 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalkGPT: Grounded Vision-Language Conversation with Depth-Aware Segmentation for Pedestrian Navigation
Mar 11, 2026Ensuring accessible pedestrian navigation requires reasoning about both semantic and spatial aspects of complex urban scenes, a challenge that existing Large Vision-Language Models (LVLMs) struggle to meet. Although these models can describe visual content, their lack of explicit grounding leads to object hallucinations and unreliable depth reasoning, limiting their usefulness for accessibility guidance. We introduce WalkGPT, a pixel-grounded LVLM for the new task of Grounded Navigation Guide, unifying language reasoning and segmentation within a single architecture for depth-aware accessibility guidance. Given a pedestrian-view image and a navigation query, WalkGPT generates a conversational response with segmentation masks that delineate accessible and harmful features, along with relative depth estimation. The model incorporates a Multi-Scale Query Projector (MSQP) that shapes the final image tokens by aggregating them along text tokens across spatial hierarchies, and a Calibrated Text Projector (CTP), guided by a proposed Region Alignment Loss, that maps language embeddings into segmentation-aware representations. These components enable fine-grained grounding and depth inference without user-provided cues or anchor points, allowing the model to generate complete and realistic navigation guidance. We also introduce PAVE, a large-scale benchmark of 41k pedestrian-view images paired with accessibility-aware questions and depth-grounded answers. Experiments show that WalkGPT achieves strong grounded reasoning and segmentation performance. The source code and dataset are available on the \href{https://sites.google.com/view/walkgpt-26/home}{project website}.
Rethinking Energy Management for Autonomous Ground Robots on a Budget
Feb 03, 2025



Autonomous Ground Robots (AGRs) face significant challenges due to limited energy reserve, which restricts their overall performance and availability. Prior research has focused separately on energy-efficient approaches and fleet management strategies for task allocation to extend operational time. A fleet-level scheduler, however, assumes a specific energy consumption during task allocation, requiring the AGR to fully utilize the energy for maximum performance, which contrasts with energy-efficient practices. This paper addresses this gap by investigating the combined impact of computing frequency and locomotion speed on energy consumption and performance. We analyze these variables through experiments on our prototype AGR, laying the foundation for an integrated approach that optimizes cyber-physical resources within the constraints of a specified energy budget. To tackle this challenge, we introduce PECC (Predictable Energy Consumption Controller), a framework designed to optimize computing frequency and locomotion speed to maximize performance while ensuring the system operates within the specified energy budget. We conducted extensive experiments with PECC using a real AGR and in simulations, comparing it to an energy-efficient baseline. Our results show that the AGR travels up to 17\% faster than the baseline in real-world tests and up to 31\% faster in simulations, while consuming 95\% and 91\% of the given energy budget, respectively. These results prove that PECC can effectively enhance AGR performance in scenarios where prioritizing the energy budget outweighs the need for energy efficiency.
GeoSAM: Fine-tuning SAM with Sparse and Dense Visual Prompting for Automated Segmentation of Mobility Infrastructure
Nov 19, 2023



The Segment Anything Model (SAM) has shown impressive performance when applied to natural image segmentation. However, it struggles with geographical images like aerial and satellite imagery, especially when segmenting mobility infrastructure including roads, sidewalks, and crosswalks. This inferior performance stems from the narrow features of these objects, their textures blending into the surroundings, and interference from objects like trees, buildings, vehicles, and pedestrians - all of which can disorient the model to produce inaccurate segmentation maps. To address these challenges, we propose Geographical SAM (GeoSAM), a novel SAM-based framework that implements a fine-tuning strategy using the dense visual prompt from zero-shot learning, and the sparse visual prompt from a pre-trained CNN segmentation model. The proposed GeoSAM outperforms existing approaches for geographical image segmentation, specifically by 20%, 14.29%, and 17.65% for road infrastructure, pedestrian infrastructure, and on average, respectively, representing a momentous leap in leveraging foundation models to segment mobility infrastructure including both road and pedestrian infrastructure in geographical images.
Adversarially Robust and Explainable Model Compression with On-Device Personalization for Text Classification
Jan 20, 2021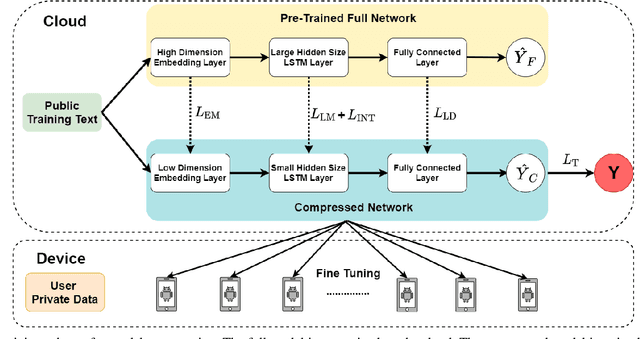
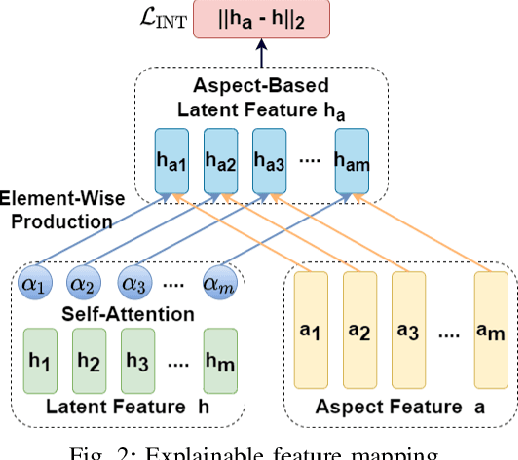
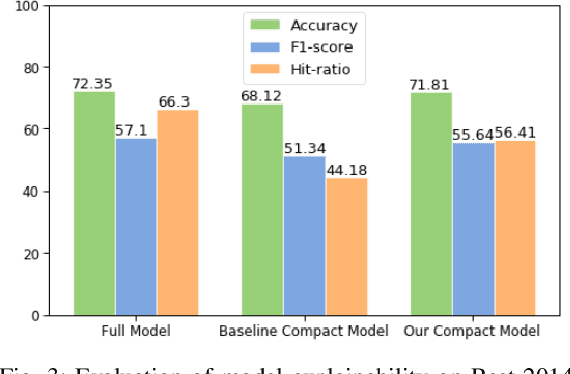
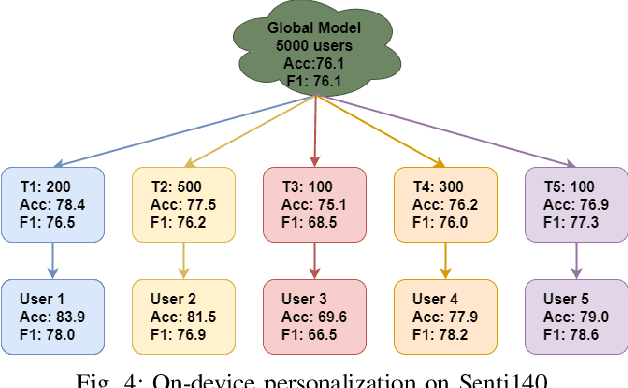
On-device Deep Neural Networks (DNNs) have recently gained more attention due to the increasing computing power of the mobile devices and the number of applications in Computer Vision (CV), Natural Language Processing (NLP), and Internet of Things (IoTs). Unfortunately, the existing efficient convolutional neural network (CNN) architectures designed for CV tasks are not directly applicable to NLP tasks and the tiny Recurrent Neural Network (RNN) architectures have been designed primarily for IoT applications. In NLP applications, although model compression has seen initial success in on-device text classification, there are at least three major challenges yet to be addressed: adversarial robustness, explainability, and personalization. Here we attempt to tackle these challenges by designing a new training scheme for model compression and adversarial robustness, including the optimization of an explainable feature mapping objective, a knowledge distillation objective, and an adversarially robustness objective. The resulting compressed model is personalized using on-device private training data via fine-tuning. We perform extensive experiments to compare our approach with both compact RNN (e.g., FastGRNN) and compressed RNN (e.g., PRADO) architectures in both natural and adversarial NLP test settings.