 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumos: Efficient Performance Modeling and Estimation for Large-scale LLM Training
Apr 12, 2025Training LLMs in distributed environments presents significant challenges due to the complexity of model execution, deployment systems, and the vast space of configurable strategies. Although various optimization techniques exist, achieving high efficiency in practice remains difficult. Accurate performance models that effectively characterize and predict a model's behavior are essential for guiding optimization efforts and system-level studies. We propose Lumos, a trace-driven performance modeling and estimation toolkit for large-scale LLM training, designed to accurately capture and predict the execution behaviors of modern LLMs. We evaluate Lumos on a production ML cluster with up to 512 NVIDIA H100 GPUs using various GPT-3 variants, demonstrating that it can replay execution time with an average error of just 3.3%, along with other runtime details, across different models and configurations. Additionally, we validate its ability to estimate performance for new setups from existing traces, facilitating efficient exploration of model and deployment configurations.
MTrainS: Improving DLRM training efficiency using heterogeneous memories
Apr 19, 2023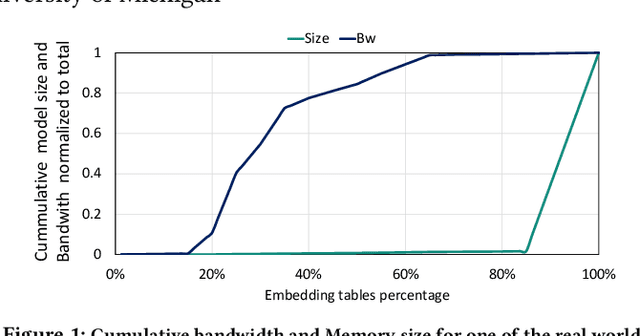
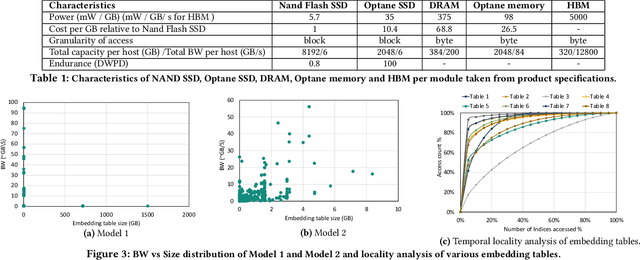
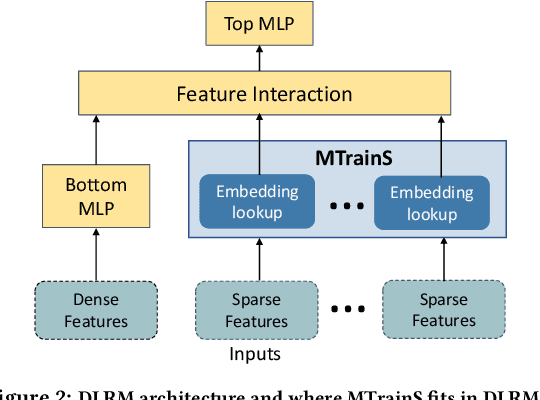

Recommendation models are very large, requiring terabytes (TB) of memory during training. In pursuit of better quality, the model size and complexity grow over time, which requires additional training data to avoid overfitting. This model growth demands a large number of resources in data centers. Hence, training efficiency is becoming considerably more important to keep the data center power demand manageable. In Deep Learning Recommendation Models (DLRM), sparse features capturing categorical inputs through embedding tables are the major contributors to model size and require high memory bandwidth. In this paper, we study the bandwidth requirement and locality of embedding tables in real-world deployed models. We observe that the bandwidth requirement is not uniform across different tables and that embedding tables show high temporal locality. We then design MTrainS, which leverages heterogeneous memory, including byte and block addressable Storage Class Memory for DLRM hierarchically. MTrainS allows for higher memory capacity per node and increases training efficiency by lowering the need to scale out to multiple hosts in memory capacity bound use cases. By optimizing the platform memory hierarchy, we reduce the number of nodes for training by 4-8X, saving power and cost of training while meeting our target training performance.