 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancements in Road Lane Mapping: Comparative Fine-Tuning Analysis of Deep Learning-based Semantic Segmentation Methods Using Aerial Imagery
Oct 08, 2024

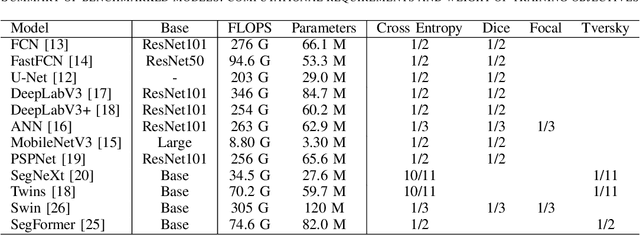
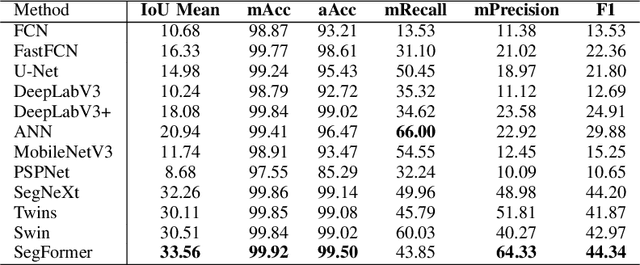
This research addresses the need for high-definition (HD) maps for autonomous vehicles (AVs), focusing on road lane information derived from aerial imagery. While Earth observation data offers valuable resources for map creation, specialized models for road lane extraction are still underdeveloped in remote sensing. In this study, we perform an extensive comparison of twelve foundational deep learning-based semantic segmentation models for road lane marking extraction from high-definition remote sensing images, assessing their performance under transfer learning with partially labeled datasets. These models were fine-tuned on the partially labeled Waterloo Urban Scene dataset, and pre-trained on the SkyScapes dataset, simulating a likely scenario of real-life model deployment under partial labeling. We observed and assessed the fine-tuning performance and overall performance. Models showed significant performance improvements after fine-tuning, with mean IoU scores ranging from 33.56% to 76.11%, and recall ranging from 66.0% to 98.96%. Transformer-based models outperformed convolutional neural networks, emphasizing the importance of model pre-training and fine-tuning in enhancing HD map development for AV navigation.
Deep Learning for LiDAR Point Clouds in Autonomous Driving: A Review
May 20, 2020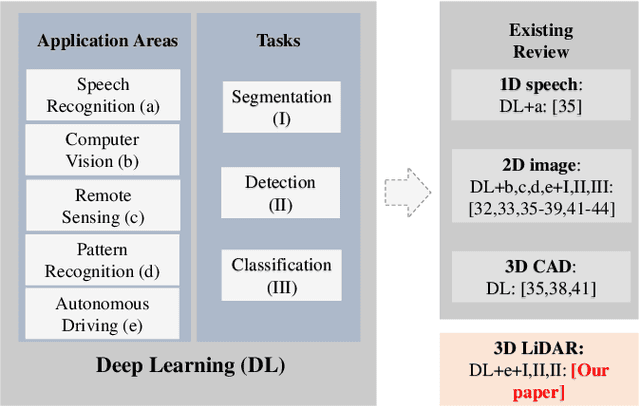
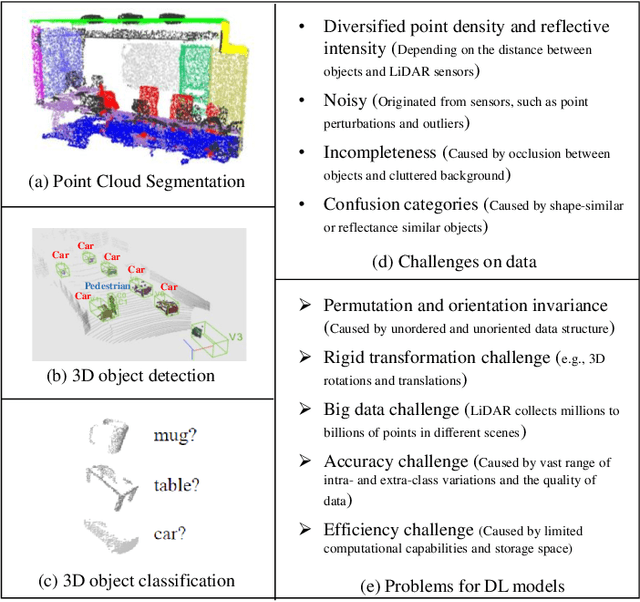
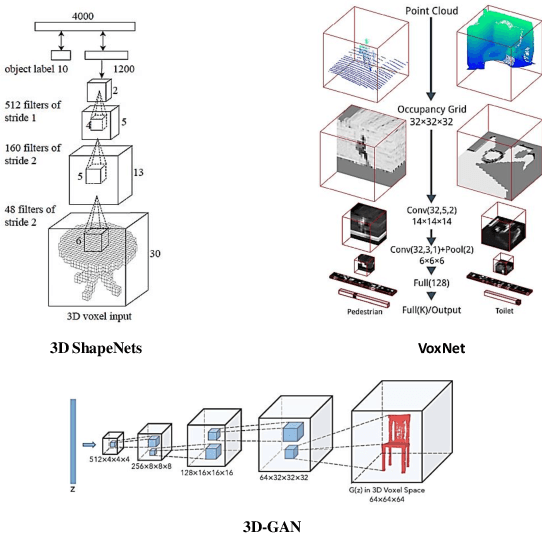
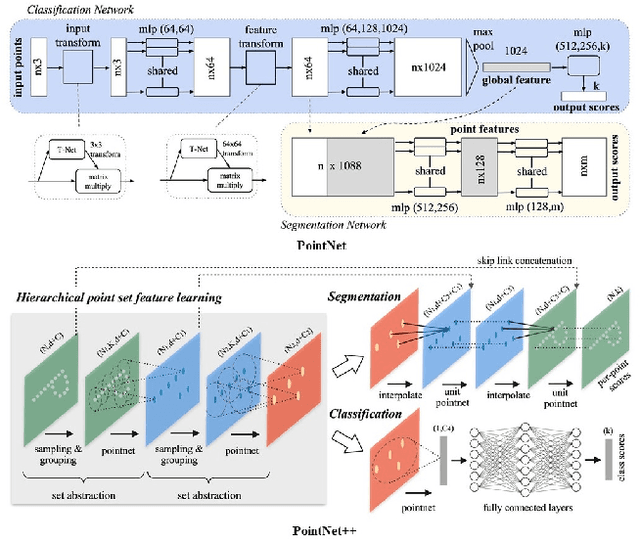
Recently, the advancement of deep learning in discriminative feature learning from 3D LiDAR data has led to rapid development in the field of autonomous driving. However, automated processing uneven, unstructured, noisy, and massive 3D point clouds is a challenging and tedious task. In this paper, we provide a systematic review of existing compelling deep learning architectures applied in LiDAR point clouds, detailing for specific tasks in autonomous driving such as segmentation, detection, and classification. Although several published research papers focus on specific topics in computer vision for autonomous vehicles, to date, no general survey on deep learning applied in LiDAR point clouds for autonomous vehicles exists. Thus, the goal of this paper is to narrow the gap in this topic. More than 140 key contributions in the recent five years are summarized in this survey, including the milestone 3D deep architectures, the remarkable deep learning applications in 3D semantic segmentation, object detection, and classification; specific datasets, evaluation metrics, and the state of the art performance. Finally, we conclude the remaining challenges and future researches.