 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling and Distilling Transformer Models for sEMG
Jul 29, 2025Surface electromyography (sEMG) signals offer a promising avenue for developing innovative human-computer interfaces by providing insights into muscular activity. However, the limited volume of training data and computational constraints during deployment have restricted the investigation of scaling up the model size for solving sEMG tasks. In this paper, we demonstrate that vanilla transformer models can be effectively scaled up on sEMG data and yield improved cross-user performance up to 110M parameters, surpassing the model size regime investigated in other sEMG research (usually <10M parameters). We show that >100M-parameter models can be effectively distilled into models 50x smaller with minimal loss of performance (<1.5% absolute). This results in efficient and expressive models suitable for complex real-time sEMG tasks in real-world environments.
AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Jul 03, 2025AI research agents are demonstrating great potential to accelerate scientific progress by automating the design, implementation, and training of machine learning models. We focus on methods for improving agents' performance on MLE-bench, a challenging benchmark where agents compete in Kaggle competitions to solve real-world machine learning problems. We formalize AI research agents as search policies that navigate a space of candidate solutions, iteratively modifying them using operators. By designing and systematically varying different operator sets and search policies (Greedy, MCTS, Evolutionary), we show that their interplay is critical for achieving high performance. Our best pairing of search strategy and operator set achieves a state-of-the-art result on MLE-bench lite, increasing the success rate of achieving a Kaggle medal from 39.6% to 47.7%. Our investigation underscores the importance of jointly considering the search strategy, operator design, and evaluation methodology in advancing automated machine learning.
The NetHack Learning Environment
Jun 24, 2020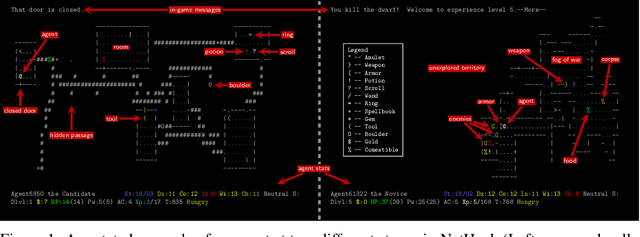
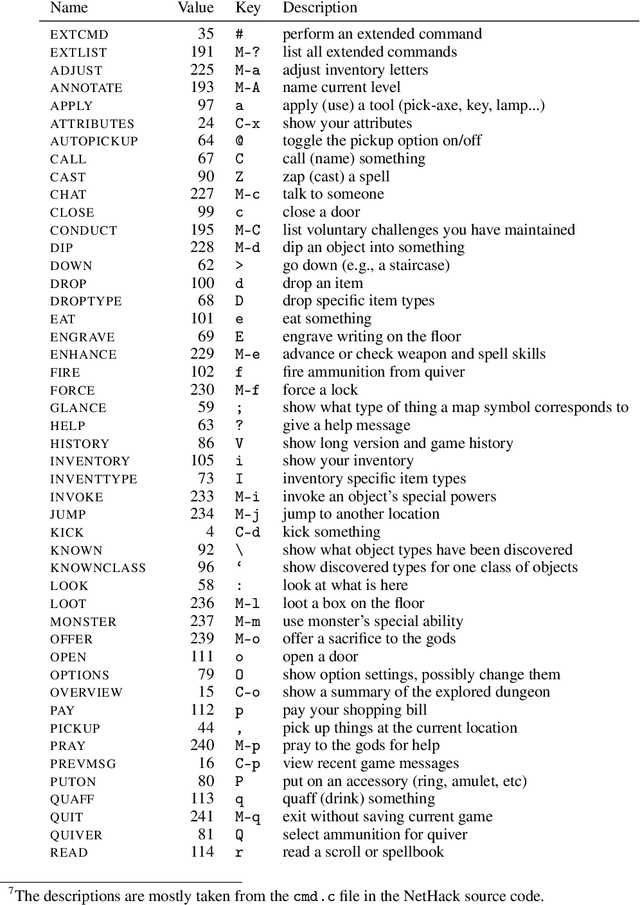
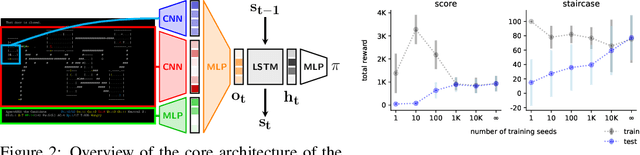
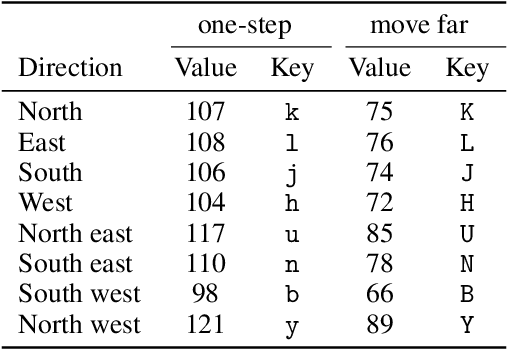
Progress in Reinforcement Learning (RL) algorithms goes hand-in-hand with the development of challenging environments that test the limits of current methods. While existing RL environments are either sufficiently complex or based on fast simulation, they are rarely both. Here, we present the NetHack Learning Environment (NLE), a scalable, procedurally generated, stochastic, rich, and challenging environment for RL research based on the popular single-player terminal-based roguelike game, NetHack. We argue that NetHack is sufficiently complex to drive long-term research on problems such as exploration, planning, skill acquisition, and language-conditioned RL, while dramatically reducing the computational resources required to gather a large amount of experience. We compare NLE and its task suite to existing alternatives, and discuss why it is an ideal medium for testing the robustness and systematic generalization of RL agents. We demonstrate empirical success for early stages of the game using a distributed Deep RL baseline and Random Network Distillation exploration, alongside qualitative analysis of various agents trained in the environment. NLE is open source at https://github.com/facebookresearch/nle.
How Context Affects Language Models' Factual Predictions
May 10, 2020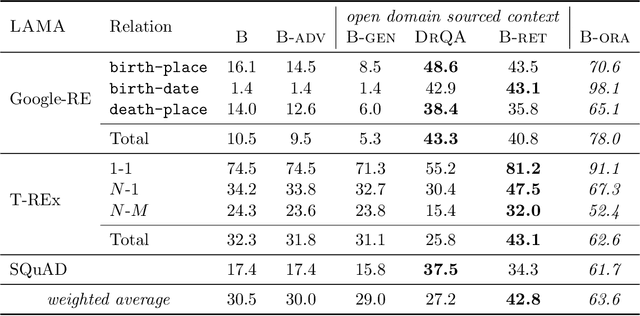
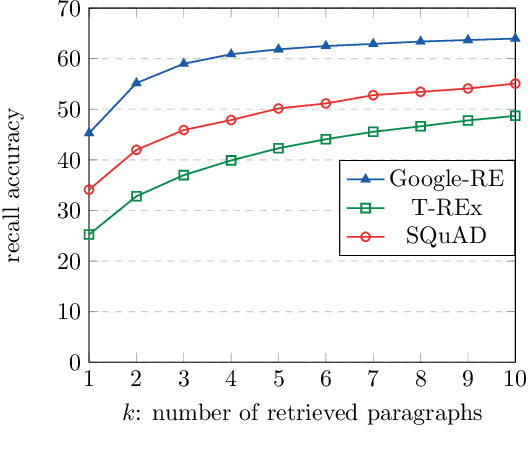
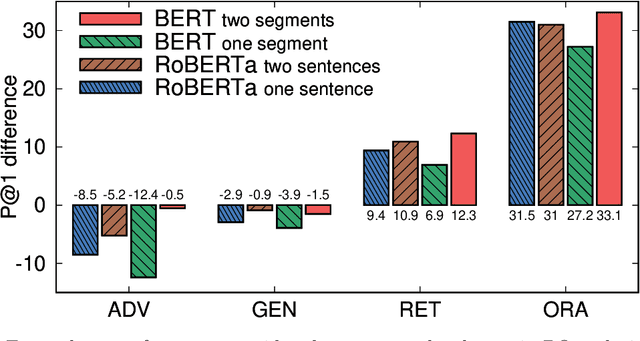
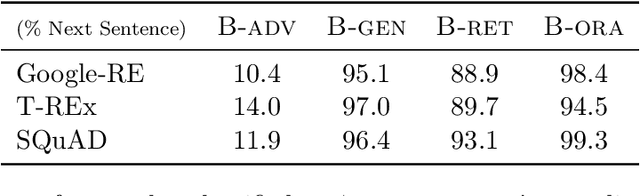
When pre-trained on large unsupervised textual corpora, language models are able to store and retrieve factual knowledge to some extent, making it possible to use them directly for zero-shot cloze-style question answering. However, storing factual knowledge in a fixed number of weights of a language model clearly has limitations. Previous approaches have successfully provided access to information outside the model weights using supervised architectures that combine an information retrieval system with a machine reading component. In this paper, we go a step further and integrate information from a retrieval system with a pre-trained language model in a purely unsupervised way. We report that augmenting pre-trained language models in this way dramatically improves performance and that the resulting system, despite being unsupervised, is competitive with a supervised machine reading baseline. Furthermore, processing query and context with different segment tokens allows BERT to utilize its Next Sentence Prediction pre-trained classifier to determine whether the context is relevant or not, substantially improving BERT's zero-shot cloze-style question-answering performance and making its predictions robust to noisy contexts.
MVFST-RL: An Asynchronous RL Framework for Congestion Control with Delayed Actions
Oct 30, 2019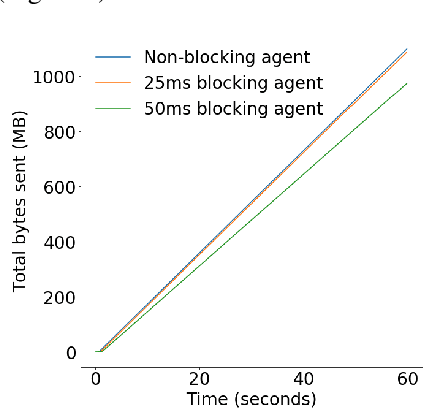
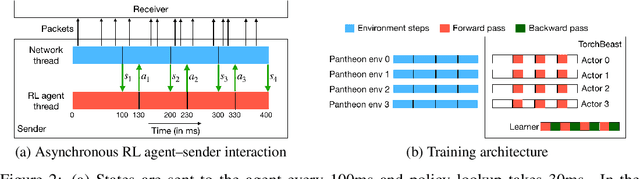
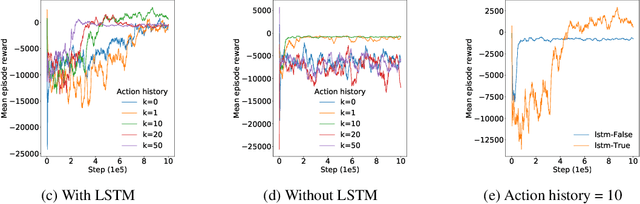
Effective network congestion control strategies are key to keeping the Internet (or any large computer network) operational. Network congestion control has been dominated by hand-crafted heuristics for decades. Recently, ReinforcementLearning (RL) has emerged as an alternative to automatically optimize such control strategies. Research so far has primarily considered RL interfaces which block the sender while an agent considers its next action. This is largely an artifact of building on top of frameworks designed for RL in games (e.g. OpenAI Gym). However, this does not translate to real-world networking environments, where a network sender waiting on a policy without sending data leads to under-utilization of bandwidth. We instead propose to formulate congestion control with an asynchronous RL agent that handles delayed actions. We present MVFST-RL, a scalable framework for congestion control in the QUIC transport protocol that leverages state-of-the-art in asynchronous RL training with off-policy correction. We analyze modeling improvements to mitigate the deviation from Markovian dynamics, and evaluate our method on emulated networks from the Pantheon benchmark platform. The source code is publicly available at https://github.com/facebookresearch/mvfst-rl.
Language Models as Knowledge Bases?
Sep 04, 2019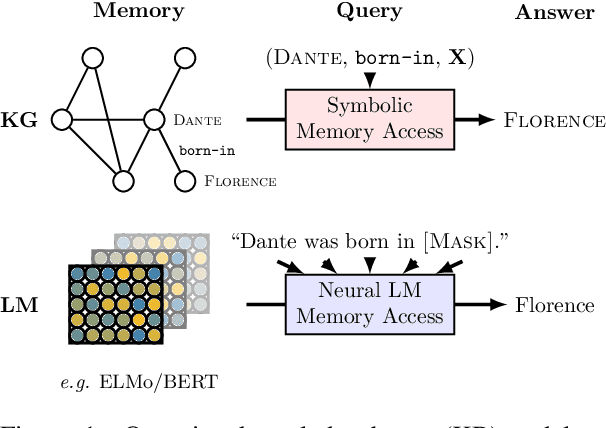
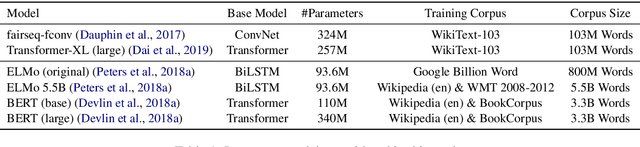
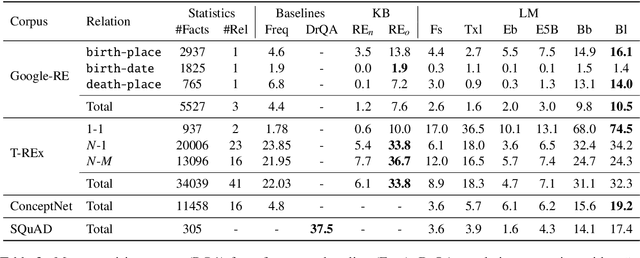
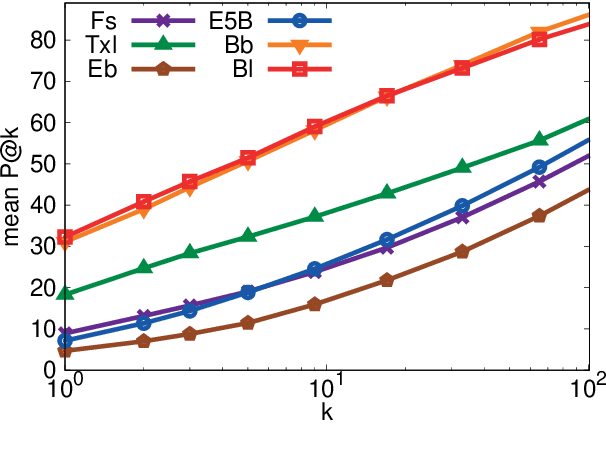
Recent progress in pretraining language models on large textual corpora led to a surge of improvements for downstream NLP tasks. Whilst learning linguistic knowledge, these models may also be storing relational knowledge present in the training data, and may be able to answer queries structured as "fill-in-the-blank" cloze statements. Language models have many advantages over structured knowledge bases: they require no schema engineering, allow practitioners to query about an open class of relations, are easy to extend to more data, and require no human supervision to train. We present an in-depth analysis of the relational knowledge already present (without fine-tuning) in a wide range of state-of-the-art pretrained language models. We find that (i) without fine-tuning, BERT contains relational knowledge competitive with traditional NLP methods that have some access to oracle knowledge, (ii) BERT also does remarkably well on open-domain question answering against a supervised baseline, and (iii) certain types of factual knowledge are learned much more readily than others by standard language model pretraining approaches. The surprisingly strong ability of these models to recall factual knowledge without any fine-tuning demonstrates their potential as unsupervised open-domain QA systems. The code to reproduce our analysis is available at https://github.com/facebookresearch/LAMA.
Importance of a Search Strategy in Neural Dialogue Modelling
Nov 02, 2018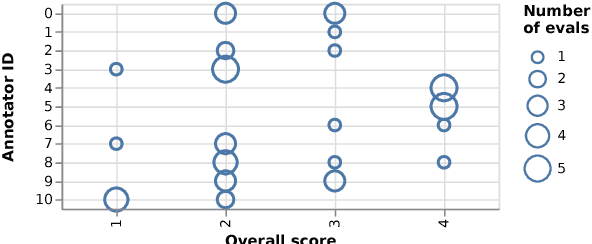

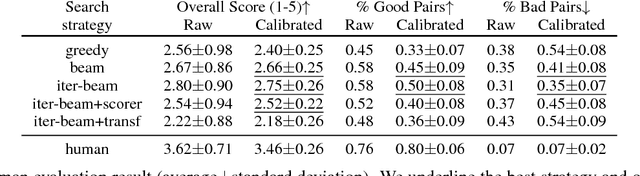
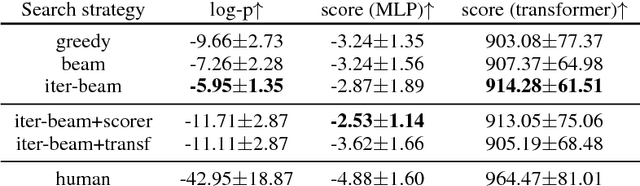
Search strategies for generating a response from a neural dialogue model have received relatively little attention compared to improving network architectures and learning algorithms in recent years. In this paper, we consider a standard neural dialogue model based on recurrent networks with an attention mechanism, and focus on evaluating the impact of the search strategy. We compare four search strategies: greedy search, beam search, iterative beam search and iterative beam search followed by selection scoring. We evaluate these strategies using human evaluation of full conversations and compare them using automatic metrics including log-probabilities, scores and diversity metrics. We observe a significant gap between greedy search and the proposed iterative beam search augmented with selection scoring, demonstrating the importance of the search algorithm in neural dialogue generation.
Retrieve and Refine: Improved Sequence Generation Models For Dialogue
Sep 06, 2018
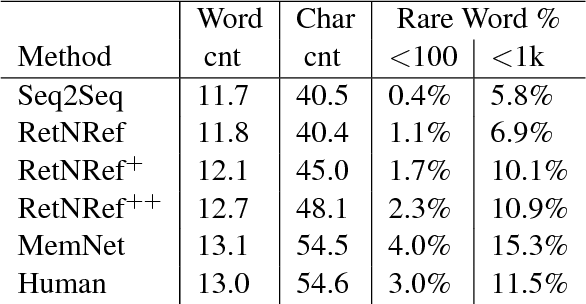
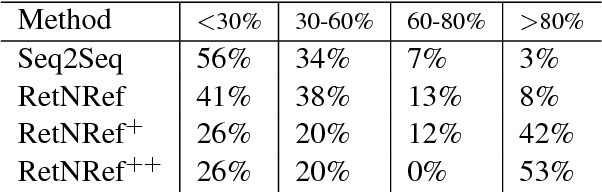
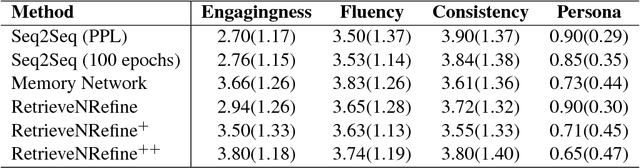
Sequence generation models for dialogue are known to have several problems: they tend to produce short, generic sentences that are uninformative and unengaging. Retrieval models on the other hand can surface interesting responses, but are restricted to the given retrieval set leading to erroneous replies that cannot be tuned to the specific context. In this work we develop a model that combines the two approaches to avoid both their deficiencies: first retrieve a response and then refine it -- the final sequence generator treating the retrieval as additional context. We show on the recent CONVAI2 challenge task our approach produces responses superior to both standard retrieval and generation models in human evaluations.
Mastering the Dungeon: Grounded Language Learning by Mechanical Turker Descent
Apr 16, 2018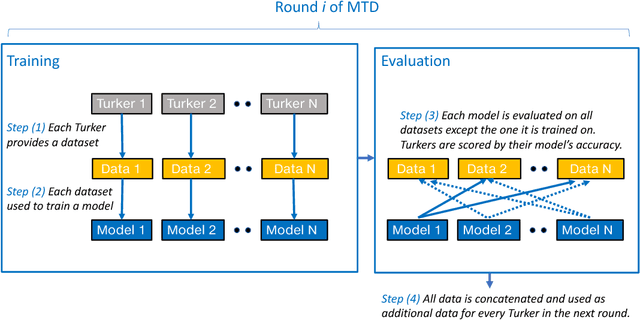
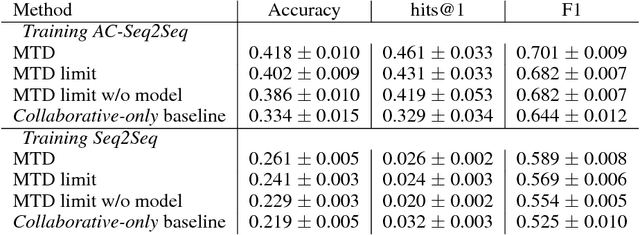

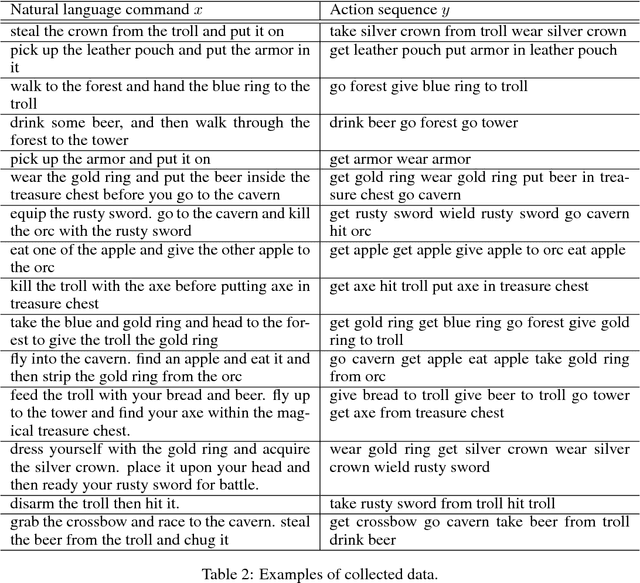
Contrary to most natural language processing research, which makes use of static datasets, humans learn language interactively, grounded in an environment. In this work we propose an interactive learning procedure called Mechanical Turker Descent (MTD) and use it to train agents to execute natural language commands grounded in a fantasy text adventure game. In MTD, Turkers compete to train better agents in the short term, and collaborate by sharing their agents' skills in the long term. This results in a gamified, engaging experience for the Turkers and a better quality teaching signal for the agents compared to static datasets, as the Turkers naturally adapt the training data to the agent's abilities.
ParlAI: A Dialog Research Software Platform
Mar 08, 2018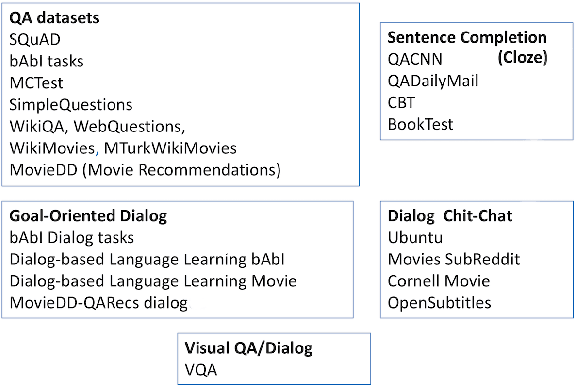
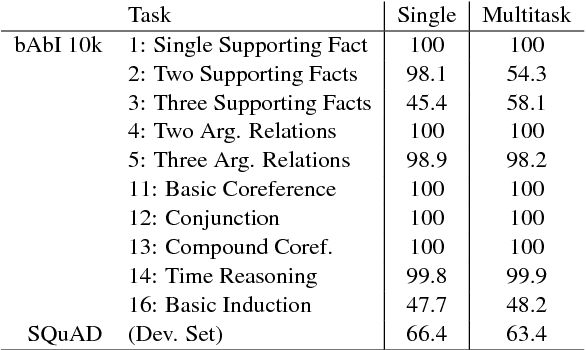
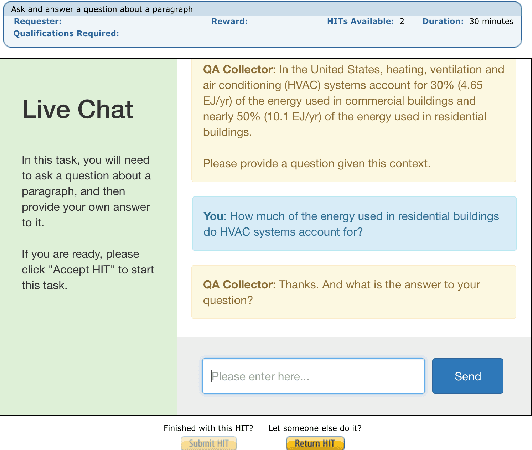

We introduce ParlAI (pronounced "par-lay"), an open-source software platform for dialog research implemented in Python, available at http://parl.ai. Its goal is to provide a unified framework for sharing, training and testing of dialog models, integration of Amazon Mechanical Turk for data collection, human evaluation, and online/reinforcement learning; and a repository of machine learning models for comparing with others' models, and improving upon existing architectures. Over 20 tasks are supported in the first release, including popular datasets such as SQuAD, bAbI tasks, MCTest, WikiQA, QACNN, QADailyMail, CBT, bAbI Dialog, Ubuntu, OpenSubtitles and VQA. Several models are integrated, including neural models such as memory networks, seq2seq and attentive LSTMs.