 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Calibration for Membership Inference Attack on Large Language Models
May 06, 2025Membership Inference Attacks (MIAs) have recently been employed to determine whether a specific text was part of the pre-training data of Large Language Models (LLMs). However, existing methods often misinfer non-members as members, leading to a high false positive rate, or depend on additional reference models for probability calibration, which limits their practicality. To overcome these challenges, we introduce a novel framework called Automatic Calibration Membership Inference Attack (ACMIA), which utilizes a tunable temperature to calibrate output probabilities effectively. This approach is inspired by our theoretical insights into maximum likelihood estimation during the pre-training of LLMs. We introduce ACMIA in three configurations designed to accommodate different levels of model access and increase the probability gap between members and non-members, improving the reliability and robustness of membership inference. Extensive experiments on various open-source LLMs demonstrate that our proposed attack is highly effective, robust, and generalizable, surpassing state-of-the-art baselines across three widely used benchmarks. Our code is available at: \href{https://github.com/Salehzz/ACMIA}{\textcolor{blue}{Github}}.
MulModSeg: Enhancing Unpaired Multi-Modal Medical Image Segmentation with Modality-Conditioned Text Embedding and Alternating Training
Nov 23, 2024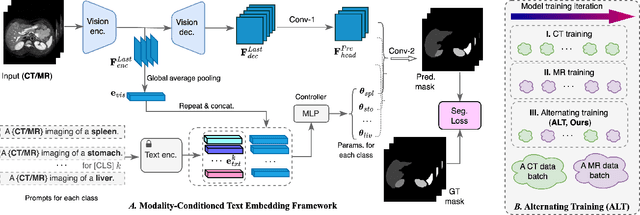
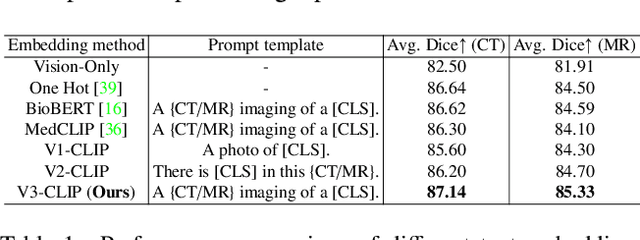
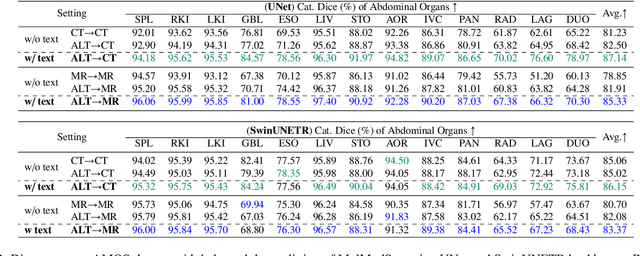
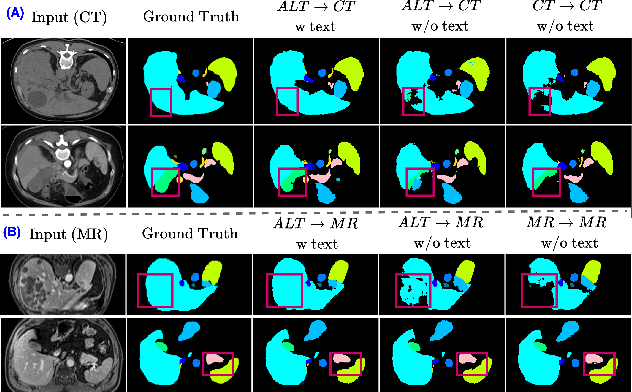
In the diverse field of medical imaging, automatic segmentation has numerous applications and must handle a wide variety of input domains, such as different types of Computed Tomography (CT) scans and Magnetic Resonance (MR) images. This heterogeneity challenges automatic segmentation algorithms to maintain consistent performance across different modalities due to the requirement for spatially aligned and paired images. Typically, segmentation models are trained using a single modality, which limits their ability to generalize to other types of input data without employing transfer learning techniques. Additionally, leveraging complementary information from different modalities to enhance segmentation precision often necessitates substantial modifications to popular encoder-decoder designs, such as introducing multiple branched encoding or decoding paths for each modality. In this work, we propose a simple Multi-Modal Segmentation (MulModSeg) strategy to enhance medical image segmentation across multiple modalities, specifically CT and MR. It incorporates two key designs: a modality-conditioned text embedding framework via a frozen text encoder that adds modality awareness to existing segmentation frameworks without significant structural modifications or computational overhead, and an alternating training procedure that facilitates the integration of essential features from unpaired CT and MR inputs. Through extensive experiments with both Fully Convolutional Network and Transformer-based backbones, MulModSeg consistently outperforms previous methods in segmenting abdominal multi-organ and cardiac substructures for both CT and MR modalities. The code is available in this {\href{https://github.com/ChengyinLee/MulModSeg_2024}{link}}.
Byzantine-Robust Decentralized Federated Learning
Jun 18, 2024



Federated learning (FL) enables multiple clients to collaboratively train machine learning models without revealing their private training data. In conventional FL, the system follows the server-assisted architecture (server-assisted FL), where the training process is coordinated by a central server. However, the server-assisted FL framework suffers from poor scalability due to a communication bottleneck at the server, and trust dependency issues. To address challenges, decentralized federated learning (DFL) architecture has been proposed to allow clients to train models collaboratively in a serverless and peer-to-peer manner. However, due to its fully decentralized nature, DFL is highly vulnerable to poisoning attacks, where malicious clients could manipulate the system by sending carefully-crafted local models to their neighboring clients. To date, only a limited number of Byzantine-robust DFL methods have been proposed, most of which are either communication-inefficient or remain vulnerable to advanced poisoning attacks. In this paper, we propose a new algorithm called BALANCE (Byzantine-robust averaging through local similarity in decentralization) to defend against poisoning attacks in DFL. In BALANCE, each client leverages its own local model as a similarity reference to determine if the received model is malicious or benign. We establish the theoretical convergence guarantee for BALANCE under poisoning attacks in both strongly convex and non-convex settings. Furthermore, the convergence rate of BALANCE under poisoning attacks matches those of the state-of-the-art counterparts in Byzantine-free settings. Extensive experiments also demonstrate that BALANCE outperforms existing DFL methods and effectively defends against poisoning attacks.
Understanding Server-Assisted Federated Learning in the Presence of Incomplete Client Participation
May 04, 2024



Existing works in federated learning (FL) often assume an ideal system with either full client or uniformly distributed client participation. However, in practice, it has been observed that some clients may never participate in FL training (aka incomplete client participation) due to a myriad of system heterogeneity factors. A popular approach to mitigate impacts of incomplete client participation is the server-assisted federated learning (SA-FL) framework, where the server is equipped with an auxiliary dataset. However, despite SA-FL has been empirically shown to be effective in addressing the incomplete client participation problem, there remains a lack of theoretical understanding for SA-FL. Meanwhile, the ramifications of incomplete client participation in conventional FL are also poorly understood. These theoretical gaps motivate us to rigorously investigate SA-FL. Toward this end, we first show that conventional FL is {\em not} PAC-learnable under incomplete client participation in the worst case. Then, we show that the PAC-learnability of FL with incomplete client participation can indeed be revived by SA-FL, which theoretically justifies the use of SA-FL for the first time. Lastly, to provide practical guidance for SA-FL training under {\em incomplete client participation}, we propose the $\mathsf{SAFARI}$ (server-assisted federated averaging) algorithm that enjoys the same linear convergence speedup guarantees as classic FL with ideal client participation assumptions, offering the first SA-FL algorithm with convergence guarantee. Extensive experiments on different datasets show $\mathsf{SAFARI}$ significantly improves the performance under incomplete client participation.
FedDRO: Federated Compositional Optimization for Distributionally Robust Learning
Nov 21, 2023

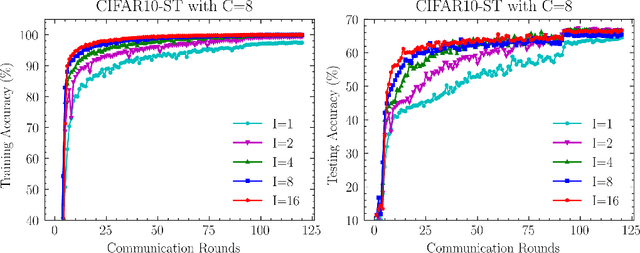
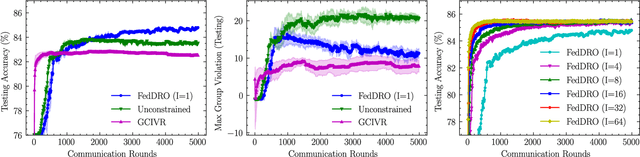
Recently, compositional optimization (CO) has gained popularity because of its applications in distributionally robust optimization (DRO) and many other machine learning problems. Large-scale and distributed availability of data demands the development of efficient federated learning (FL) algorithms for solving CO problems. Developing FL algorithms for CO is particularly challenging because of the compositional nature of the objective. Moreover, current state-of-the-art methods to solve such problems rely on large batch gradients (depending on the solution accuracy) not feasible for most practical settings. To address these challenges, in this work, we propose efficient FedAvg-type algorithms for solving non-convex CO in the FL setting. We first establish that vanilla FedAvg is not suitable to solve distributed CO problems because of the data heterogeneity in the compositional objective at each client which leads to the amplification of bias in the local compositional gradient estimates. To this end, we propose a novel FL framework FedDRO that utilizes the DRO problem structure to design a communication strategy that allows FedAvg to control the bias in the estimation of the compositional gradient. A key novelty of our work is to develop solution accuracy-independent algorithms that do not require large batch gradients (and function evaluations) for solving federated CO problems. We establish $\mathcal{O}(\epsilon^{-2})$ sample and $\mathcal{O}(\epsilon^{-3/2})$ communication complexity in the FL setting while achieving linear speedup with the number of clients. We corroborate our theoretical findings with empirical studies on large-scale DRO problems.
GeoSAM: Fine-tuning SAM with Sparse and Dense Visual Prompting for Automated Segmentation of Mobility Infrastructure
Nov 19, 2023



The Segment Anything Model (SAM) has shown impressive performance when applied to natural image segmentation. However, it struggles with geographical images like aerial and satellite imagery, especially when segmenting mobility infrastructure including roads, sidewalks, and crosswalks. This inferior performance stems from the narrow features of these objects, their textures blending into the surroundings, and interference from objects like trees, buildings, vehicles, and pedestrians - all of which can disorient the model to produce inaccurate segmentation maps. To address these challenges, we propose Geographical SAM (GeoSAM), a novel SAM-based framework that implements a fine-tuning strategy using the dense visual prompt from zero-shot learning, and the sparse visual prompt from a pre-trained CNN segmentation model. The proposed GeoSAM outperforms existing approaches for geographical image segmentation, specifically by 20%, 14.29%, and 17.65% for road infrastructure, pedestrian infrastructure, and on average, respectively, representing a momentous leap in leveraging foundation models to segment mobility infrastructure including both road and pedestrian infrastructure in geographical images.
Interpretability-Aware Vision Transformer
Sep 14, 2023


Vision Transformers (ViTs) have become prominent models for solving various vision tasks. However, the interpretability of ViTs has not kept pace with their promising performance. While there has been a surge of interest in developing {\it post hoc} solutions to explain ViTs' outputs, these methods do not generalize to different downstream tasks and various transformer architectures. Furthermore, if ViTs are not properly trained with the given data and do not prioritize the region of interest, the {\it post hoc} methods would be less effective. Instead of developing another {\it post hoc} approach, we introduce a novel training procedure that inherently enhances model interpretability. Our interpretability-aware ViT (IA-ViT) draws inspiration from a fresh insight: both the class patch and image patches consistently generate predicted distributions and attention maps. IA-ViT is composed of a feature extractor, a predictor, and an interpreter, which are trained jointly with an interpretability-aware training objective. Consequently, the interpreter simulates the behavior of the predictor and provides a faithful explanation through its single-head self-attention mechanism. Our comprehensive experimental results demonstrate the effectiveness of IA-ViT in several image classification tasks, with both qualitative and quantitative evaluations of model performance and interpretability. Source code is available from: https://github.com/qiangyao1988/IA-ViT.
Auto-Prompting SAM for Mobile Friendly 3D Medical Image Segmentation
Aug 28, 2023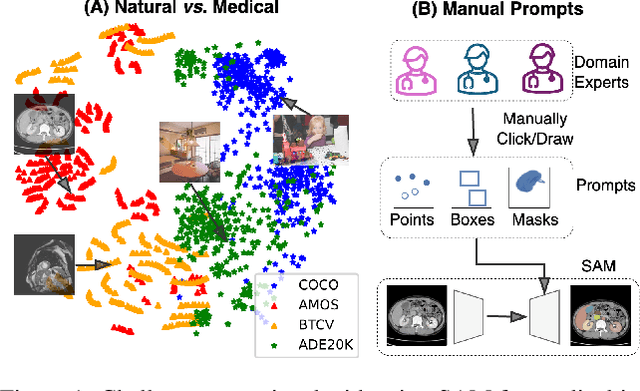
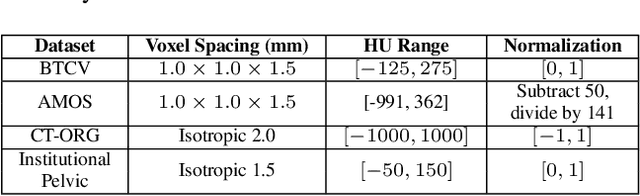
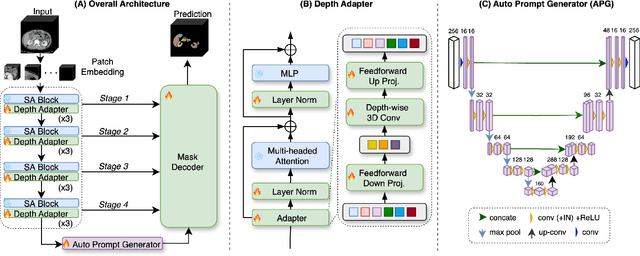
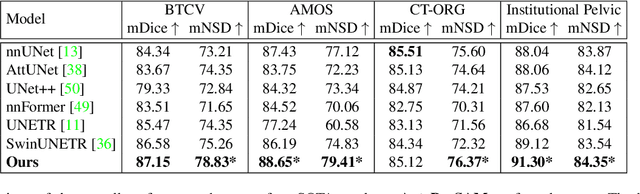
The Segment Anything Model (SAM) has rapidly been adopted for segmenting a wide range of natural images. However, recent studies have indicated that SAM exhibits subpar performance on 3D medical image segmentation tasks. In addition to the domain gaps between natural and medical images, disparities in the spatial arrangement between 2D and 3D images, the substantial computational burden imposed by powerful GPU servers, and the time-consuming manual prompt generation impede the extension of SAM to a broader spectrum of medical image segmentation applications. To address these challenges, in this work, we introduce a novel method, AutoSAM Adapter, designed specifically for 3D multi-organ CT-based segmentation. We employ parameter-efficient adaptation techniques in developing an automatic prompt learning paradigm to facilitate the transformation of the SAM model's capabilities to 3D medical image segmentation, eliminating the need for manually generated prompts. Furthermore, we effectively transfer the acquired knowledge of the AutoSAM Adapter to other lightweight models specifically tailored for 3D medical image analysis, achieving state-of-the-art (SOTA) performance on medical image segmentation tasks. Through extensive experimental evaluation, we demonstrate the AutoSAM Adapter as a critical foundation for effectively leveraging the emerging ability of foundation models in 2D natural image segmentation for 3D medical image segmentation.
An Introduction to Bi-level Optimization: Foundations and Applications in Signal Processing and Machine Learning
Aug 03, 2023



Recently, bi-level optimization (BLO) has taken center stage in some very exciting developments in the area of signal processing (SP) and machine learning (ML). Roughly speaking, BLO is a classical optimization problem that involves two levels of hierarchy (i.e., upper and lower levels), wherein obtaining the solution to the upper-level problem requires solving the lower-level one. BLO has become popular largely because it is powerful in modeling problems in SP and ML, among others, that involve optimizing nested objective functions. Prominent applications of BLO range from resource allocation for wireless systems to adversarial machine learning. In this work, we focus on a class of tractable BLO problems that often appear in SP and ML applications. We provide an overview of some basic concepts of this class of BLO problems, such as their optimality conditions, standard algorithms (including their optimization principles and practical implementations), as well as how they can be leveraged to obtain state-of-the-art results for a number of key SP and ML applications. Further, we discuss some recent advances in BLO theory, its implications for applications, and point out some limitations of the state-of-the-art that require significant future research efforts. Overall, we hope that this article can serve to accelerate the adoption of BLO as a generic tool to model, analyze, and innovate on a wide array of emerging SP and ML applications.
Fairness-aware Vision Transformer via Debiased Self-Attention
Jan 31, 2023

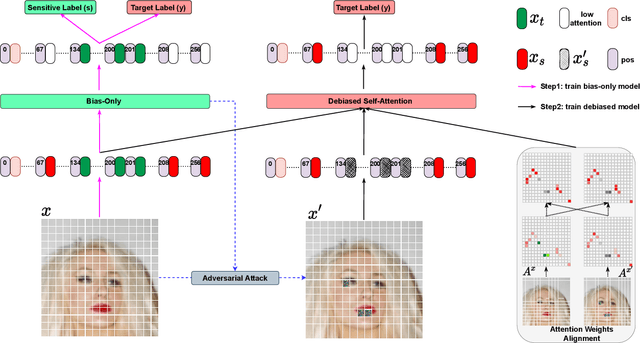
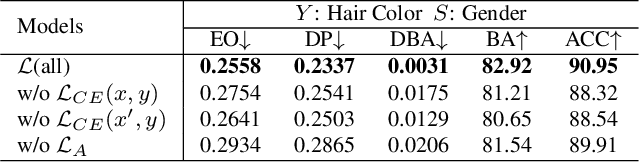
Vision Transformer (ViT) has recently gained significant interest in solving computer vision (CV) problems due to its capability of extracting informative features and modeling long-range dependencies through the self-attention mechanism. To fully realize the advantages of ViT in real-world applications, recent works have explored the trustworthiness of ViT, including its robustness and explainability. However, another desiderata, fairness has not yet been adequately addressed in the literature. We establish that the existing fairness-aware algorithms (primarily designed for CNNs) do not perform well on ViT. This necessitates the need for developing our novel framework via Debiased Self-Attention (DSA). DSA is a fairness-through-blindness approach that enforces ViT to eliminate spurious features correlated with the sensitive attributes for bias mitigation. Notably, adversarial examples are leveraged to locate and mask the spurious features in the input image patches. In addition, DSA utilizes an attention weights alignment regularizer in the training objective to encourage learning informative features for target prediction. Importantly, our DSA framework leads to improved fairness guarantees over prior works on multiple prediction tasks without compromising target prediction performance