 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimpleFSDP: Simpler Fully Sharded Data Parallel with torch.compile
Nov 01, 2024


Distributed training of large models consumes enormous computation resources and requires substantial engineering efforts to compose various training techniques. This paper presents SimpleFSDP, a PyTorch-native compiler-based Fully Sharded Data Parallel (FSDP) framework, which has a simple implementation for maintenance and composability, allows full computation-communication graph tracing, and brings performance enhancement via compiler backend optimizations. SimpleFSDP's novelty lies in its unique torch.compile-friendly implementation of collective communications using existing PyTorch primitives, namely parametrizations, selective activation checkpointing, and DTensor. It also features the first-of-its-kind intermediate representation (IR) nodes bucketing and reordering in the TorchInductor backend for effective computation-communication overlapping. As a result, users can employ the aforementioned optimizations to automatically or manually wrap model components for minimal communication exposure. Extensive evaluations of SimpleFSDP on Llama 3 models (including the ultra-large 405B) using TorchTitan demonstrate up to 28.54% memory reduction and 68.67% throughput improvement compared to the most widely adopted FSDP2 eager framework, when composed with other distributed training techniques.
TorchTitan: One-stop PyTorch native solution for production ready LLM pre-training
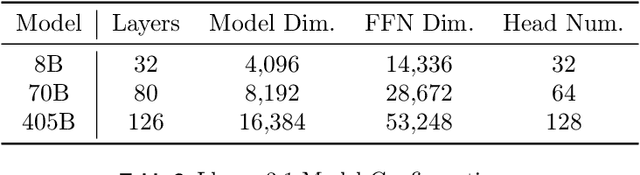
Oct 09, 2024



The development of large language models (LLMs) has been instrumental in advancing state-of-the-art natural language processing applications. Training LLMs with billions of parameters and trillions of tokens require sophisticated distributed systems that enable composing and comparing several state-of-the-art techniques in order to efficiently scale across thousands of accelerators. However, existing solutions are complex, scattered across multiple libraries/repositories, lack interoperability, and are cumbersome to maintain. Thus, curating and empirically comparing training recipes require non-trivial engineering effort. This paper introduces TorchTitan, an open-source, PyTorch-native distributed training system that unifies state-of-the-art techniques, streamlining integration and reducing overhead. TorchTitan enables 3D parallelism in a modular manner with elastic scaling, providing comprehensive logging, checkpointing, and debugging tools for production-ready training. It also incorporates hardware-software co-designed solutions, leveraging features like Float8 training and SymmetricMemory. As a flexible test bed, TorchTitan facilitates custom recipe curation and comparison, allowing us to develop optimized training recipes for Llama 3.1 and provide guidance on selecting techniques for maximum efficiency based on our experiences. We thoroughly assess TorchTitan on the Llama 3.1 family of LLMs, spanning 8 billion to 405 billion parameters, and showcase its exceptional performance, modular composability, and elastic scalability. By stacking training optimizations, we demonstrate accelerations of 65.08% with 1D parallelism at the 128-GPU scale (Llama 3.1 8B), an additional 12.59% with 2D parallelism at the 256-GPU scale (Llama 3.1 70B), and an additional 30% with 3D parallelism at the 512-GPU scale (Llama 3.1 405B) on NVIDIA H100 GPUs over optimized baselines.