 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Server-Assisted Federated Learning in the Presence of Incomplete Client Participation
May 04, 2024



Existing works in federated learning (FL) often assume an ideal system with either full client or uniformly distributed client participation. However, in practice, it has been observed that some clients may never participate in FL training (aka incomplete client participation) due to a myriad of system heterogeneity factors. A popular approach to mitigate impacts of incomplete client participation is the server-assisted federated learning (SA-FL) framework, where the server is equipped with an auxiliary dataset. However, despite SA-FL has been empirically shown to be effective in addressing the incomplete client participation problem, there remains a lack of theoretical understanding for SA-FL. Meanwhile, the ramifications of incomplete client participation in conventional FL are also poorly understood. These theoretical gaps motivate us to rigorously investigate SA-FL. Toward this end, we first show that conventional FL is {\em not} PAC-learnable under incomplete client participation in the worst case. Then, we show that the PAC-learnability of FL with incomplete client participation can indeed be revived by SA-FL, which theoretically justifies the use of SA-FL for the first time. Lastly, to provide practical guidance for SA-FL training under {\em incomplete client participation}, we propose the $\mathsf{SAFARI}$ (server-assisted federated averaging) algorithm that enjoys the same linear convergence speedup guarantees as classic FL with ideal client participation assumptions, offering the first SA-FL algorithm with convergence guarantee. Extensive experiments on different datasets show $\mathsf{SAFARI}$ significantly improves the performance under incomplete client participation.
DIAMOND: Taming Sample and Communication Complexities in Decentralized Bilevel Optimization
Dec 10, 2022



Decentralized bilevel optimization has received increasing attention recently due to its foundational role in many emerging multi-agent learning paradigms (e.g., multi-agent meta-learning and multi-agent reinforcement learning) over peer-to-peer edge networks. However, to work with the limited computation and communication capabilities of edge networks, a major challenge in developing decentralized bilevel optimization techniques is to lower sample and communication complexities. This motivates us to develop a new decentralized bilevel optimization called DIAMOND (decentralized single-timescale stochastic approximation with momentum and gradient-tracking). The contributions of this paper are as follows: i) our DIAMOND algorithm adopts a single-loop structure rather than following the natural double-loop structure of bilevel optimization, which offers low computation and implementation complexity; ii) compared to existing approaches, the DIAMOND algorithm does not require any full gradient evaluations, which further reduces both sample and computational complexities; iii) through a careful integration of momentum information and gradient tracking techniques, we show that the DIAMOND algorithm enjoys $\mathcal{O}(\epsilon^{-3/2})$ in sample and communication complexities for achieving an $\epsilon$-stationary solution, both of which are independent of the dataset sizes and significantly outperform existing works. Extensive experiments also verify our theoretical findings.
Taming Fat-Tailed Noise in Federated Learning
Oct 03, 2022

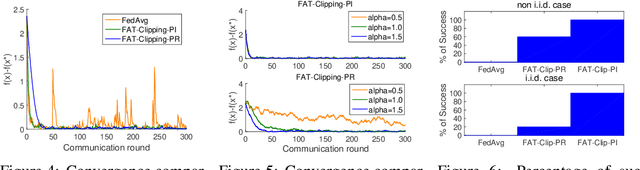
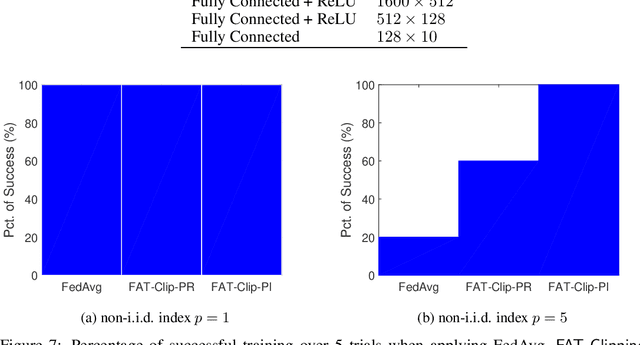
A key assumption in most existing works on FL algorithms' convergence analysis is that the noise in stochastic first-order information has a finite variance. Although this assumption covers all light-tailed (i.e., sub-exponential) and some heavy-tailed noise distributions (e.g., log-normal, Weibull, and some Pareto distributions), it fails for many fat-tailed noise distributions (i.e., ``heavier-tailed'' with potentially infinite variance) that have been empirically observed in the FL literature. To date, it remains unclear whether one can design convergent algorithms for FL systems that experience fat-tailed noise. This motivates us to fill this gap in this paper by proposing an algorithmic framework called FAT-Clipping (\ul{f}ederated \ul{a}veraging with \ul{t}wo-sided learning rates and \ul{clipping}), which contains two variants: FAT-Clipping per-round (FAT-Clipping-PR) and FAT-Clipping per-iteration (FAT-Clipping-PI). Specifically, for the largest $\alpha \in (1,2]$ such that the fat-tailed noise in FL still has a bounded $\alpha$-moment, we show that both variants achieve $\mathcal{O}((mT)^{\frac{2-\alpha}{\alpha}})$ and $\mathcal{O}((mT)^{\frac{1-\alpha}{3\alpha-2}})$ convergence rates in the strongly-convex and general non-convex settings, respectively, where $m$ and $T$ are the numbers of clients and communication rounds. Moreover, at the expense of more clipping operations compared to FAT-Clipping-PR, FAT-Clipping-PI further enjoys a linear speedup effect with respect to the number of local updates at each client and being lower-bound-matching (i.e., order-optimal). Collectively, our results advance the understanding of designing efficient algorithms for FL systems that exhibit fat-tailed first-order oracle information.
CHARLES: Channel-Quality-Adaptive Over-the-Air Federated Learning over Wireless Networks
May 19, 2022
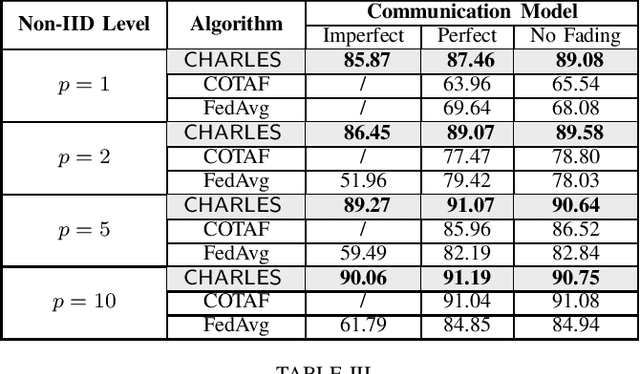
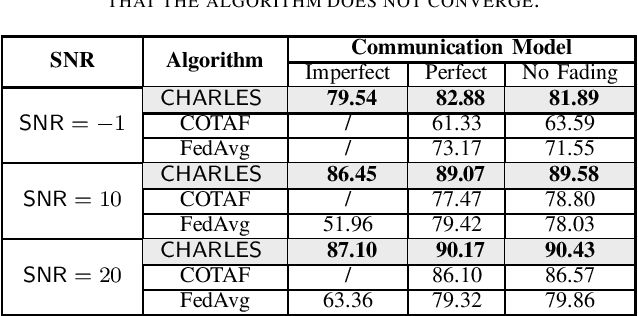
Over-the-air federated learning (OTA-FL) has emerged as an efficient mechanism that exploits the superposition property of the wireless medium and performs model aggregation for federated learning in the air. OTA-FL is naturally sensitive to wireless channel fading, which could significantly diminish its learning accuracy. To address this challenge, in this paper, we propose an OTA-FL algorithm called CHARLES (channel-quality-aware over-the-air local estimating and scaling). Our CHARLES algorithm performs channel state information (CSI) estimation and adaptive scaling to mitigate the impacts of wireless channel fading. We establish the theoretical convergence rate performance of CHARLES and analyze the impacts of CSI error on the convergence of CHARLES. We show that the adaptive channel inversion scaling scheme in CHARLES is robust under imperfect CSI scenarios. We also demonstrate through numerical results that CHARLES outperforms existing OTA-FL algorithms with heterogeneous data under imperfect CSI.
Over-the-Air Federated Learning with Joint Adaptive Computation and Power Control
May 12, 2022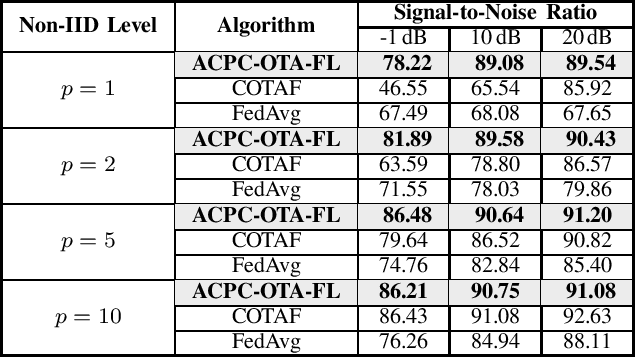
This paper considers over-the-air federated learning (OTA-FL). OTA-FL exploits the superposition property of the wireless medium, and performs model aggregation over the air for free. Thus, it can greatly reduce the communication cost incurred in communicating model updates from the edge devices. In order to fully utilize this advantage while providing comparable learning performance to conventional federated learning that presumes model aggregation via noiseless channels, we consider the joint design of transmission scaling and the number of local iterations at each round, given the power constraint at each edge device. We first characterize the training error due to such channel noise in OTA-FL by establishing a fundamental lower bound for general functions with Lipschitz-continuous gradients. Then, by introducing an adaptive transceiver power scaling scheme, we propose an over-the-air federated learning algorithm with joint adaptive computation and power control (ACPC-OTA-FL). We provide the convergence analysis for ACPC-OTA-FL in training with non-convex objective functions and heterogeneous data. We show that the convergence rate of ACPC-OTA-FL matches that of FL with noise-free communications.