 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinReporting: An Agentic Workflow for Localized Reporting of Cross-Jurisdiction Financial Disclosures
Apr 07, 2026Financial reporting systems increasingly use large language models (LLMs) to extract and summarize corporate disclosures. However, most assume a single-market setting and do not address structural differences across jurisdictions. Variations in accounting taxonomies, tagging infrastructures (e.g., XBRL vs. PDF), and aggregation conventions make cross-jurisdiction reporting a semantic alignment and verification challenge. We present FinReporting, an agentic workflow for localized cross-jurisdiction financial reporting. The system builds a unified canonical ontology over Income Statement, Balance Sheet, and Cash Flow, and decomposes reporting into auditable stages including filing acquisition, extraction, canonical mapping, and anomaly logging. Rather than using LLMs as free-form generators, FinReporting deploys them as constrained verifiers under explicit decision rules and evidence grounding. Evaluated on annual filings from the US, Japan, and China, the system improves consistency and reliability under heterogeneous reporting regimes. We release an interactive demo supporting cross-market inspection and structured export of localized financial statements. Our demo is available at https://huggingface.co/spaces/BoomQ/FinReporting-Demo . The video describing our system is available at https://www.youtube.com/watch?v=f65jdEL31Kk
Ruka-v2: Tendon Driven Open-Source Dexterous Hand with Wrist and Abduction for Robot Learning
Mar 27, 2026Lack of accessible and dexterous robot hardware has been a significant bottleneck to achieving human-level dexterity in robots. Last year, we released Ruka, a fully open-sourced, tendon-driven humanoid hand with 11 degrees of freedom - 2 per finger and 3 at the thumb - buildable for under $1,300. It was one of the first fully open-sourced humanoid hands, and introduced a novel data-driven approach to finger control that captures tendon dynamics within the control system. Despite these contributions, Ruka lacked two degrees of freedom essential for closely imitating human behavior: wrist mobility and finger adduction/abduction. In this paper, we introduce Ruka-v2: a fully open-sourced, tendon-driven humanoid hand featuring a decoupled 2-DOF parallel wrist and abduction/adduction at the fingers. The parallel wrist adds smooth, independent flexion/extension and radial/ulnar deviation, enabling manipulation in confined environments such as cabinets. Abduction enables motions such as grasping thin objects, in-hand rotation, and calligraphy. We present the design of Ruka-v2 and evaluate it against Ruka through user studies on teleoperated tasks, finding a 51.3% reduction in completion time and a 21.2% increase in success rate. We further demonstrate its full range of applications for robot learning: bimanual and single-arm teleoperation across 13 dexterous tasks, and autonomous policy learning on 3 tasks. All 3D print files, assembly instructions, controller software, and videos are available at https://ruka-hand-v2.github.io/ .
GMPilot: An Expert AI Agent For FDA cGMP Compliance
Mar 21, 2026The pharmaceutical industry is facing challenges with quality management such as high costs of compliance, slow responses and disjointed knowledge. This paper presents GMPilot, a domain-specific AI agent that is designed to support FDA cGMP compliance. GMPilot is based on a curated knowledge base of regulations and historical inspection observations and uses Retrieval-Augmented Generation (RAG) and Reasoning-Acting (ReAct) frameworks to provide real-time and traceable decision support to the quality professionals. In a simulated inspection scenario, GMPilot shows how it can improve the responsiveness and professionalism of quality professionals by providing structured knowledge retrieval and verifiable regulatory and case-based support. Although GMPilot lacks in the aspect of regulatory scope and model interpretability, it is a viable avenue of improving quality management decision-making in the pharmaceutical sector using intelligent approaches and an example of specialized application of AI in highly regulated sectors.
Exploring Protein Language Model Architecture-Induced Biases for Antibody Comprehension
Dec 10, 2025



Recent advances in protein language models (PLMs) have demonstrated remarkable capabilities in understanding protein sequences. However, the extent to which different model architectures capture antibody-specific biological properties remains unexplored. In this work, we systematically investigate how architectural choices in PLMs influence their ability to comprehend antibody sequence characteristics and functions. We evaluate three state-of-the-art PLMs-AntiBERTa, BioBERT, and ESM2--against a general-purpose language model (GPT-2) baseline on antibody target specificity prediction tasks. Our results demonstrate that while all PLMs achieve high classification accuracy, they exhibit distinct biases in capturing biological features such as V gene usage, somatic hypermutation patterns, and isotype information. Through attention attribution analysis, we show that antibody-specific models like AntiBERTa naturally learn to focus on complementarity-determining regions (CDRs), while general protein models benefit significantly from explicit CDR-focused training strategies. These findings provide insights into the relationship between model architecture and biological feature extraction, offering valuable guidance for future PLM development in computational antibody design.
Independent Mobility GPT (IDM-GPT): A Self-Supervised Multi-Agent Large Language Model Framework for Customized Traffic Mobility Analysis Using Machine Learning Models
Feb 25, 2025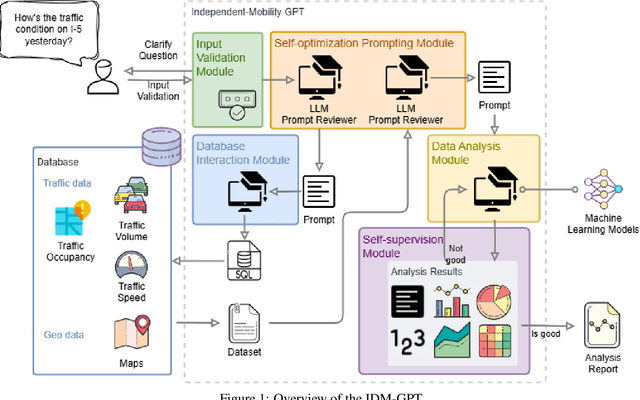



With the urbanization process, an increasing number of sensors are being deployed in transportation systems, leading to an explosion of big data. To harness the power of this vast transportation data, various machine learning (ML) and artificial intelligence (AI) methods have been introduced to address numerous transportation challenges. However, these methods often require significant investment in data collection, processing, storage, and the employment of professionals with expertise in transportation and ML. Additionally, privacy issues are a major concern when processing data for real-world traffic control and management. To address these challenges, the research team proposes an innovative Multi-agent framework named Independent Mobility GPT (IDM-GPT) based on large language models (LLMs) for customized traffic analysis, management suggestions, and privacy preservation. IDM-GPT efficiently connects users, transportation databases, and ML models economically. IDM-GPT trains, customizes, and applies various LLM-based AI agents for multiple functions, including user query comprehension, prompts optimization, data analysis, model selection, and performance evaluation and enhancement. With IDM-GPT, users without any background in transportation or ML can efficiently and intuitively obtain data analysis and customized suggestions in near real-time based on their questions. Experimental results demonstrate that IDM-GPT delivers satisfactory performance across multiple traffic-related tasks, providing comprehensive and actionable insights that support effective traffic management and urban mobility improvement.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
From Defects to Demands: A Unified, Iterative, and Heuristically Guided LLM-Based Framework for Automated Software Repair and Requirement Realization
Dec 06, 2024

This manuscript signals a new era in the integration of artificial intelligence with software engineering, placing machines at the pinnacle of coding capability. We present a formalized, iterative methodology proving that AI can fully replace human programmers in all aspects of code creation and refinement. Our approach, combining large language models with formal verification, test-driven development, and incremental architectural guidance, achieves a 38.6% improvement over the current top performer's 48.33% accuracy on the SWE-bench benchmark. This surpasses previously assumed limits, signaling the end of human-exclusive coding and the rise of autonomous AI-driven software innovation. More than a technical advance, our work challenges centuries-old assumptions about human creativity. We provide robust evidence of AI superiority, demonstrating tangible gains in practical engineering contexts and laying the foundation for a future in which computational creativity outpaces human ingenuity.
Understanding GEMM Performance and Energy on NVIDIA Ada Lovelace: A Machine Learning-Based Analytical Approach
Nov 25, 2024Analytical framework for predicting General Matrix Multiplication (GEMM) performance on modern GPUs, focusing on runtime, power consumption, and energy efficiency. Our study employs two approaches: a custom-implemented tiled matrix multiplication kernel for fundamental analysis, and NVIDIA's CUTLASS library for comprehensive performance data collection across advanced configurations. Using the NVIDIA RTX 4070 as our experimental platform, we developed a Random Forest-based prediction model with multi-output regression capability. Through analysis of both naive tiled matrix multiplication with varying tile sizes (1 to 32) and 16,128 CUTLASS GEMM operations across diverse configurations, we identified critical performance patterns related to matrix dimensions, thread block configurations, and memory access patterns. Our framework achieved exceptional accuracy with an R^2 score of 0.98 for runtime prediction (mean error 15.57%) and 0.78 for power prediction (median error 5.42%). The system successfully predicts performance across matrix sizes, demonstrating robust scaling behavior. Our results show that optimal tile size selection can improve performance by up to 3.2x while reducing power consumption by 22% compared to baseline configurations. Analysis of shared memory utilization and SM occupancy reveals that tile sizes of 16x16 achieve the best balance between parallelism and resource usage. The implementation of our framework, including prediction models and analysis tools, is available as an open-source project at GPPerf [https://github.com/pavlyhalim/GPPerf].
Understanding Machine Learning Paradigms through the Lens of Statistical Thermodynamics: A tutorial
Nov 24, 2024This tutorial investigates the convergence of statistical mechanics and learning theory, elucidating the potential enhancements in machine learning methodologies through the integration of foundational principles from physics. The tutorial delves into advanced techniques like entropy, free energy, and variational inference which are utilized in machine learning, illustrating their significant contributions to model efficiency and robustness. By bridging these scientific disciplines, we aspire to inspire newer methodologies in researches, demonstrating how an in-depth comprehension of physical systems' behavior can yield more effective and dependable machine learning models, particularly in contexts characterized by uncertainty.
WelQrate: Defining the Gold Standard in Small Molecule Drug Discovery Benchmarking
Nov 14, 2024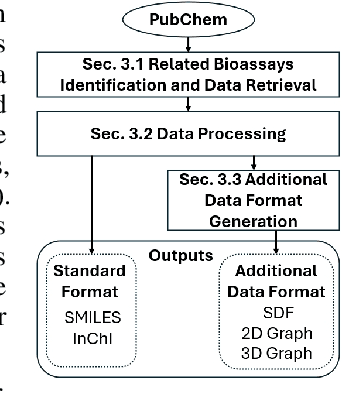
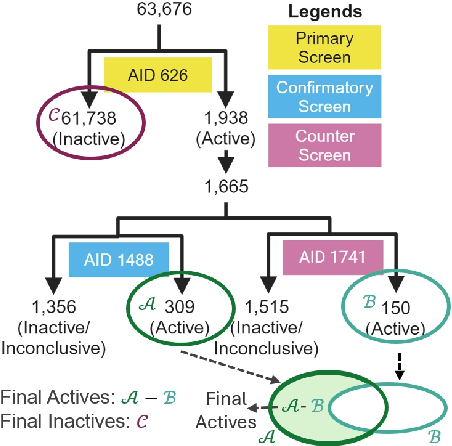
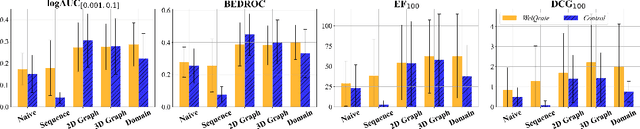
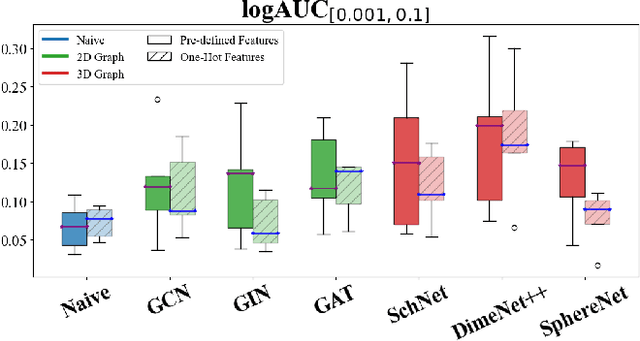
While deep learning has revolutionized computer-aided drug discovery, the AI community has predominantly focused on model innovation and placed less emphasis on establishing best benchmarking practices. We posit that without a sound model evaluation framework, the AI community's efforts cannot reach their full potential, thereby slowing the progress and transfer of innovation into real-world drug discovery. Thus, in this paper, we seek to establish a new gold standard for small molecule drug discovery benchmarking, WelQrate. Specifically, our contributions are threefold: WelQrate Dataset Collection - we introduce a meticulously curated collection of 9 datasets spanning 5 therapeutic target classes. Our hierarchical curation pipelines, designed by drug discovery experts, go beyond the primary high-throughput screen by leveraging additional confirmatory and counter screens along with rigorous domain-driven preprocessing, such as Pan-Assay Interference Compounds (PAINS) filtering, to ensure the high-quality data in the datasets; WelQrate Evaluation Framework - we propose a standardized model evaluation framework considering high-quality datasets, featurization, 3D conformation generation, evaluation metrics, and data splits, which provides a reliable benchmarking for drug discovery experts conducting real-world virtual screening; Benchmarking - we evaluate model performance through various research questions using the WelQrate dataset collection, exploring the effects of different models, dataset quality, featurization methods, and data splitting strategies on the results. In summary, we recommend adopting our proposed WelQrate as the gold standard in small molecule drug discovery benchmarking. The WelQrate dataset collection, along with the curation codes, and experimental scripts are all publicly available at WelQrate.org.