 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Scaling Laws in Deep Neural Networks via Feature Learning Dynamics
Dec 24, 2025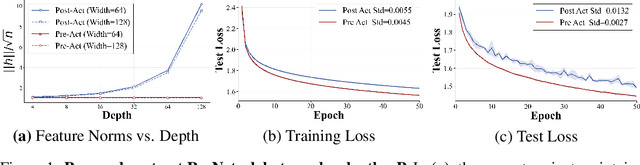


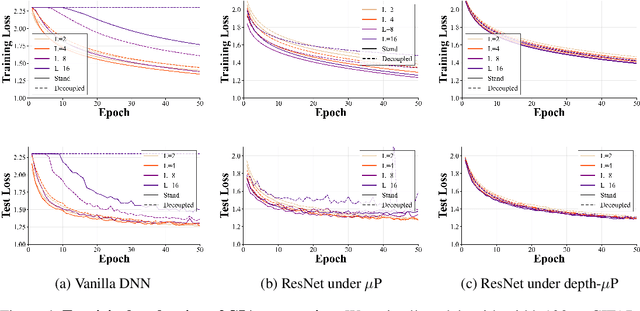
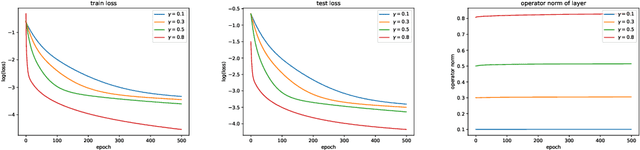
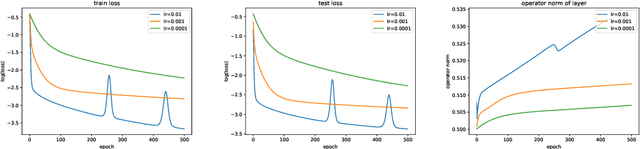
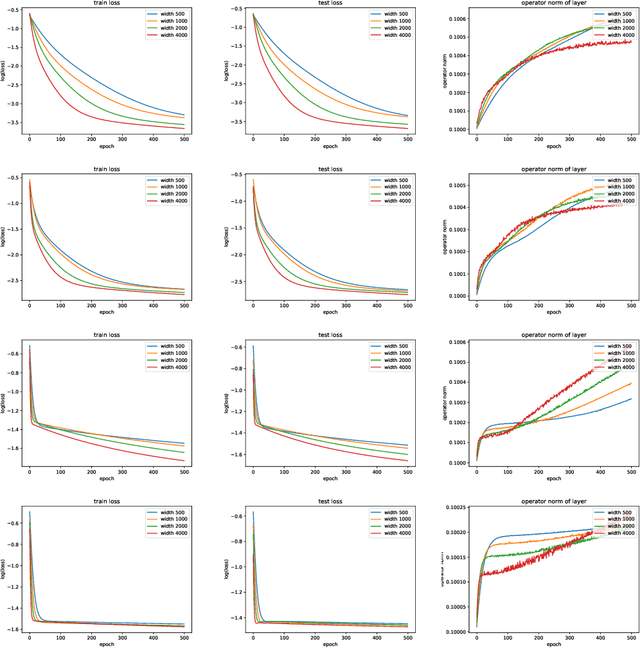
The empirical success of deep learning is often attributed to scaling laws that predict consistent gains as model, data, and compute grow; however, large models can exhibit training instability and diminishing returns, suggesting that scaling laws describe what success looks like but not when and why scaling succeeds or fails. A central obstacle is the lack of a rigorous understanding of feature learning at large depth. While muP characterizes feature-learning dynamics in the infinite-width limit and enables hyperparameter transfer across width, its depth extension (depth-muP) breaks down for residual blocks with more than one internal layer. We derive Neural Feature Dynamics (NFD) for ResNets with single-layer residual blocks, characterizing feature learning via a coupled forward-backward stochastic system in the joint infinite-width and infinite-depth limit. In this regime, NFD identifies when scaling-law trends persist and explains diminishing returns. It also reveals a vanishing mechanism induced by the 1/sqrt(depth) residual scaling under which the gradient-independence assumption (GIA), known to fail during training at finite depth, becomes provably valid again at infinite depth, yielding an analytically tractable regime for end-to-end feature learning. Motivated by this insight, we study two-layer residual blocks and show that the same mechanism causes feature-learning collapse in the first internal layer at large depth, providing a structural explanation for the empirical failure of depth-muP. Based on this diagnosis, we propose a depth-aware learning-rate correction that counteracts the collapse and empirically restores depth-wise hyperparameter transfer, yielding stronger performance in deeper ResNets.
Global Convergence in Neural ODEs: Impact of Activation Functions
Sep 26, 2025Neural Ordinary Differential Equations (ODEs) have been successful in various applications due to their continuous nature and parameter-sharing efficiency. However, these unique characteristics also introduce challenges in training, particularly with respect to gradient computation accuracy and convergence analysis. In this paper, we address these challenges by investigating the impact of activation functions. We demonstrate that the properties of activation functions, specifically smoothness and nonlinearity, are critical to the training dynamics. Smooth activation functions guarantee globally unique solutions for both forward and backward ODEs, while sufficient nonlinearity is essential for maintaining the spectral properties of the Neural Tangent Kernel (NTK) during training. Together, these properties enable us to establish the global convergence of Neural ODEs under gradient descent in overparameterized regimes. Our theoretical findings are validated by numerical experiments, which not only support our analysis but also provide practical guidelines for scaling Neural ODEs, potentially leading to faster training and improved performance in real-world applications.
Wide Neural Networks as Gaussian Processes: Lessons from Deep Equilibrium Models
Oct 16, 2023
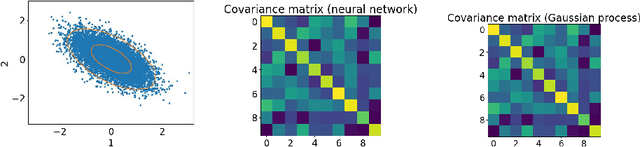


Neural networks with wide layers have attracted significant attention due to their equivalence to Gaussian processes, enabling perfect fitting of training data while maintaining generalization performance, known as benign overfitting. However, existing results mainly focus on shallow or finite-depth networks, necessitating a comprehensive analysis of wide neural networks with infinite-depth layers, such as neural ordinary differential equations (ODEs) and deep equilibrium models (DEQs). In this paper, we specifically investigate the deep equilibrium model (DEQ), an infinite-depth neural network with shared weight matrices across layers. Our analysis reveals that as the width of DEQ layers approaches infinity, it converges to a Gaussian process, establishing what is known as the Neural Network and Gaussian Process (NNGP) correspondence. Remarkably, this convergence holds even when the limits of depth and width are interchanged, which is not observed in typical infinite-depth Multilayer Perceptron (MLP) networks. Furthermore, we demonstrate that the associated Gaussian vector remains non-degenerate for any pairwise distinct input data, ensuring a strictly positive smallest eigenvalue of the corresponding kernel matrix using the NNGP kernel. These findings serve as fundamental elements for studying the training and generalization of DEQs, laying the groundwork for future research in this area.
On the optimization and generalization of overparameterized implicit neural networks
Sep 30, 2022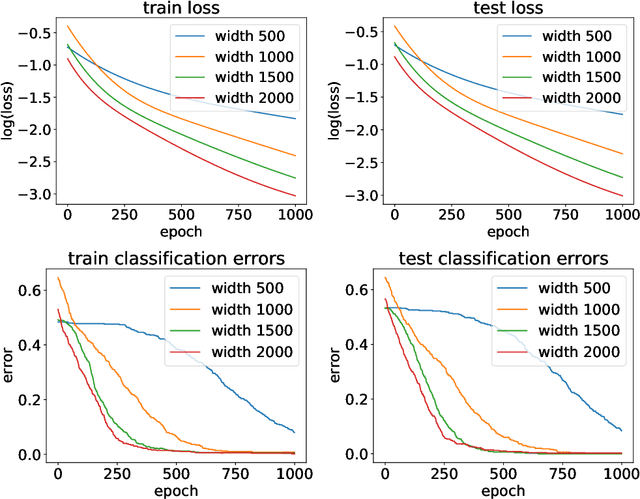
Implicit neural networks have become increasingly attractive in the machine learning community since they can achieve competitive performance but use much less computational resources. Recently, a line of theoretical works established the global convergences for first-order methods such as gradient descent if the implicit networks are over-parameterized. However, as they train all layers together, their analyses are equivalent to only studying the evolution of the output layer. It is unclear how the implicit layer contributes to the training. Thus, in this paper, we restrict ourselves to only training the implicit layer. We show that global convergence is guaranteed, even if only the implicit layer is trained. On the other hand, the theoretical understanding of when and how the training performance of an implicit neural network can be generalized to unseen data is still under-explored. Although this problem has been studied in standard feed-forward networks, the case of implicit neural networks is still intriguing since implicit networks theoretically have infinitely many layers. Therefore, this paper investigates the generalization error for implicit neural networks. Specifically, we study the generalization of an implicit network activated by the ReLU function over random initialization. We provide a generalization bound that is initialization sensitive. As a result, we show that gradient flow with proper random initialization can train a sufficient over-parameterized implicit network to achieve arbitrarily small generalization errors.
Gradient Descent Optimizes Infinite-Depth ReLU Implicit Networks with Linear Widths
May 16, 2022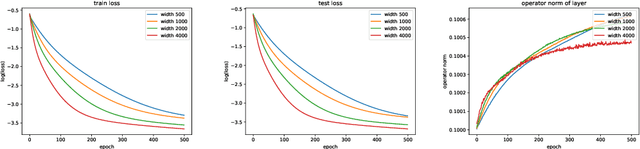
Implicit deep learning has recently become popular in the machine learning community since these implicit models can achieve competitive performance with state-of-the-art deep networks while using significantly less memory and computational resources. However, our theoretical understanding of when and how first-order methods such as gradient descent (GD) converge on \textit{nonlinear} implicit networks is limited. Although this type of problem has been studied in standard feed-forward networks, the case of implicit models is still intriguing because implicit networks have \textit{infinitely} many layers. The corresponding equilibrium equation probably admits no or multiple solutions during training. This paper studies the convergence of both gradient flow (GF) and gradient descent for nonlinear ReLU activated implicit networks. To deal with the well-posedness problem, we introduce a fixed scalar to scale the weight matrix of the implicit layer and show that there exists a small enough scaling constant, keeping the equilibrium equation well-posed throughout training. As a result, we prove that both GF and GD converge to a global minimum at a linear rate if the width $m$ of the implicit network is \textit{linear} in the sample size $N$, i.e., $m=\Omega(N)$.
A global convergence theory for deep ReLU implicit networks via over-parameterization
Oct 11, 2021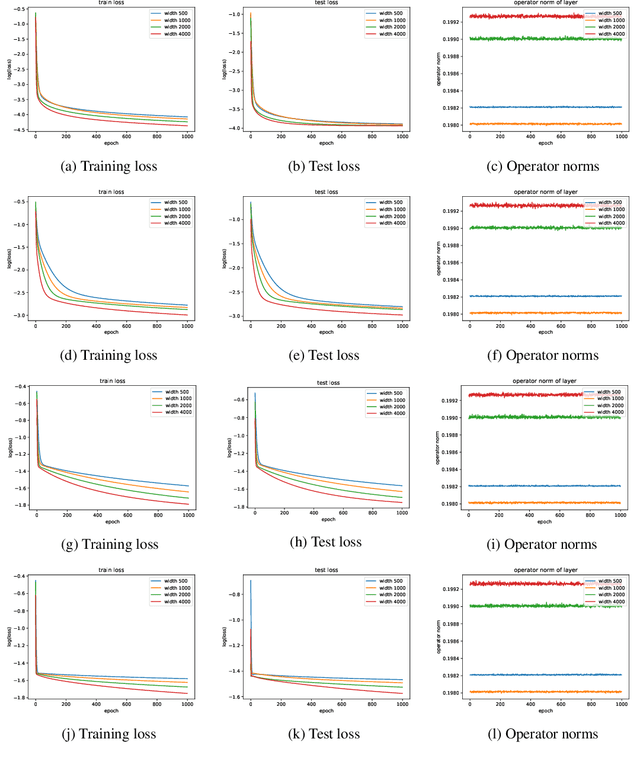
Implicit deep learning has received increasing attention recently due to the fact that it generalizes the recursive prediction rules of many commonly used neural network architectures. Its prediction rule is provided implicitly based on the solution of an equilibrium equation. Although a line of recent empirical studies has demonstrated its superior performances, the theoretical understanding of implicit neural networks is limited. In general, the equilibrium equation may not be well-posed during the training. As a result, there is no guarantee that a vanilla (stochastic) gradient descent (SGD) training nonlinear implicit neural networks can converge. This paper fills the gap by analyzing the gradient flow of Rectified Linear Unit (ReLU) activated implicit neural networks. For an $m$-width implicit neural network with ReLU activation and $n$ training samples, we show that a randomly initialized gradient descent converges to a global minimum at a linear rate for the square loss function if the implicit neural network is \textit{over-parameterized}. It is worth noting that, unlike existing works on the convergence of (S)GD on finite-layer over-parameterized neural networks, our convergence results hold for implicit neural networks, where the number of layers is \textit{infinite}.
Alternate Model Growth and Pruning for Efficient Training of Recommendation Systems
May 04, 2021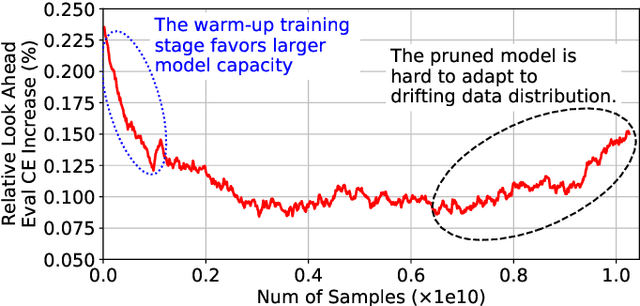
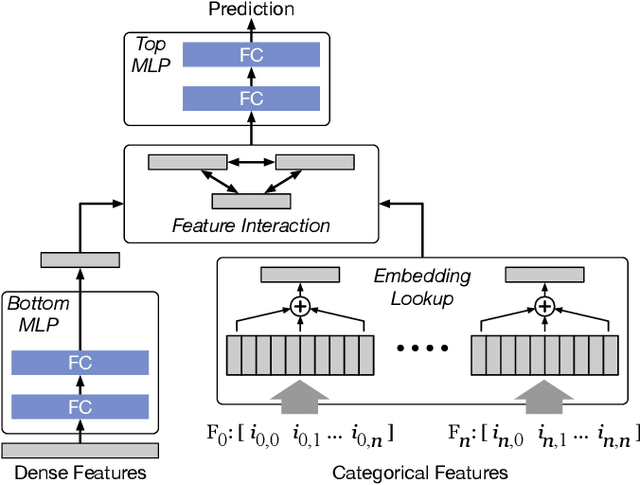
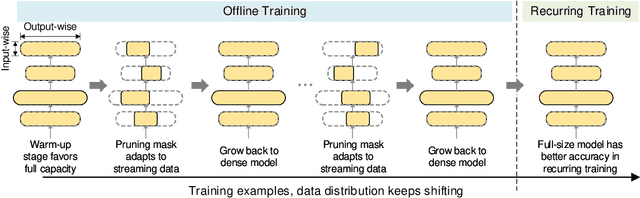
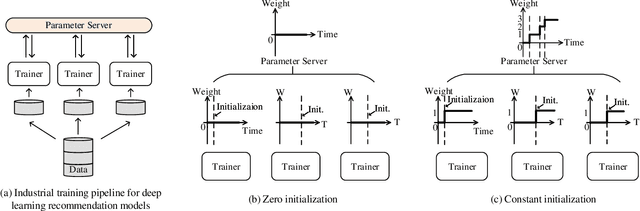
Deep learning recommendation systems at scale have provided remarkable gains through increasing model capacity (i.e. wider and deeper neural networks), but it comes at significant training cost and infrastructure cost. Model pruning is an effective technique to reduce computation overhead for deep neural networks by removing redundant parameters. However, modern recommendation systems are still thirsty for model capacity due to the demand for handling big data. Thus, pruning a recommendation model at scale results in a smaller model capacity and consequently lower accuracy. To reduce computation cost without sacrificing model capacity, we propose a dynamic training scheme, namely alternate model growth and pruning, to alternatively construct and prune weights in the course of training. Our method leverages structured sparsification to reduce computational cost without hurting the model capacity at the end of offline training so that a full-size model is available in the recurring training stage to learn new data in real-time. To the best of our knowledge, this is the first work to provide in-depth experiments and discussion of applying structural dynamics to recommendation systems at scale to reduce training cost. The proposed method is validated with an open-source deep-learning recommendation model (DLRM) and state-of-the-art industrial-scale production models.
Randomized Bregman Coordinate Descent Methods for Non-Lipschitz Optimization
Jan 15, 2020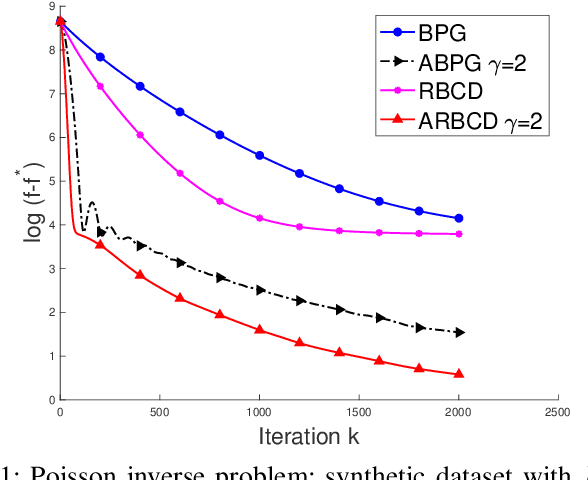
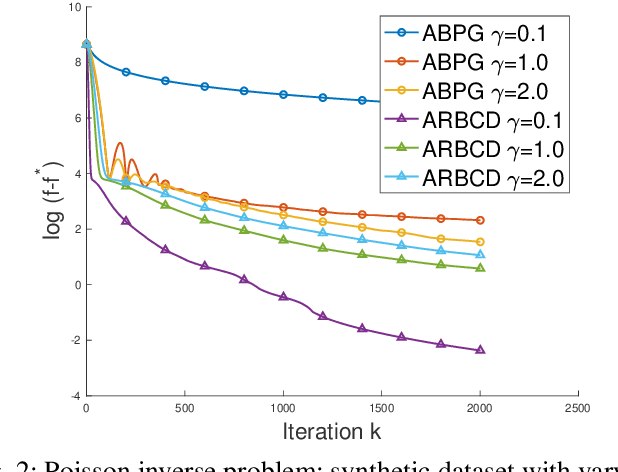
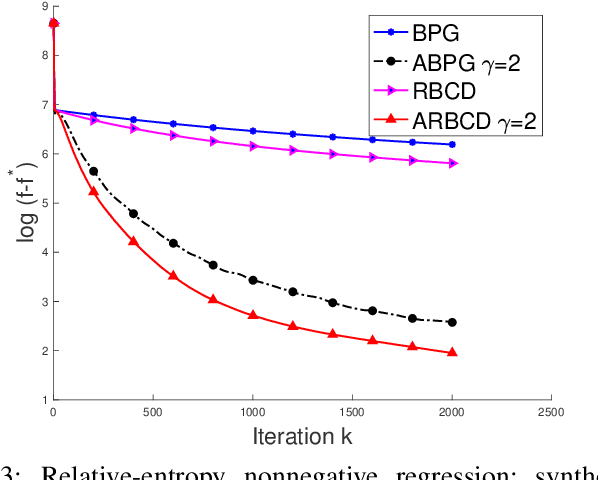
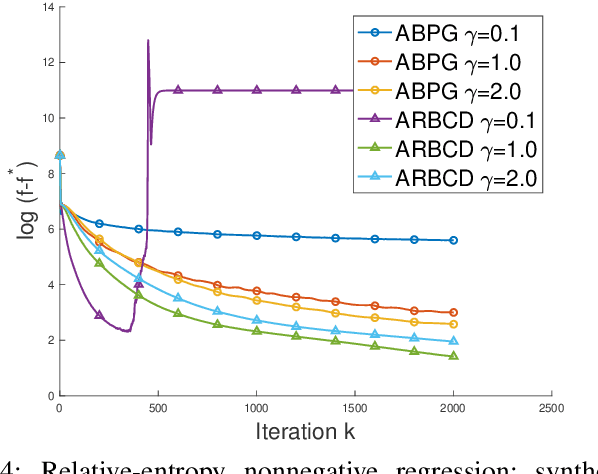
We propose a new \textit{randomized Bregman (block) coordinate descent} (RBCD) method for minimizing a composite problem, where the objective function could be either convex or nonconvex, and the smooth part are freed from the global Lipschitz-continuous (partial) gradient assumption. Under the notion of relative smoothness based on the Bregman distance, we prove that every limit point of the generated sequence is a stationary point. Further, we show that the iteration complexity of the proposed method is $O(n\varepsilon^{-2})$ to achieve $\epsilon$-stationary point, where $n$ is the number of blocks of coordinates. If the objective is assumed to be convex, the iteration complexity is improved to $O(n\epsilon^{-1} )$. If, in addition, the objective is strongly convex (relative to the reference function), the global linear convergence rate is recovered. We also present the accelerated version of the RBCD method, which attains an $O(n\varepsilon^{-1/\gamma} )$ iteration complexity for the convex case, where the scalar $\gamma\in [1,2]$ is determined by the \textit{generalized translation variant} of the Bregman distance. Convergence analysis without assuming the global Lipschitz-continuous (partial) gradient sets our results apart from the existing works in the composite problems.
Leveraging Two Reference Functions in Block Bregman Proximal Gradient Descent for Non-convex and Non-Lipschitz Problems
Dec 16, 2019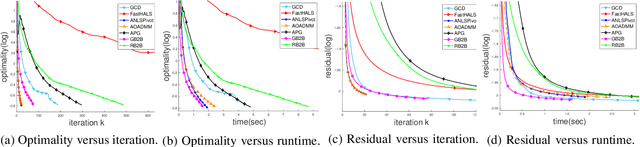
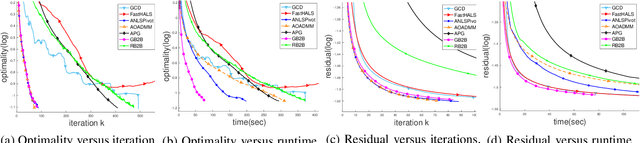
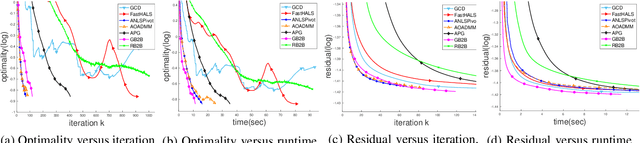
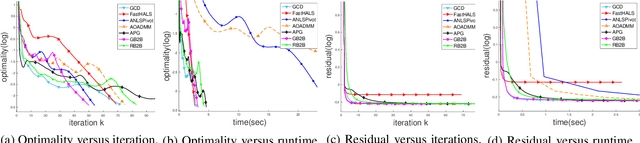
In the applications of signal processing and data analytics, there is a wide class of non-convex problems whose objective function is freed from the common global Lipschitz continuous gradient assumption (e.g., the nonnegative matrix factorization (NMF) problem). Recently, this type of problem with some certain special structures has been solved by Bregman proximal gradient (BPG). This inspires us to propose a new Block-wise two-references Bregman proximal gradient (B2B) method, which adopts two reference functions so that a closed-form solution in the Bregman projection is obtained. Based on the relative smoothness, we prove the global convergence of the proposed algorithms for various block selection rules. In particular, we establish the global convergence rate of $O(\frac{\sqrt{s}}{\sqrt{k}})$ for the greedy and randomized block updating rule for B2B, which is $O(\sqrt{s})$ times faster than the cyclic variant, i.e., $O(\frac{s}{\sqrt{k}} )$, where $s$ is the number of blocks, and $k$ is the number of iterations. Multiple numerical results are provided to illustrate the superiority of the proposed B2B compared to the state-of-the-art works in solving NMF problems.
A Forest from the Trees: Generation through Neighborhoods
Feb 04, 2019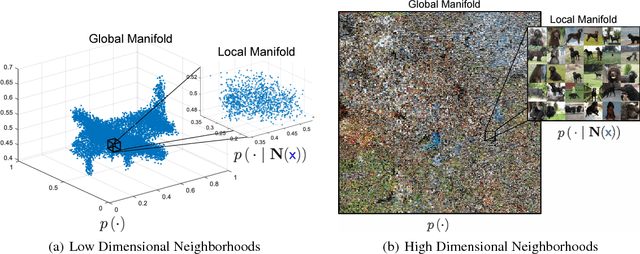
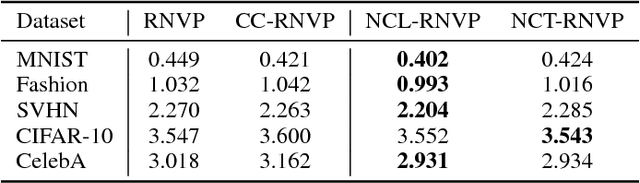
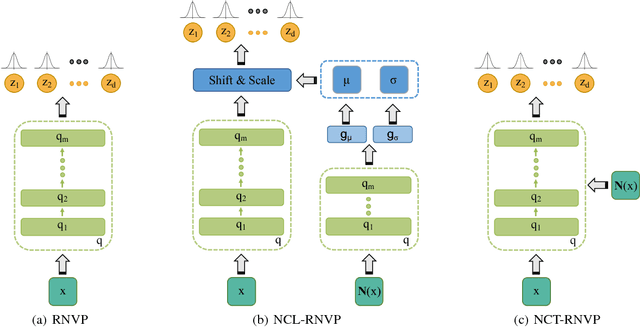
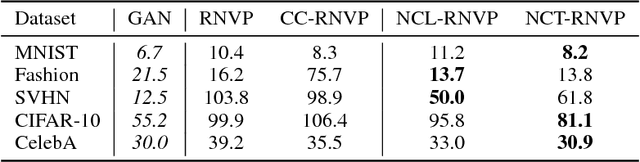
In this work, we propose to learn a generative model using both learned features (through a latent space) and memories (through neighbors). Although human learning makes seamless use of both learned perceptual features and instance recall, current generative learning paradigms only make use of one of these two components. Take, for instance, flow models, which learn a latent space of invertible features that follow a simple distribution. Conversely, kernel density techniques use instances to shift a simple distribution into an aggregate mixture model. Here we propose multiple methods to enhance the latent space of a flow model with neighborhood information. Not only does our proposed framework represent a more human-like approach by leveraging both learned features and memories, but it may also be viewed as a step forward in non-parametric methods. The efficacy of our model is shown empirically with standard image datasets. We observe compelling results and a significant improvement over baselines.