 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability-Aware Vision Transformer
Paper and Code



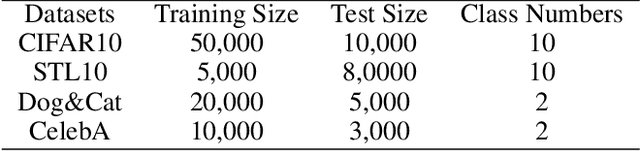
Vision Transformers (ViTs) have become prominent models for solving various vision tasks. However, the interpretability of ViTs has not kept pace with their promising performance. While there has been a surge of interest in developing {\it post hoc} solutions to explain ViTs' outputs, these methods do not generalize to different downstream tasks and various transformer architectures. Furthermore, if ViTs are not properly trained with the given data and do not prioritize the region of interest, the {\it post hoc} methods would be less effective. Instead of developing another {\it post hoc} approach, we introduce a novel training procedure that inherently enhances model interpretability. Our interpretability-aware ViT (IA-ViT) draws inspiration from a fresh insight: both the class patch and image patches consistently generate predicted distributions and attention maps. IA-ViT is composed of a feature extractor, a predictor, and an interpreter, which are trained jointly with an interpretability-aware training objective. Consequently, the interpreter simulates the behavior of the predictor and provides a faithful explanation through its single-head self-attention mechanism. Our comprehensive experimental results demonstrate the effectiveness of IA-ViT in several image classification tasks, with both qualitative and quantitative evaluations of model performance and interpretability. Source code is available from: https://github.com/qiangyao1988/IA-ViT.