 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Quantifying How Pre-Training and Context Benefit In-Context Learning
Oct 26, 2025Pre-trained large language models have demonstrated a strong ability to learn from context, known as in-context learning (ICL). Despite a surge of recent applications that leverage such capabilities, it is by no means clear, at least theoretically, how the ICL capabilities arise, and in particular, what is the precise role played by key factors such as pre-training procedure as well as context construction. In this work, we propose a new framework to analyze the ICL performance, for a class of realistic settings, which includes network architectures, data encoding, data generation, and prompt construction process. As a first step, we construct a simple example with a one-layer transformer, and show an interesting result, namely when the pre-train data distribution is different from the query task distribution, a properly constructed context can shift the output distribution towards the query task distribution, in a quantifiable manner, leading to accurate prediction on the query topic. We then extend the findings in the previous step to a more general case, and derive the precise relationship between ICL performance, context length and the KL divergence between pre-train and query task distribution. Finally, we provide experiments to validate our theoretical results.
Q-function Decomposition with Intervention Semantics with Factored Action Spaces
Apr 30, 2025Many practical reinforcement learning environments have a discrete factored action space that induces a large combinatorial set of actions, thereby posing significant challenges. Existing approaches leverage the regular structure of the action space and resort to a linear decomposition of Q-functions, which avoids enumerating all combinations of factored actions. In this paper, we consider Q-functions defined over a lower dimensional projected subspace of the original action space, and study the condition for the unbiasedness of decomposed Q-functions using causal effect estimation from the no unobserved confounder setting in causal statistics. This leads to a general scheme which we call action decomposed reinforcement learning that uses the projected Q-functions to approximate the Q-function in standard model-free reinforcement learning algorithms. The proposed approach is shown to improve sample complexity in a model-based reinforcement learning setting. We demonstrate improvements in sample efficiency compared to state-of-the-art baselines in online continuous control environments and a real-world offline sepsis treatment environment.
Bilevel Joint Unsupervised and Supervised Training for Automatic Speech Recognition
Dec 11, 2024In this paper, we propose a bilevel joint unsupervised and supervised training (BL-JUST) framework for automatic speech recognition. Compared to the conventional pre-training and fine-tuning strategy which is a disconnected two-stage process, BL-JUST tries to optimize an acoustic model such that it simultaneously minimizes both the unsupervised and supervised loss functions. Because BL-JUST seeks matched local optima of both loss functions, acoustic representations learned by the acoustic model strike a good balance between being generic and task-specific. We solve the BL-JUST problem using penalty-based bilevel gradient descent and evaluate the trained deep neural network acoustic models on various datasets with a variety of architectures and loss functions. We show that BL-JUST can outperform the widely-used pre-training and fine-tuning strategy and some other popular semi-supervised techniques.
SPARKLE: A Unified Single-Loop Primal-Dual Framework for Decentralized Bilevel Optimization
Nov 21, 2024This paper studies decentralized bilevel optimization, in which multiple agents collaborate to solve problems involving nested optimization structures with neighborhood communications. Most existing literature primarily utilizes gradient tracking to mitigate the influence of data heterogeneity, without exploring other well-known heterogeneity-correction techniques such as EXTRA or Exact Diffusion. Additionally, these studies often employ identical decentralized strategies for both upper- and lower-level problems, neglecting to leverage distinct mechanisms across different levels. To address these limitations, this paper proposes SPARKLE, a unified Single-loop Primal-dual AlgoRithm frameworK for decentraLized bilEvel optimization. SPARKLE offers the flexibility to incorporate various heterogeneitycorrection strategies into the algorithm. Moreover, SPARKLE allows for different strategies to solve upper- and lower-level problems. We present a unified convergence analysis for SPARKLE, applicable to all its variants, with state-of-the-art convergence rates compared to existing decentralized bilevel algorithms. Our results further reveal that EXTRA and Exact Diffusion are more suitable for decentralized bilevel optimization, and using mixed strategies in bilevel algorithms brings more benefits than relying solely on gradient tracking.
Training Nonlinear Transformers for Chain-of-Thought Inference: A Theoretical Generalization Analysis
Oct 03, 2024
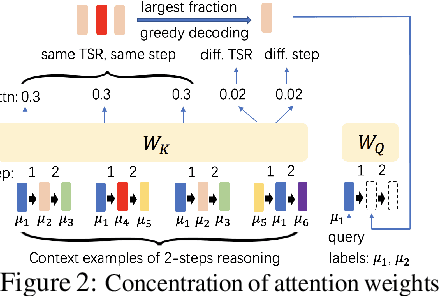
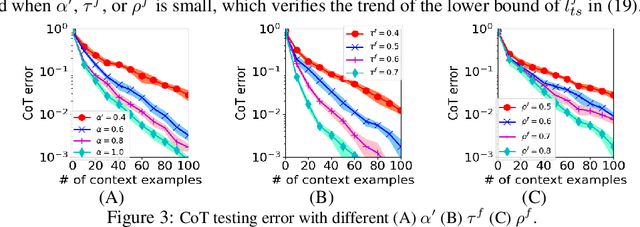
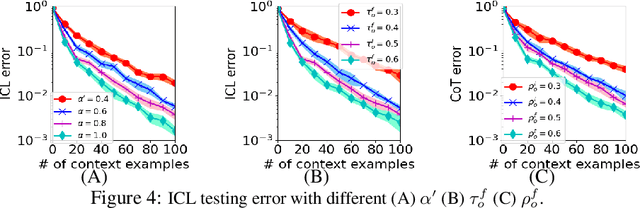
Chain-of-Thought (CoT) is an efficient prompting method that enables the reasoning ability of large language models by augmenting the query using multiple examples with multiple intermediate steps. Despite the empirical success, the theoretical understanding of how to train a Transformer to achieve the CoT ability remains less explored. This is primarily due to the technical challenges involved in analyzing the nonconvex optimization on nonlinear attention models. To the best of our knowledge, this work provides the first theoretical study of training Transformers with nonlinear attention to obtain the CoT generalization capability so that the resulting model can inference on unseen tasks when the input is augmented by examples of the new task. We first quantify the required training samples and iterations to train a Transformer model towards CoT ability. We then prove the success of its CoT generalization on unseen tasks with distribution-shifted testing data. Moreover, we theoretically characterize the conditions for an accurate reasoning output by CoT even when the provided reasoning examples contain noises and are not always accurate. In contrast, in-context learning (ICL), which can be viewed as one-step CoT without intermediate steps, may fail to provide an accurate output when CoT does. These theoretical findings are justified through experiments.
FADAS: Towards Federated Adaptive Asynchronous Optimization
Jul 25, 2024
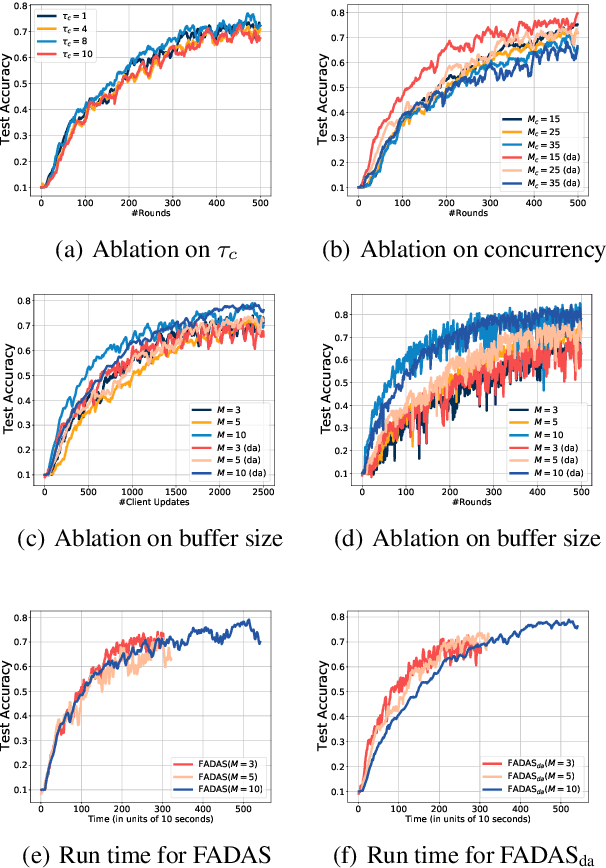

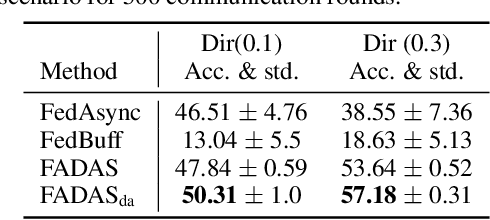
Federated learning (FL) has emerged as a widely adopted training paradigm for privacy-preserving machine learning. While the SGD-based FL algorithms have demonstrated considerable success in the past, there is a growing trend towards adopting adaptive federated optimization methods, particularly for training large-scale models. However, the conventional synchronous aggregation design poses a significant challenge to the practical deployment of those adaptive federated optimization methods, particularly in the presence of straggler clients. To fill this research gap, this paper introduces federated adaptive asynchronous optimization, named FADAS, a novel method that incorporates asynchronous updates into adaptive federated optimization with provable guarantees. To further enhance the efficiency and resilience of our proposed method in scenarios with significant asynchronous delays, we also extend FADAS with a delay-adaptive learning adjustment strategy. We rigorously establish the convergence rate of the proposed algorithms and empirical results demonstrate the superior performance of FADAS over other asynchronous FL baselines.
Byzantine-Robust Decentralized Federated Learning
Jun 18, 2024



Federated learning (FL) enables multiple clients to collaboratively train machine learning models without revealing their private training data. In conventional FL, the system follows the server-assisted architecture (server-assisted FL), where the training process is coordinated by a central server. However, the server-assisted FL framework suffers from poor scalability due to a communication bottleneck at the server, and trust dependency issues. To address challenges, decentralized federated learning (DFL) architecture has been proposed to allow clients to train models collaboratively in a serverless and peer-to-peer manner. However, due to its fully decentralized nature, DFL is highly vulnerable to poisoning attacks, where malicious clients could manipulate the system by sending carefully-crafted local models to their neighboring clients. To date, only a limited number of Byzantine-robust DFL methods have been proposed, most of which are either communication-inefficient or remain vulnerable to advanced poisoning attacks. In this paper, we propose a new algorithm called BALANCE (Byzantine-robust averaging through local similarity in decentralization) to defend against poisoning attacks in DFL. In BALANCE, each client leverages its own local model as a similarity reference to determine if the received model is malicious or benign. We establish the theoretical convergence guarantee for BALANCE under poisoning attacks in both strongly convex and non-convex settings. Furthermore, the convergence rate of BALANCE under poisoning attacks matches those of the state-of-the-art counterparts in Byzantine-free settings. Extensive experiments also demonstrate that BALANCE outperforms existing DFL methods and effectively defends against poisoning attacks.
SF-DQN: Provable Knowledge Transfer using Successor Feature for Deep Reinforcement Learning
May 24, 2024
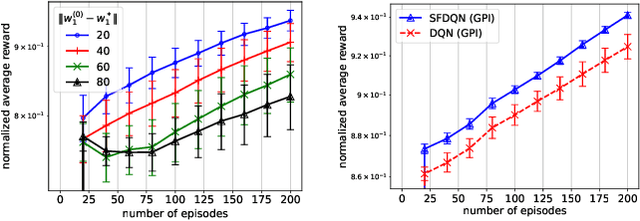


This paper studies the transfer reinforcement learning (RL) problem where multiple RL problems have different reward functions but share the same underlying transition dynamics. In this setting, the Q-function of each RL problem (task) can be decomposed into a successor feature (SF) and a reward mapping: the former characterizes the transition dynamics, and the latter characterizes the task-specific reward function. This Q-function decomposition, coupled with a policy improvement operator known as generalized policy improvement (GPI), reduces the sample complexity of finding the optimal Q-function, and thus the SF \& GPI framework exhibits promising empirical performance compared to traditional RL methods like Q-learning. However, its theoretical foundations remain largely unestablished, especially when learning the successor features using deep neural networks (SF-DQN). This paper studies the provable knowledge transfer using SFs-DQN in transfer RL problems. We establish the first convergence analysis with provable generalization guarantees for SF-DQN with GPI. The theory reveals that SF-DQN with GPI outperforms conventional RL approaches, such as deep Q-network, in terms of both faster convergence rate and better generalization. Numerical experiments on real and synthetic RL tasks support the superior performance of SF-DQN \& GPI, aligning with our theoretical findings.
Training Nonlinear Transformers for Efficient In-Context Learning: A Theoretical Learning and Generalization Analysis
Feb 23, 2024Transformer-based large language models have displayed impressive in-context learning capabilities, where a pre-trained model can handle new tasks without fine-tuning by simply augmenting the query with some input-output examples from that task. Despite the empirical success, the mechanics of how to train a Transformer to achieve ICL and the corresponding ICL capacity is mostly elusive due to the technical challenges of analyzing the nonconvex training problems resulting from the nonlinear self-attention and nonlinear activation in Transformers. To the best of our knowledge, this paper provides the first theoretical analysis of the training dynamics of Transformers with nonlinear self-attention and nonlinear MLP, together with the ICL generalization capability of the resulting model. Focusing on a group of binary classification tasks, we train Transformers using data from a subset of these tasks and quantify the impact of various factors on the ICL generalization performance on the remaining unseen tasks with and without data distribution shifts. We also analyze how different components in the learned Transformers contribute to the ICL performance. Furthermore, we provide the first theoretical analysis of how model pruning affects the ICL performance and prove that proper magnitude-based pruning can have a minimal impact on ICL while reducing inference costs. These theoretical findings are justified through numerical experiments.
Decentralized Bilevel Optimization over Graphs: Loopless Algorithmic Update and Transient Iteration Complexity
Feb 05, 2024Stochastic bilevel optimization (SBO) is becoming increasingly essential in machine learning due to its versatility in handling nested structures. To address large-scale SBO, decentralized approaches have emerged as effective paradigms in which nodes communicate with immediate neighbors without a central server, thereby improving communication efficiency and enhancing algorithmic robustness. However, current decentralized SBO algorithms face challenges, including expensive inner-loop updates and unclear understanding of the influence of network topology, data heterogeneity, and the nested bilevel algorithmic structures. In this paper, we introduce a single-loop decentralized SBO (D-SOBA) algorithm and establish its transient iteration complexity, which, for the first time, clarifies the joint influence of network topology and data heterogeneity on decentralized bilevel algorithms. D-SOBA achieves the state-of-the-art asymptotic rate, asymptotic gradient/Hessian complexity, and transient iteration complexity under more relaxed assumptions compared to existing methods. Numerical experiments validate our theoretical findings.