 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimpleFSDP: Simpler Fully Sharded Data Parallel with torch.compile
Nov 01, 2024


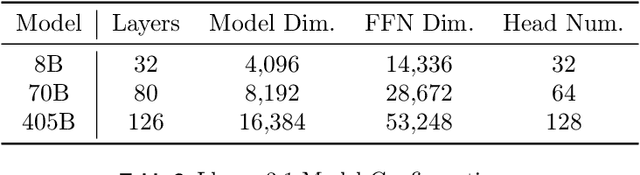
Distributed training of large models consumes enormous computation resources and requires substantial engineering efforts to compose various training techniques. This paper presents SimpleFSDP, a PyTorch-native compiler-based Fully Sharded Data Parallel (FSDP) framework, which has a simple implementation for maintenance and composability, allows full computation-communication graph tracing, and brings performance enhancement via compiler backend optimizations. SimpleFSDP's novelty lies in its unique torch.compile-friendly implementation of collective communications using existing PyTorch primitives, namely parametrizations, selective activation checkpointing, and DTensor. It also features the first-of-its-kind intermediate representation (IR) nodes bucketing and reordering in the TorchInductor backend for effective computation-communication overlapping. As a result, users can employ the aforementioned optimizations to automatically or manually wrap model components for minimal communication exposure. Extensive evaluations of SimpleFSDP on Llama 3 models (including the ultra-large 405B) using TorchTitan demonstrate up to 28.54% memory reduction and 68.67% throughput improvement compared to the most widely adopted FSDP2 eager framework, when composed with other distributed training techniques.
Mastering the Dungeon: Grounded Language Learning by Mechanical Turker Descent
Apr 16, 2018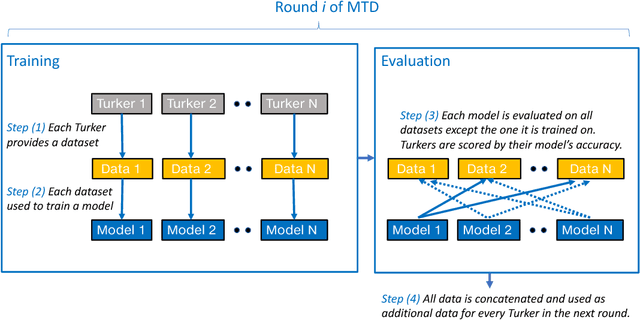
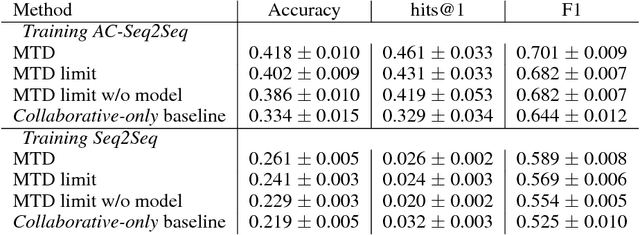

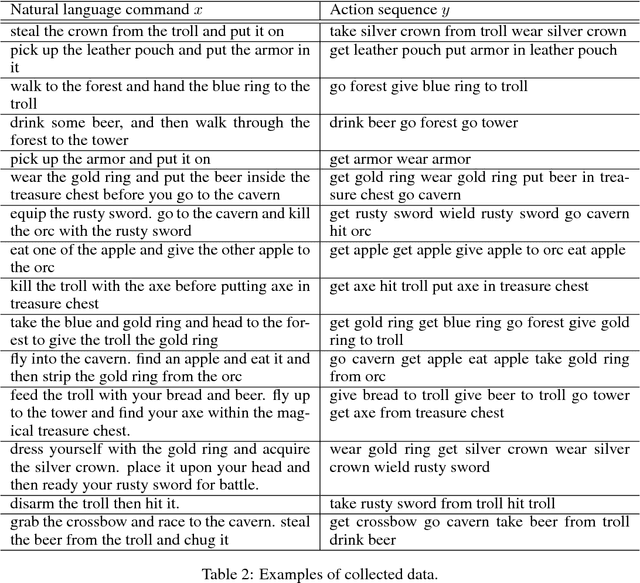
Contrary to most natural language processing research, which makes use of static datasets, humans learn language interactively, grounded in an environment. In this work we propose an interactive learning procedure called Mechanical Turker Descent (MTD) and use it to train agents to execute natural language commands grounded in a fantasy text adventure game. In MTD, Turkers compete to train better agents in the short term, and collaborate by sharing their agents' skills in the long term. This results in a gamified, engaging experience for the Turkers and a better quality teaching signal for the agents compared to static datasets, as the Turkers naturally adapt the training data to the agent's abilities.
ParlAI: A Dialog Research Software Platform
Mar 08, 2018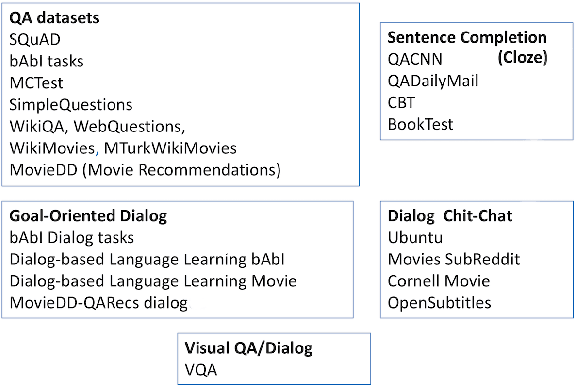
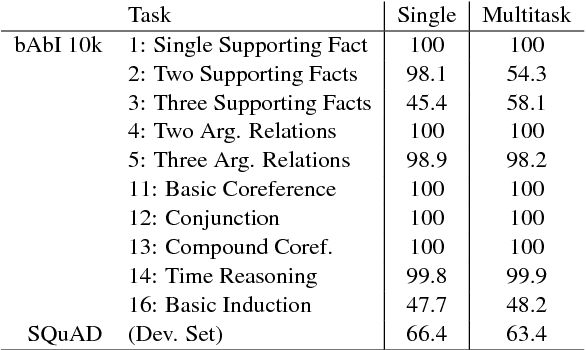
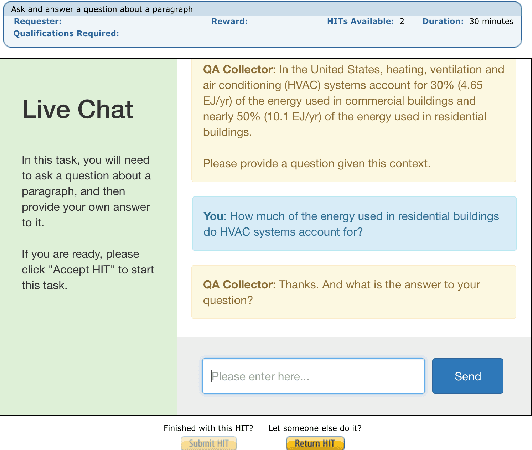

We introduce ParlAI (pronounced "par-lay"), an open-source software platform for dialog research implemented in Python, available at http://parl.ai. Its goal is to provide a unified framework for sharing, training and testing of dialog models, integration of Amazon Mechanical Turk for data collection, human evaluation, and online/reinforcement learning; and a repository of machine learning models for comparing with others' models, and improving upon existing architectures. Over 20 tasks are supported in the first release, including popular datasets such as SQuAD, bAbI tasks, MCTest, WikiQA, QACNN, QADailyMail, CBT, bAbI Dialog, Ubuntu, OpenSubtitles and VQA. Several models are integrated, including neural models such as memory networks, seq2seq and attentive LSTMs.