 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposer 2 Technical Report
Mar 25, 2026Composer 2 is a specialized model designed for agentic software engineering. The model demonstrates strong long-term planning and coding intelligence while maintaining the ability to efficiently solve problems for interactive use. The model is trained in two phases: first, continued pretraining to improve the model's knowledge and latent coding ability, followed by large-scale reinforcement learning to improve end-to-end coding performance through stronger reasoning, accurate multi-step execution, and coherence on long-horizon realistic coding problems. We develop infrastructure to support training in the same Cursor harness that is used by the deployed model, with equivalent tools and structure, and use environments that match real problems closely. To measure the ability of the model on increasingly difficult tasks, we introduce a benchmark derived from real software engineering problems in large codebases including our own. Composer 2 is a frontier-level coding model and demonstrates a process for training strong domain-specialized models. On our CursorBench evaluations the model achieves a major improvement in accuracy compared to previous Composer models (61.3). On public benchmarks the model scores 61.7 on Terminal-Bench and 73.7 on SWE-bench Multilingual in our harness, comparable to state-of-the-art systems.
Accelerating Neural Network Training: An Analysis of the AlgoPerf Competition
Feb 20, 2025



The goal of the AlgoPerf: Training Algorithms competition is to evaluate practical speed-ups in neural network training achieved solely by improving the underlying training algorithms. In the external tuning ruleset, submissions must provide workload-agnostic hyperparameter search spaces, while in the self-tuning ruleset they must be completely hyperparameter-free. In both rulesets, submissions are compared on time-to-result across multiple deep learning workloads, training on fixed hardware. This paper presents the inaugural AlgoPerf competition's results, which drew 18 diverse submissions from 10 teams. Our investigation reveals several key findings: (1) The winning submission in the external tuning ruleset, using Distributed Shampoo, demonstrates the effectiveness of non-diagonal preconditioning over popular methods like Adam, even when compared on wall-clock runtime. (2) The winning submission in the self-tuning ruleset, based on the Schedule Free AdamW algorithm, demonstrates a new level of effectiveness for completely hyperparameter-free training algorithms. (3) The top-scoring submissions were surprisingly robust to workload changes. We also discuss the engineering challenges encountered in ensuring a fair comparison between different training algorithms. These results highlight both the significant progress so far, and the considerable room for further improvements.
HadaCore: Tensor Core Accelerated Hadamard Transform Kernel
Dec 12, 2024We present HadaCore, a modified Fast Walsh-Hadamard Transform (FWHT) algorithm optimized for the Tensor Cores present in modern GPU hardware. HadaCore follows the recursive structure of the original FWHT algorithm, achieving the same asymptotic runtime complexity but leveraging a hardware-aware work decomposition that benefits from Tensor Core acceleration. This reduces bottlenecks from compute and data exchange. On Nvidia A100 and H100 GPUs, HadaCore achieves speedups of 1.1-1.4x and 1.0-1.3x, with a peak gain of 3.5x and 3.6x respectively, when compared to the existing state-of-the-art implementation of the original algorithm. We also show that when using FP16 or BF16, our implementation is numerically accurate, enabling comparable accuracy on MMLU benchmarks when used in an end-to-end Llama3 inference run with quantized (FP8) attention.
TorchTitan: One-stop PyTorch native solution for production ready LLM pre-training
Oct 09, 2024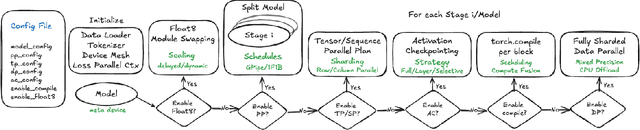



The development of large language models (LLMs) has been instrumental in advancing state-of-the-art natural language processing applications. Training LLMs with billions of parameters and trillions of tokens require sophisticated distributed systems that enable composing and comparing several state-of-the-art techniques in order to efficiently scale across thousands of accelerators. However, existing solutions are complex, scattered across multiple libraries/repositories, lack interoperability, and are cumbersome to maintain. Thus, curating and empirically comparing training recipes require non-trivial engineering effort. This paper introduces TorchTitan, an open-source, PyTorch-native distributed training system that unifies state-of-the-art techniques, streamlining integration and reducing overhead. TorchTitan enables 3D parallelism in a modular manner with elastic scaling, providing comprehensive logging, checkpointing, and debugging tools for production-ready training. It also incorporates hardware-software co-designed solutions, leveraging features like Float8 training and SymmetricMemory. As a flexible test bed, TorchTitan facilitates custom recipe curation and comparison, allowing us to develop optimized training recipes for Llama 3.1 and provide guidance on selecting techniques for maximum efficiency based on our experiences. We thoroughly assess TorchTitan on the Llama 3.1 family of LLMs, spanning 8 billion to 405 billion parameters, and showcase its exceptional performance, modular composability, and elastic scalability. By stacking training optimizations, we demonstrate accelerations of 65.08% with 1D parallelism at the 128-GPU scale (Llama 3.1 8B), an additional 12.59% with 2D parallelism at the 256-GPU scale (Llama 3.1 70B), and an additional 30% with 3D parallelism at the 512-GPU scale (Llama 3.1 405B) on NVIDIA H100 GPUs over optimized baselines.
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Apr 21, 2023It is widely acknowledged that large models have the potential to deliver superior performance across a broad range of domains. Despite the remarkable progress made in the field of machine learning systems research, which has enabled the development and exploration of large models, such abilities remain confined to a small group of advanced users and industry leaders, resulting in an implicit technical barrier for the wider community to access and leverage these technologies. In this paper, we introduce PyTorch Fully Sharded Data Parallel (FSDP) as an industry-grade solution for large model training. FSDP has been closely co-designed with several key PyTorch core components including Tensor implementation, dispatcher system, and CUDA memory caching allocator, to provide non-intrusive user experiences and high training efficiency. Additionally, FSDP natively incorporates a range of techniques and settings to optimize resource utilization across a variety of hardware configurations. The experimental results demonstrate that FSDP is capable of achieving comparable performance to Distributed Data Parallel while providing support for significantly larger models with near-linear scalability in terms of TFLOPS.
Ranger21: a synergistic deep learning optimizer
Jun 25, 2021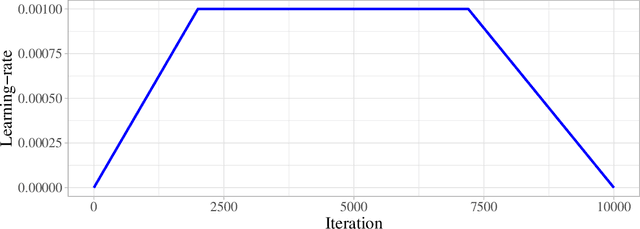
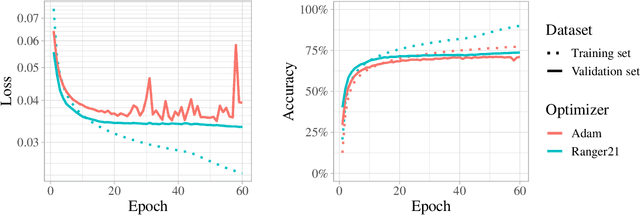
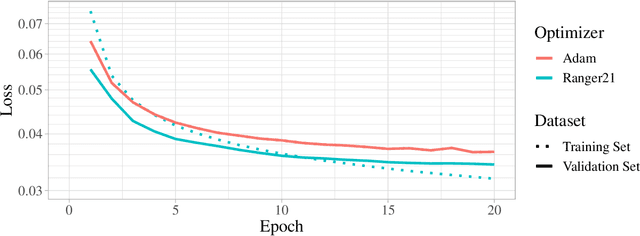
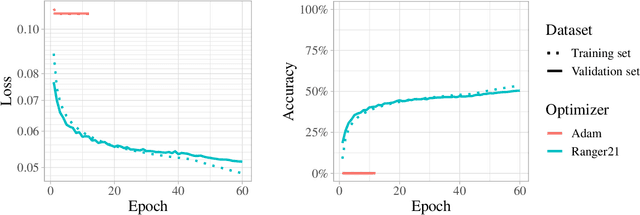
As optimizers are critical to the performances of neural networks, every year a large number of papers innovating on the subject are published. However, while most of these publications provide incremental improvements to existing algorithms, they tend to be presented as new optimizers rather than composable algorithms. Thus, many worthwhile improvements are rarely seen out of their initial publication. Taking advantage of this untapped potential, we introduce Ranger21, a new optimizer which combines AdamW with eight components, carefully selected after reviewing and testing ideas from the literature. We found that the resulting optimizer provides significantly improved validation accuracy and training speed, smoother training curves, and is even able to train a ResNet50 on ImageNet2012 without Batch Normalization layers. A problem on which AdamW stays systematically stuck in a bad initial state.