 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness-aware Vision Transformer via Debiased Self-Attention
Paper and Code
Jan 31, 2023

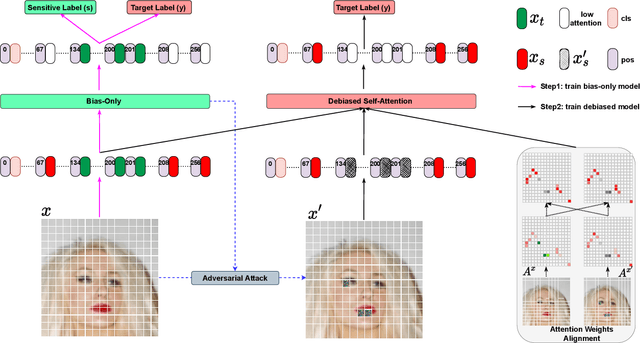
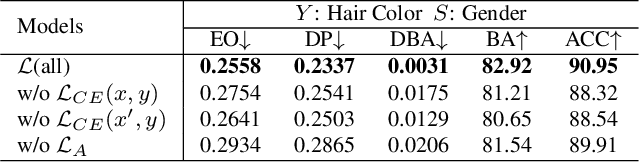
Vision Transformer (ViT) has recently gained significant interest in solving computer vision (CV) problems due to its capability of extracting informative features and modeling long-range dependencies through the self-attention mechanism. To fully realize the advantages of ViT in real-world applications, recent works have explored the trustworthiness of ViT, including its robustness and explainability. However, another desiderata, fairness has not yet been adequately addressed in the literature. We establish that the existing fairness-aware algorithms (primarily designed for CNNs) do not perform well on ViT. This necessitates the need for developing our novel framework via Debiased Self-Attention (DSA). DSA is a fairness-through-blindness approach that enforces ViT to eliminate spurious features correlated with the sensitive attributes for bias mitigation. Notably, adversarial examples are leveraged to locate and mask the spurious features in the input image patches. In addition, DSA utilizes an attention weights alignment regularizer in the training objective to encourage learning informative features for target prediction. Importantly, our DSA framework leads to improved fairness guarantees over prior works on multiple prediction tasks without compromising target prediction performance