 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogicCat: A Chain-of-Thought Text-to-SQL Benchmark for Multi-Domain Reasoning Challenges
May 24, 2025Text-to-SQL is a fundamental task in natural language processing that seeks to translate natural language questions into meaningful and executable SQL queries. While existing datasets are extensive and primarily focus on business scenarios and operational logic, they frequently lack coverage of domain-specific knowledge and complex mathematical reasoning. To address this gap, we present a novel dataset tailored for complex reasoning and chain-of-thought analysis in SQL inference, encompassing physical, arithmetic, commonsense, and hypothetical reasoning. The dataset consists of 4,038 English questions, each paired with a unique SQL query and accompanied by 12,114 step-by-step reasoning annotations, spanning 45 databases across diverse domains. Experimental results demonstrate that LogicCat substantially increases the difficulty for state-of-the-art models, with the highest execution accuracy reaching only 14.96%. Incorporating our chain-of-thought annotations boosts performance to 33.96%. Benchmarking leading public methods on Spider and BIRD further underscores the unique challenges presented by LogicCat, highlighting the significant opportunities for advancing research in robust, reasoning-driven text-to-SQL systems. We have released our dataset code at https://github.com/Ffunkytao/LogicCat.
CMoralEval: A Moral Evaluation Benchmark for Chinese Large Language Models
Aug 19, 2024



What a large language model (LLM) would respond in ethically relevant context? In this paper, we curate a large benchmark CMoralEval for morality evaluation of Chinese LLMs. The data sources of CMoralEval are two-fold: 1) a Chinese TV program discussing Chinese moral norms with stories from the society and 2) a collection of Chinese moral anomies from various newspapers and academic papers on morality. With these sources, we aim to create a moral evaluation dataset characterized by diversity and authenticity. We develop a morality taxonomy and a set of fundamental moral principles that are not only rooted in traditional Chinese culture but also consistent with contemporary societal norms. To facilitate efficient construction and annotation of instances in CMoralEval, we establish a platform with AI-assisted instance generation to streamline the annotation process. These help us curate CMoralEval that encompasses both explicit moral scenarios (14,964 instances) and moral dilemma scenarios (15,424 instances), each with instances from different data sources. We conduct extensive experiments with CMoralEval to examine a variety of Chinese LLMs. Experiment results demonstrate that CMoralEval is a challenging benchmark for Chinese LLMs. The dataset is publicly available at \url{https://github.com/tjunlp-lab/CMoralEval}.
Low-Precision Hardware Architectures Meet Recommendation Model Inference at Scale
May 26, 2021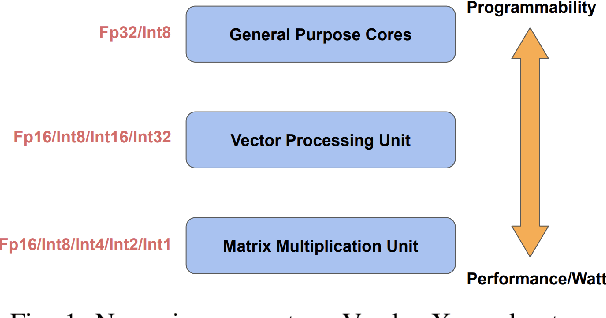
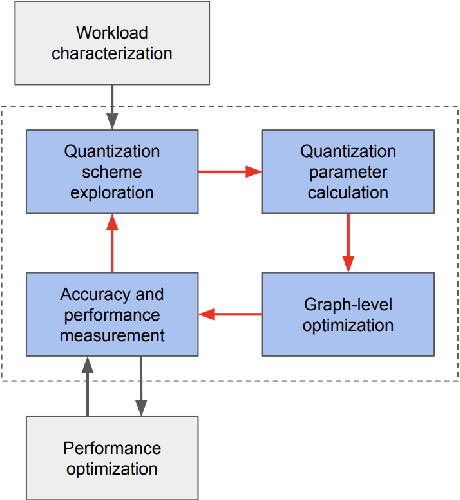
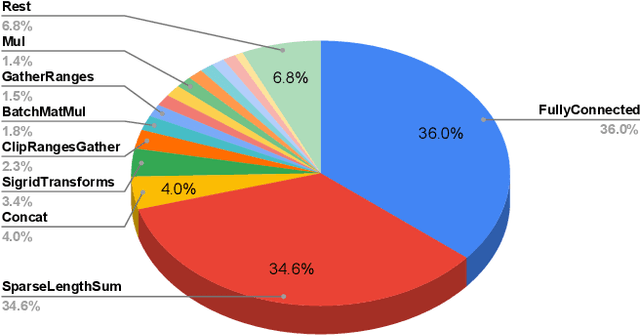
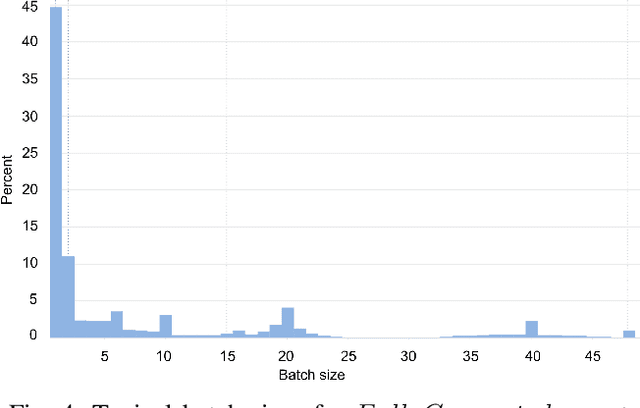
Tremendous success of machine learning (ML) and the unabated growth in ML model complexity motivated many ML-specific designs in both CPU and accelerator architectures to speed up the model inference. While these architectures are diverse, highly optimized low-precision arithmetic is a component shared by most. Impressive compute throughputs are indeed often exhibited by these architectures on benchmark ML models. Nevertheless, production models such as recommendation systems important to Facebook's personalization services are demanding and complex: These systems must serve billions of users per month responsively with low latency while maintaining high prediction accuracy, notwithstanding computations with many tens of billions parameters per inference. Do these low-precision architectures work well with our production recommendation systems? They do. But not without significant effort. We share in this paper our search strategies to adapt reference recommendation models to low-precision hardware, our optimization of low-precision compute kernels, and the design and development of tool chain so as to maintain our models' accuracy throughout their lifespan during which topic trends and users' interests inevitably evolve. Practicing these low-precision technologies helped us save datacenter capacities while deploying models with up to 5X complexity that would otherwise not be deployed on traditional general-purpose CPUs. We believe these lessons from the trenches promote better co-design between hardware architecture and software engineering and advance the state of the art of ML in industry.
FBGEMM: Enabling High-Performance Low-Precision Deep Learning Inference
Jan 13, 2021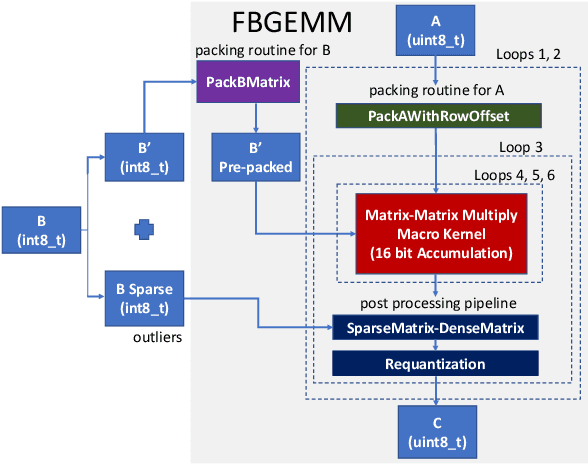
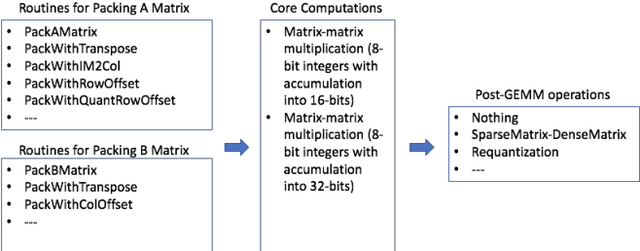
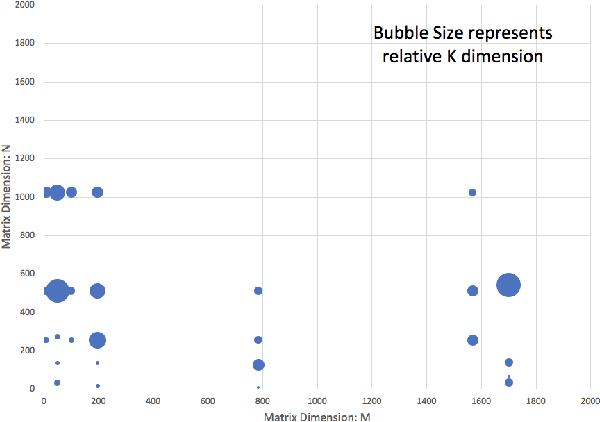
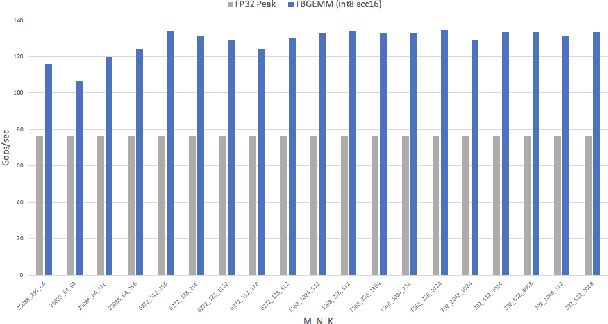
Deep learning models typically use single-precision (FP32) floating point data types for representing activations and weights, but a slew of recent research work has shown that computations with reduced-precision data types (FP16, 16-bit integers, 8-bit integers or even 4- or 2-bit integers) are enough to achieve same accuracy as FP32 and are much more efficient. Therefore, we designed fbgemm, a high-performance kernel library, from ground up to perform high-performance quantized inference on current generation CPUs. fbgemm achieves efficiency by fusing common quantization operations with a high-performance gemm implementation and by shape- and size-specific kernel code generation at runtime. The library has been deployed at Facebook, where it delivers greater than 2x performance gains with respect to our current production baseline.