 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
Context Parallelism for Scalable Million-Token Inference
Nov 04, 2024



We present context parallelism for long-context large language model inference, which achieves near-linear scaling for long-context prefill latency with up to 128 H100 GPUs across 16 nodes. Particularly, our method achieves 1M context prefill with Llama3 405B model in 77s (93% parallelization efficiency, 63% FLOPS utilization) and 128K context prefill in 3.8s. We develop two lossless exact ring attention variants: pass-KV and pass-Q to cover a wide range of use cases with the state-of-the-art performance: full prefill, persistent KV prefill and decode. Benchmarks on H100 GPU hosts inter-connected with RDMA and TCP both show similar scalability for long-context prefill, demonstrating that our method scales well using common commercial data center with medium-to-low inter-host bandwidth.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Wukong: Towards a Scaling Law for Large-Scale Recommendation
Mar 08, 2024



Scaling laws play an instrumental role in the sustainable improvement in model quality. Unfortunately, recommendation models to date do not exhibit such laws similar to those observed in the domain of large language models, due to the inefficiencies of their upscaling mechanisms. This limitation poses significant challenges in adapting these models to increasingly more complex real-world datasets. In this paper, we propose an effective network architecture based purely on stacked factorization machines, and a synergistic upscaling strategy, collectively dubbed Wukong, to establish a scaling law in the domain of recommendation. Wukong's unique design makes it possible to capture diverse, any-order of interactions simply through taller and wider layers. We conducted extensive evaluations on six public datasets, and our results demonstrate that Wukong consistently outperforms state-of-the-art models quality-wise. Further, we assessed Wukong's scalability on an internal, large-scale dataset. The results show that Wukong retains its superiority in quality over state-of-the-art models, while holding the scaling law across two orders of magnitude in model complexity, extending beyond 100 Gflop or equivalently up to Large Language Model (GPT-3) training compute scale, where prior arts fall short.
Disaggregated Multi-Tower: Topology-aware Modeling Technique for Efficient Large-Scale Recommendation
Mar 07, 2024



We study a mismatch between the deep learning recommendation models' flat architecture, common distributed training paradigm and hierarchical data center topology. To address the associated inefficiencies, we propose Disaggregated Multi-Tower (DMT), a modeling technique that consists of (1) Semantic-preserving Tower Transform (SPTT), a novel training paradigm that decomposes the monolithic global embedding lookup process into disjoint towers to exploit data center locality; (2) Tower Module (TM), a synergistic dense component attached to each tower to reduce model complexity and communication volume through hierarchical feature interaction; and (3) Tower Partitioner (TP), a feature partitioner to systematically create towers with meaningful feature interactions and load balanced assignments to preserve model quality and training throughput via learned embeddings. We show that DMT can achieve up to 1.9x speedup compared to the state-of-the-art baselines without losing accuracy across multiple generations of hardware at large data center scales.
MTrainS: Improving DLRM training efficiency using heterogeneous memories
Apr 19, 2023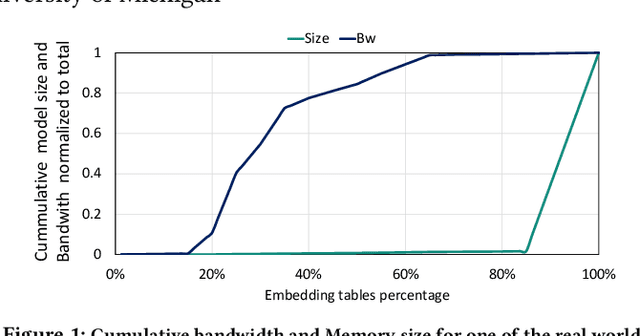
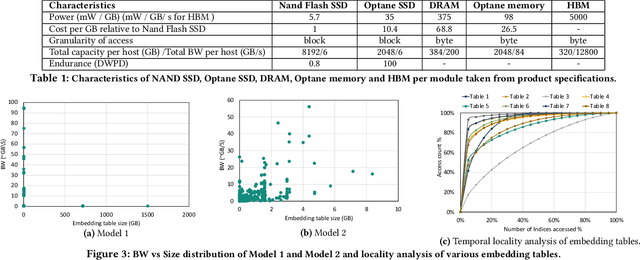
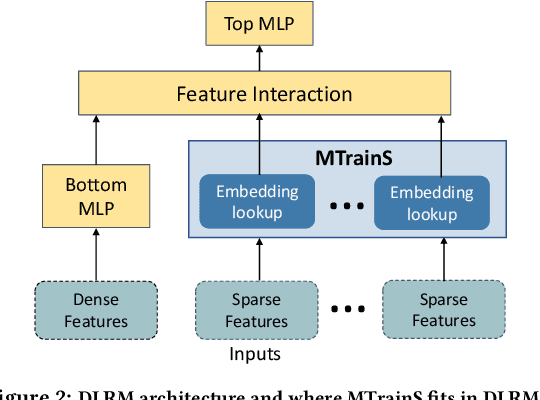

Recommendation models are very large, requiring terabytes (TB) of memory during training. In pursuit of better quality, the model size and complexity grow over time, which requires additional training data to avoid overfitting. This model growth demands a large number of resources in data centers. Hence, training efficiency is becoming considerably more important to keep the data center power demand manageable. In Deep Learning Recommendation Models (DLRM), sparse features capturing categorical inputs through embedding tables are the major contributors to model size and require high memory bandwidth. In this paper, we study the bandwidth requirement and locality of embedding tables in real-world deployed models. We observe that the bandwidth requirement is not uniform across different tables and that embedding tables show high temporal locality. We then design MTrainS, which leverages heterogeneous memory, including byte and block addressable Storage Class Memory for DLRM hierarchically. MTrainS allows for higher memory capacity per node and increases training efficiency by lowering the need to scale out to multiple hosts in memory capacity bound use cases. By optimizing the platform memory hierarchy, we reduce the number of nodes for training by 4-8X, saving power and cost of training while meeting our target training performance.
Shared Microexponents: A Little Shifting Goes a Long Way
Feb 16, 2023



This paper introduces Block Data Representations (BDR), a framework for exploring and evaluating a wide spectrum of narrow-precision formats for deep learning. It enables comparison of popular quantization standards, and through BDR, new formats based on shared microexponents (MX) are identified, which outperform other state-of-the-art quantization approaches, including narrow-precision floating-point and block floating-point. MX utilizes multiple levels of quantization scaling with ultra-fine scaling factors based on shared microexponents in the hardware. The effectiveness of MX is demonstrated on real-world models including large-scale generative pretraining and inferencing, and production-scale recommendation systems.
RecD: Deduplication for End-to-End Deep Learning Recommendation Model Training Infrastructure
Nov 14, 2022



We present RecD (Recommendation Deduplication), a suite of end-to-end infrastructure optimizations across the Deep Learning Recommendation Model (DLRM) training pipeline. RecD addresses immense storage, preprocessing, and training overheads caused by feature duplication inherent in industry-scale DLRM training datasets. Feature duplication arises because DLRM datasets are generated from interactions. While each user session can generate multiple training samples, many features' values do not change across these samples. We demonstrate how RecD exploits this property, end-to-end, across a deployed training pipeline. RecD optimizes data generation pipelines to decrease dataset storage and preprocessing resource demands and to maximize duplication within a training batch. RecD introduces a new tensor format, InverseKeyedJaggedTensors (IKJTs), to deduplicate feature values in each batch. We show how DLRM model architectures can leverage IKJTs to drastically increase training throughput. RecD improves the training and preprocessing throughput and storage efficiency by up to 2.49x, 1.79x, and 3.71x, respectively, in an industry-scale DLRM training system.
DHEN: A Deep and Hierarchical Ensemble Network for Large-Scale Click-Through Rate Prediction
Mar 11, 2022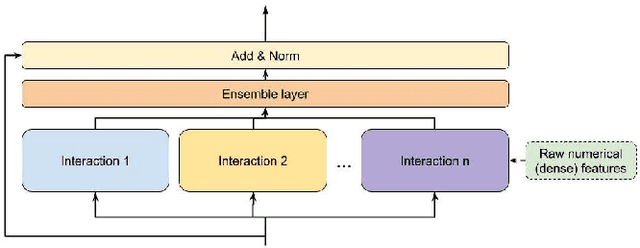
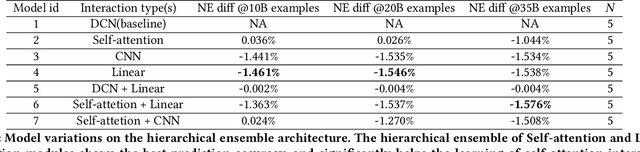
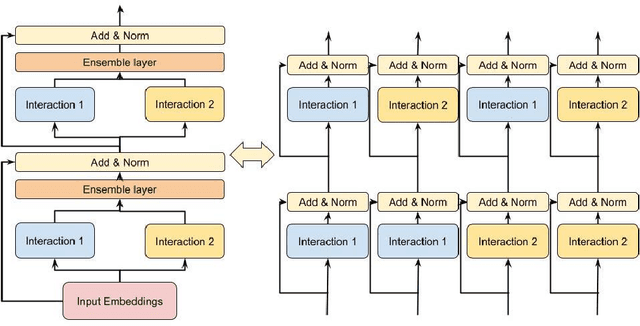

Learning feature interactions is important to the model performance of online advertising services. As a result, extensive efforts have been devoted to designing effective architectures to learn feature interactions. However, we observe that the practical performance of those designs can vary from dataset to dataset, even when the order of interactions claimed to be captured is the same. That indicates different designs may have different advantages and the interactions captured by them have non-overlapping information. Motivated by this observation, we propose DHEN - a deep and hierarchical ensemble architecture that can leverage strengths of heterogeneous interaction modules and learn a hierarchy of the interactions under different orders. To overcome the challenge brought by DHEN's deeper and multi-layer structure in training, we propose a novel co-designed training system that can further improve the training efficiency of DHEN. Experiments of DHEN on large-scale dataset from CTR prediction tasks attained 0.27\% improvement on the Normalized Entropy (NE) of prediction and 1.2x better training throughput than state-of-the-art baseline, demonstrating their effectiveness in practice.