Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieve and Refine: Improved Sequence Generation Models For Dialogue
Paper and Code
Sep 06, 2018
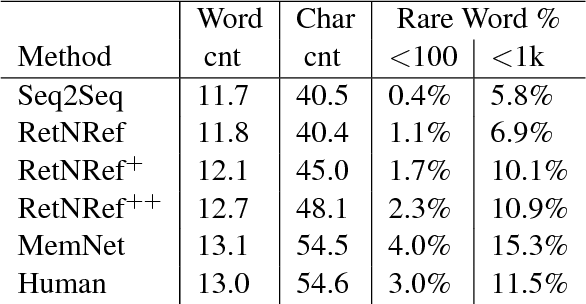
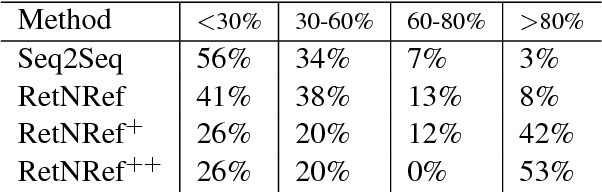
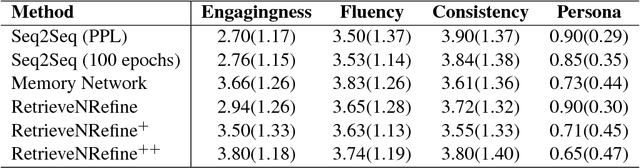
Sequence generation models for dialogue are known to have several problems: they tend to produce short, generic sentences that are uninformative and unengaging. Retrieval models on the other hand can surface interesting responses, but are restricted to the given retrieval set leading to erroneous replies that cannot be tuned to the specific context. In this work we develop a model that combines the two approaches to avoid both their deficiencies: first retrieve a response and then refine it -- the final sequence generator treating the retrieval as additional context. We show on the recent CONVAI2 challenge task our approach produces responses superior to both standard retrieval and generation models in human evaluations.
View paper on