancy-aware KV Cache Compression for Reasoning models (R-KV), a novel method specifically targeting redundant tokens in reasoning models. Our method preserves nearly 100% of the full KV cache performance using only 10% of the KV cache, substantially outperforming existing KV cache baselines, which reach only 60% of the performance. Remarkably, R-KV even achieves 105% of full KV cache performance with 16% of the KV cache. This KV-cache reduction also leads to a 90% memory saving and a 6.6X throughput over standard chain-of-thought reasoning inference. Experimental results show that R-KV consistently outperforms existing KV cache compression baselines across two mathematical reasoning datasets.
Can LLMs Learn to Map the World from Local Descriptions?
May 27, 2025Recent advances in Large Language Models (LLMs) have demonstrated strong capabilities in tasks such as code and mathematics. However, their potential to internalize structured spatial knowledge remains underexplored. This study investigates whether LLMs, grounded in locally relative human observations, can construct coherent global spatial cognition by integrating fragmented relational descriptions. We focus on two core aspects of spatial cognition: spatial perception, where models infer consistent global layouts from local positional relationships, and spatial navigation, where models learn road connectivity from trajectory data and plan optimal paths between unconnected locations. Experiments conducted in a simulated urban environment demonstrate that LLMs not only generalize to unseen spatial relationships between points of interest (POIs) but also exhibit latent representations aligned with real-world spatial distributions. Furthermore, LLMs can learn road connectivity from trajectory descriptions, enabling accurate path planning and dynamic spatial awareness during navigation.
ARM: Adaptive Reasoning Model
May 26, 2025



While large reasoning models demonstrate strong performance on complex tasks, they lack the ability to adjust reasoning token usage based on task difficulty. This often leads to the "overthinking" problem -- excessive and unnecessary reasoning -- which, although potentially mitigated by human intervention to control the token budget, still fundamentally contradicts the goal of achieving fully autonomous AI. In this work, we propose Adaptive Reasoning Model (ARM), a reasoning model capable of adaptively selecting appropriate reasoning formats based on the task at hand. These formats include three efficient ones -- Direct Answer, Short CoT, and Code -- as well as a more elaborate format, Long CoT. To train ARM, we introduce Ada-GRPO, an adaptation of Group Relative Policy Optimization (GRPO), which addresses the format collapse issue in traditional GRPO. Ada-GRPO enables ARM to achieve high token efficiency, reducing tokens by an average of 30%, and up to 70%, while maintaining performance comparable to the model that relies solely on Long CoT. Furthermore, not only does it improve inference efficiency through reduced token generation, but it also brings a 2x speedup in training. In addition to the default Adaptive Mode, ARM supports two additional reasoning modes: 1) Instruction-Guided Mode, which allows users to explicitly specify the reasoning format via special tokens -- ideal when the appropriate format is known for a batch of tasks. 2) Consensus-Guided Mode, which aggregates the outputs of the three efficient formats and resorts to Long CoT in case of disagreement, prioritizing performance with higher token usage.
Covariate-dependent Graphical Model Estimation via Neural Networks with Statistical Guarantees
Apr 23, 2025Graphical models are widely used in diverse application domains to model the conditional dependencies amongst a collection of random variables. In this paper, we consider settings where the graph structure is covariate-dependent, and investigate a deep neural network-based approach to estimate it. The method allows for flexible functional dependency on the covariate, and fits the data reasonably well in the absence of a Gaussianity assumption. Theoretical results with PAC guarantees are established for the method, under assumptions commonly used in an Empirical Risk Minimization framework. The performance of the proposed method is evaluated on several synthetic data settings and benchmarked against existing approaches. The method is further illustrated on real datasets involving data from neuroscience and finance, respectively, and produces interpretable results.
The Lighthouse of Language: Enhancing LLM Agents via Critique-Guided Improvement
Mar 20, 2025Large language models (LLMs) have recently transformed from text-based assistants to autonomous agents capable of planning, reasoning, and iteratively improving their actions. While numerical reward signals and verifiers can effectively rank candidate actions, they often provide limited contextual guidance. In contrast, natural language feedback better aligns with the generative capabilities of LLMs, providing richer and more actionable suggestions. However, parsing and implementing this feedback effectively can be challenging for LLM-based agents. In this work, we introduce Critique-Guided Improvement (CGI), a novel two-player framework, comprising an actor model that explores an environment and a critic model that generates detailed nature language feedback. By training the critic to produce fine-grained assessments and actionable revisions, and the actor to utilize these critiques, our approach promotes more robust exploration of alternative strategies while avoiding local optima. Experiments in three interactive environments show that CGI outperforms existing baselines by a substantial margin. Notably, even a small critic model surpasses GPT-4 in feedback quality. The resulting actor achieves state-of-the-art performance, demonstrating the power of explicit iterative guidance to enhance decision-making in LLM-based agents.
PowerAttention: Exponentially Scaling of Receptive Fields for Effective Sparse Attention
Mar 05, 2025Large Language Models (LLMs) face efficiency bottlenecks due to the quadratic complexity of the attention mechanism when processing long contexts. Sparse attention methods offer a promising solution, but existing approaches often suffer from incomplete effective context and/or require complex implementation of pipeline. We present a comprehensive analysis of sparse attention for autoregressive LLMs from the respective of receptive field, recognize the suboptimal nature of existing methods for expanding the receptive field, and introduce PowerAttention, a novel sparse attention design that facilitates effective and complete context extension through the theoretical analysis. PowerAttention achieves exponential receptive field growth in $d$-layer LLMs, allowing each output token to attend to $2^d$ tokens, ensuring completeness and continuity of the receptive field. Experiments demonstrate that PowerAttention outperforms existing static sparse attention methods by $5\sim 40\%$, especially on tasks demanding long-range dependencies like Passkey Retrieval and RULER, while maintaining a comparable time complexity to sliding window attention. Efficiency evaluations further highlight PowerAttention's superior speedup in both prefilling and decoding phases compared with dynamic sparse attentions and full attention ($3.0\times$ faster on 128K context), making it a highly effective and user-friendly solution for processing long sequences in LLMs.
MCiteBench: A Benchmark for Multimodal Citation Text Generation in MLLMs
Mar 05, 2025Multimodal Large Language Models (MLLMs) have advanced in integrating diverse modalities but frequently suffer from hallucination. A promising solution to mitigate this issue is to generate text with citations, providing a transparent chain for verification. However, existing work primarily focuses on generating citations for text-only content, overlooking the challenges and opportunities of multimodal contexts. To address this gap, we introduce MCiteBench, the first benchmark designed to evaluate and analyze the multimodal citation text generation ability of MLLMs. Our benchmark comprises data derived from academic papers and review-rebuttal interactions, featuring diverse information sources and multimodal content. We comprehensively evaluate models from multiple dimensions, including citation quality, source reliability, and answer accuracy. Through extensive experiments, we observe that MLLMs struggle with multimodal citation text generation. We also conduct deep analyses of models' performance, revealing that the bottleneck lies in attributing the correct sources rather than understanding the multimodal content.