 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeemg2qwerty: A Large Dataset with Baselines for Touch Typing using Surface Electromyography
Oct 26, 2024



Surface electromyography (sEMG) non-invasively measures signals generated by muscle activity with sufficient sensitivity to detect individual spinal neurons and richness to identify dozens of gestures and their nuances. Wearable wrist-based sEMG sensors have the potential to offer low friction, subtle, information rich, always available human-computer inputs. To this end, we introduce emg2qwerty, a large-scale dataset of non-invasive electromyographic signals recorded at the wrists while touch typing on a QWERTY keyboard, together with ground-truth annotations and reproducible baselines. With 1,135 sessions spanning 108 users and 346 hours of recording, this is the largest such public dataset to date. These data demonstrate non-trivial, but well defined hierarchical relationships both in terms of the generative process, from neurons to muscles and muscle combinations, as well as in terms of domain shift across users and user sessions. Applying standard modeling techniques from the closely related field of Automatic Speech Recognition (ASR), we show strong baseline performance on predicting key-presses using sEMG signals alone. We believe the richness of this task and dataset will facilitate progress in several problems of interest to both the machine learning and neuroscientific communities. Dataset and code can be accessed at https://github.com/facebookresearch/emg2qwerty.
MVFST-RL: An Asynchronous RL Framework for Congestion Control with Delayed Actions
Oct 30, 2019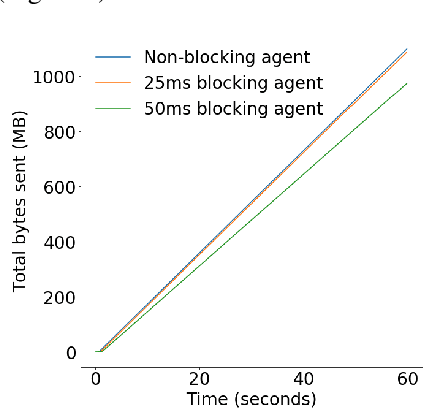
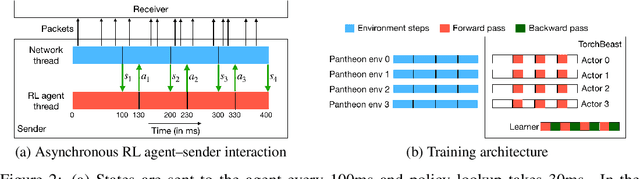
Effective network congestion control strategies are key to keeping the Internet (or any large computer network) operational. Network congestion control has been dominated by hand-crafted heuristics for decades. Recently, ReinforcementLearning (RL) has emerged as an alternative to automatically optimize such control strategies. Research so far has primarily considered RL interfaces which block the sender while an agent considers its next action. This is largely an artifact of building on top of frameworks designed for RL in games (e.g. OpenAI Gym). However, this does not translate to real-world networking environments, where a network sender waiting on a policy without sending data leads to under-utilization of bandwidth. We instead propose to formulate congestion control with an asynchronous RL agent that handles delayed actions. We present MVFST-RL, a scalable framework for congestion control in the QUIC transport protocol that leverages state-of-the-art in asynchronous RL training with off-policy correction. We analyze modeling improvements to mitigate the deviation from Markovian dynamics, and evaluate our method on emulated networks from the Pantheon benchmark platform. The source code is publicly available at https://github.com/facebookresearch/mvfst-rl.
Rosetta: Large scale system for text detection and recognition in images
Oct 11, 2019
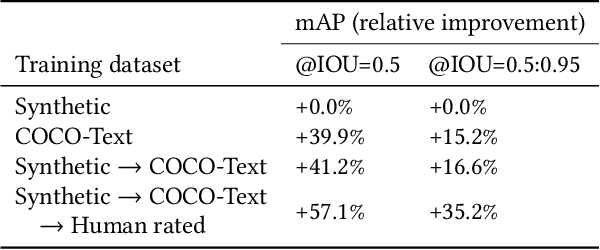
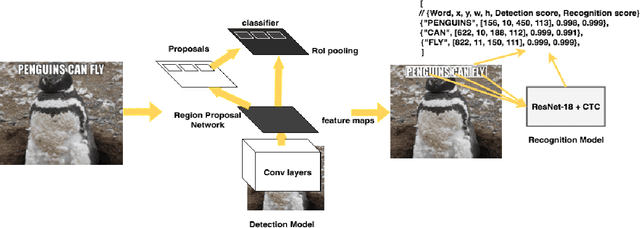

In this paper we present a deployed, scalable optical character recognition (OCR) system, which we call Rosetta, designed to process images uploaded daily at Facebook scale. Sharing of image content has become one of the primary ways to communicate information among internet users within social networks such as Facebook and Instagram, and the understanding of such media, including its textual information, is of paramount importance to facilitate search and recommendation applications. We present modeling techniques for efficient detection and recognition of text in images and describe Rosetta's system architecture. We perform extensive evaluation of presented technologies, explain useful practical approaches to build an OCR system at scale, and provide insightful intuitions as to why and how certain components work based on the lessons learnt during the development and deployment of the system.
TorchBeast: A PyTorch Platform for Distributed RL
Oct 08, 2019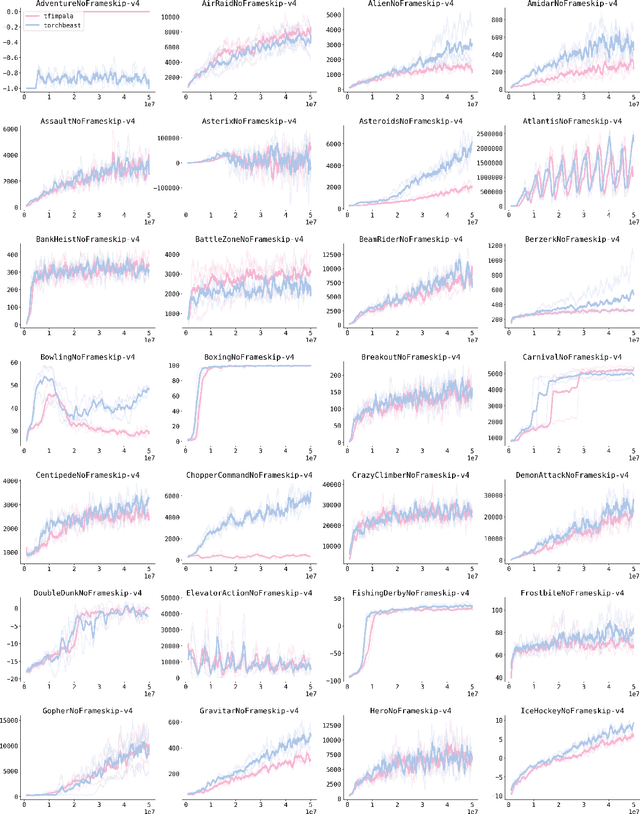
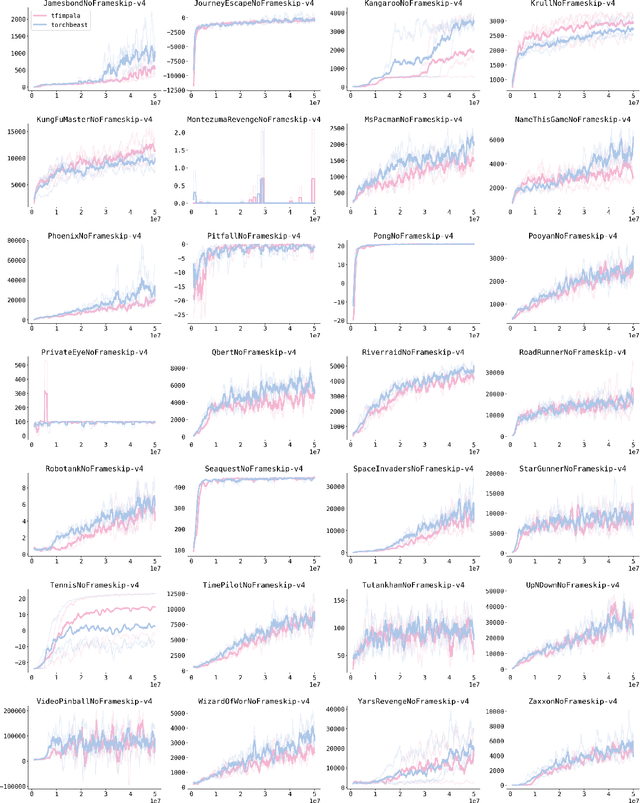
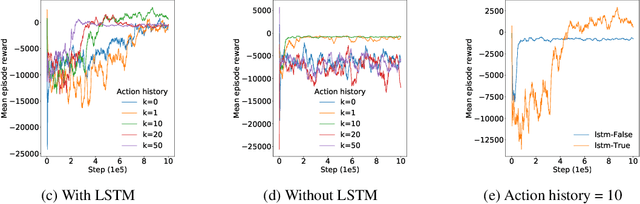
TorchBeast is a platform for reinforcement learning (RL) research in PyTorch. It implements a version of the popular IMPALA algorithm for fast, asynchronous, parallel training of RL agents. Additionally, TorchBeast has simplicity as an explicit design goal: We provide both a pure-Python implementation ("MonoBeast") as well as a multi-machine high-performance version ("PolyBeast"). In the latter, parts of the implementation are written in C++, but all parts pertaining to machine learning are kept in simple Python using PyTorch, with the environments provided using the OpenAI Gym interface. This enables researchers to conduct scalable RL research using TorchBeast without any programming knowledge beyond Python and PyTorch. In this paper, we describe the TorchBeast design principles and implementation and demonstrate that it performs on-par with IMPALA on Atari. TorchBeast is released as an open-source package under the Apache 2.0 license and is available at \url{https://github.com/facebookresearch/torchbeast}.
Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations and Hardware Implications
Nov 29, 2018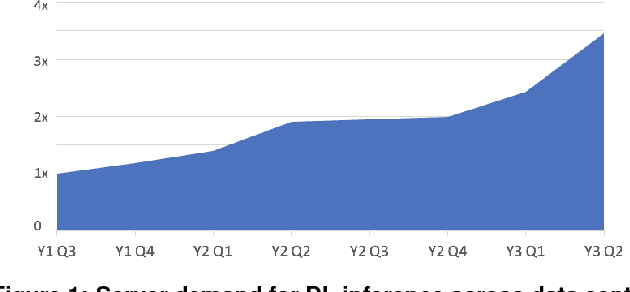
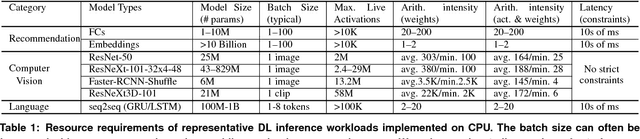
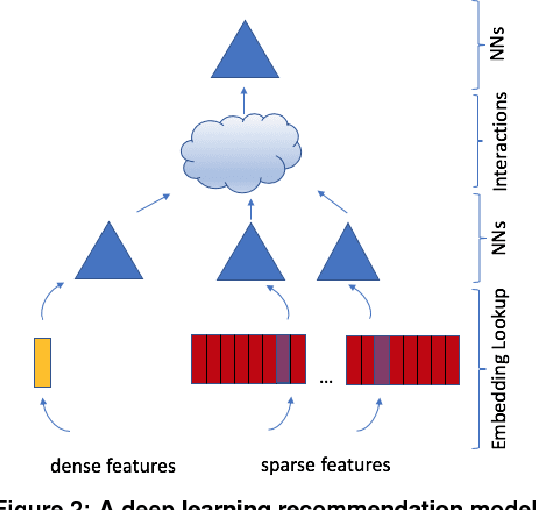
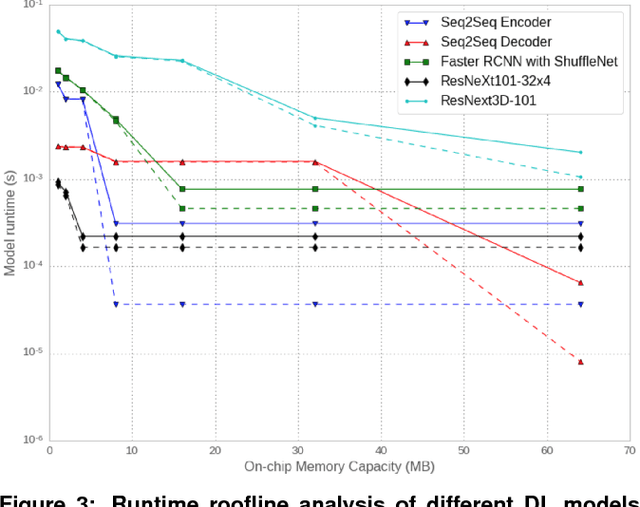
The application of deep learning techniques resulted in remarkable improvement of machine learning models. In this paper provides detailed characterizations of deep learning models used in many Facebook social network services. We present computational characteristics of our models, describe high performance optimizations targeting existing systems, point out their limitations and make suggestions for the future general-purpose/accelerated inference hardware. Also, we highlight the need for better co-design of algorithms, numerics and computing platforms to address the challenges of workloads often run in data centers.
Improving Rotated Text Detection with Rotation Region Proposal Networks
Nov 16, 2018

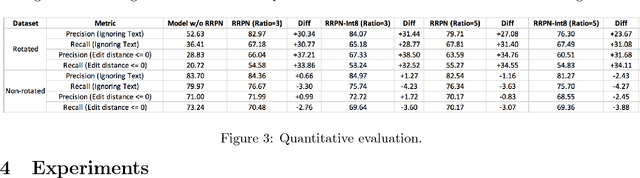
A significant number of images shared on social media platforms such as Facebook and Instagram contain text in various forms. It's increasingly becoming commonplace for bad actors to share misinformation, hate speech or other kinds of harmful content as text overlaid on images on such platforms. A scene-text understanding system should hence be able to handle text in various orientations that the adversary might use. Moreover, such a system can be incorporated into screen readers used to aid the visually impaired. In this work, we extend the scene-text extraction system at Facebook, Rosetta, to efficiently handle text in various orientations. Specifically, we incorporate the Rotation Region Proposal Networks (RRPN) in our text extraction pipeline and offer practical suggestions for building and deploying a model for detecting and recognizing text in arbitrary orientations efficiently. Experimental results show a significant improvement on detecting rotated text.