 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNMR: Runtime Stability Control for Low-Precision Large Language Model Training
May 30, 2026Training stability is a key bottleneck in low-precision language model training: efficient low-cost paths can still produce short-lived numerical risks at a small set of operators. We formulate this as runtime stability control and present Gradient Norm-to-Mean Ratio (GNMR), a lightweight controller that compares each recoverable unit's current gradient norm with its historical mean. Together with $Δ$-GNMR for abrupt short-window increases, GNMR maps local risk signals to bounded recovery actions under a hard $\mathrm{maxO}$ budget and a short lock interval, without changing the numerical format, kernel, or backend recipe. Across activation-quantization stress, DeepSeek-style recipe-level training, and LLaMA-2 13B fine-tuning, GNMR preserves high-fidelity quality with sparse, budgeted recovery. These results support GNMR as a backend-agnostic controller to improve low-precision training stability while preserving low-cost execution.
BROS: Bias-Corrected Randomized Subspaces for Memory-Efficient Single-Loop Bilevel Optimization
May 11, 2026Stochastic bilevel optimization (SBO) has become a standard framework for hyperparameter learning, data reweighting, representation learning, and data-mixture optimization in deep learning. Existing exact single-loop SBO methods and memory-efficient surrogate SBO methods either create severe memory pressure for large lower-level neural networks or lack competitive convergence guarantees under standard assumptions. In this paper, we propose BROS, a memory-efficient single-loop SBO method with the same convergence rate order as exact single-loop SBO methods. BROS performs lower and auxiliary updates in randomized subspaces with a Rademacher bi-probe correction that recovers an unbiased Hessian-action estimator. We prove that BROS preserves the $\mathcal O(\varepsilon^{-2})$ sample complexity of MA-SOBA for finding an $\varepsilon$-stationary point under only standard assumptions. Experiments on hyper-data cleaning, data-mixture learning, hyper-representation learning, and ViT sample reweighting show that BROS reduces peak memory by up to 44.9% while closely matching full-space baseline performance.
Synergistic Intra- and Cross-Layer Regularization Losses for MoE Expert Specialization
Feb 15, 2026Sparse Mixture-of-Experts (MoE) models scale Transformers efficiently but suffer from expert overlap -- redundant representations across experts and routing ambiguity, resulting in severely underutilized model capacity. While architectural solutions like DeepSeekMoE promote specialization, they require substantial structural modifications and rely solely on intra-layer signals. In this paper, we propose two plug-and-play regularization losses that enhance MoE specialization and routing efficiency without modifying router or model architectures. First, an intra-layer specialization loss penalizes cosine similarity between experts' SwiGLU activations on identical tokens, encouraging experts to specialize in complementary knowledge. Second, a cross-layer coupling loss maximizes joint Top-$k$ routing probabilities across adjacent layers, establishing coherent expert pathways through network depth while reinforcing intra-layer expert specialization. Both losses are orthogonal to the standard load-balancing loss and compatible with both the shared-expert architecture in DeepSeekMoE and vanilla top-$k$ MoE architectures. We implement both losses as a drop-in Megatron-LM module. Extensive experiments across pre-training, fine-tuning, and zero-shot benchmarks demonstrate consistent task gains, higher expert specialization, and lower-entropy routing; together, these improvements translate into faster inference via more stable expert pathways.
SPARKLE: A Unified Single-Loop Primal-Dual Framework for Decentralized Bilevel Optimization
Nov 21, 2024



This paper studies decentralized bilevel optimization, in which multiple agents collaborate to solve problems involving nested optimization structures with neighborhood communications. Most existing literature primarily utilizes gradient tracking to mitigate the influence of data heterogeneity, without exploring other well-known heterogeneity-correction techniques such as EXTRA or Exact Diffusion. Additionally, these studies often employ identical decentralized strategies for both upper- and lower-level problems, neglecting to leverage distinct mechanisms across different levels. To address these limitations, this paper proposes SPARKLE, a unified Single-loop Primal-dual AlgoRithm frameworK for decentraLized bilEvel optimization. SPARKLE offers the flexibility to incorporate various heterogeneitycorrection strategies into the algorithm. Moreover, SPARKLE allows for different strategies to solve upper- and lower-level problems. We present a unified convergence analysis for SPARKLE, applicable to all its variants, with state-of-the-art convergence rates compared to existing decentralized bilevel algorithms. Our results further reveal that EXTRA and Exact Diffusion are more suitable for decentralized bilevel optimization, and using mixed strategies in bilevel algorithms brings more benefits than relying solely on gradient tracking.
Decentralized Bilevel Optimization over Graphs: Loopless Algorithmic Update and Transient Iteration Complexity
Feb 05, 2024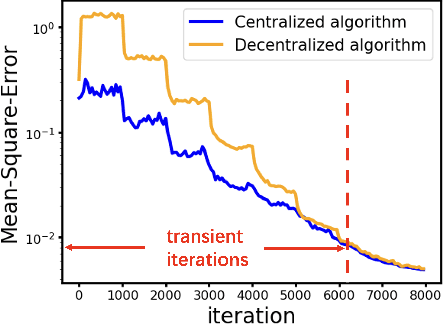
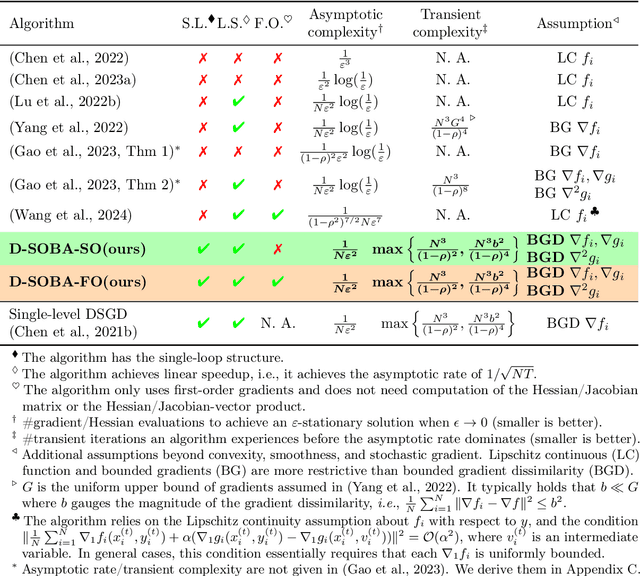
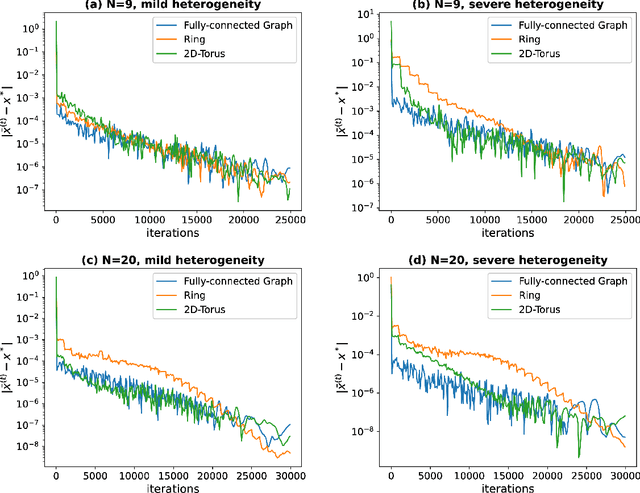

Stochastic bilevel optimization (SBO) is becoming increasingly essential in machine learning due to its versatility in handling nested structures. To address large-scale SBO, decentralized approaches have emerged as effective paradigms in which nodes communicate with immediate neighbors without a central server, thereby improving communication efficiency and enhancing algorithmic robustness. However, current decentralized SBO algorithms face challenges, including expensive inner-loop updates and unclear understanding of the influence of network topology, data heterogeneity, and the nested bilevel algorithmic structures. In this paper, we introduce a single-loop decentralized SBO (D-SOBA) algorithm and establish its transient iteration complexity, which, for the first time, clarifies the joint influence of network topology and data heterogeneity on decentralized bilevel algorithms. D-SOBA achieves the state-of-the-art asymptotic rate, asymptotic gradient/Hessian complexity, and transient iteration complexity under more relaxed assumptions compared to existing methods. Numerical experiments validate our theoretical findings.