 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeemg2qwerty: A Large Dataset with Baselines for Touch Typing using Surface Electromyography
Oct 26, 2024



Surface electromyography (sEMG) non-invasively measures signals generated by muscle activity with sufficient sensitivity to detect individual spinal neurons and richness to identify dozens of gestures and their nuances. Wearable wrist-based sEMG sensors have the potential to offer low friction, subtle, information rich, always available human-computer inputs. To this end, we introduce emg2qwerty, a large-scale dataset of non-invasive electromyographic signals recorded at the wrists while touch typing on a QWERTY keyboard, together with ground-truth annotations and reproducible baselines. With 1,135 sessions spanning 108 users and 346 hours of recording, this is the largest such public dataset to date. These data demonstrate non-trivial, but well defined hierarchical relationships both in terms of the generative process, from neurons to muscles and muscle combinations, as well as in terms of domain shift across users and user sessions. Applying standard modeling techniques from the closely related field of Automatic Speech Recognition (ASR), we show strong baseline performance on predicting key-presses using sEMG signals alone. We believe the richness of this task and dataset will facilitate progress in several problems of interest to both the machine learning and neuroscientific communities. Dataset and code can be accessed at https://github.com/facebookresearch/emg2qwerty.
Latent Collaborative Retrieval
Jun 18, 2012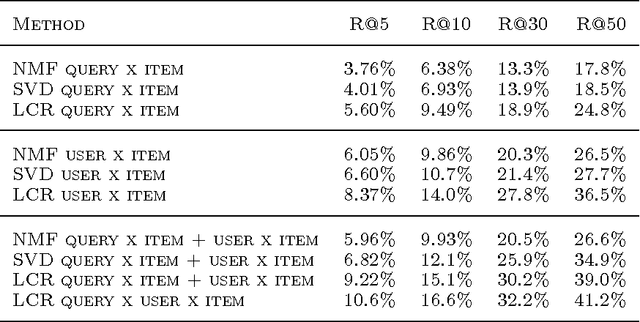

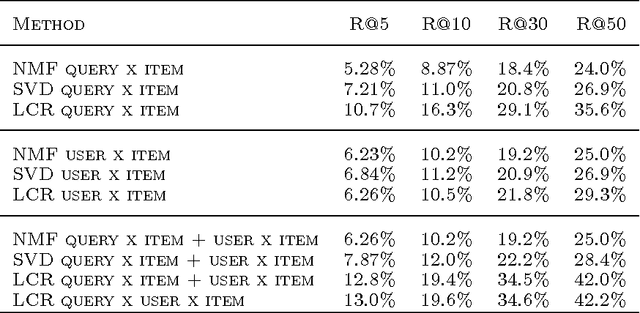
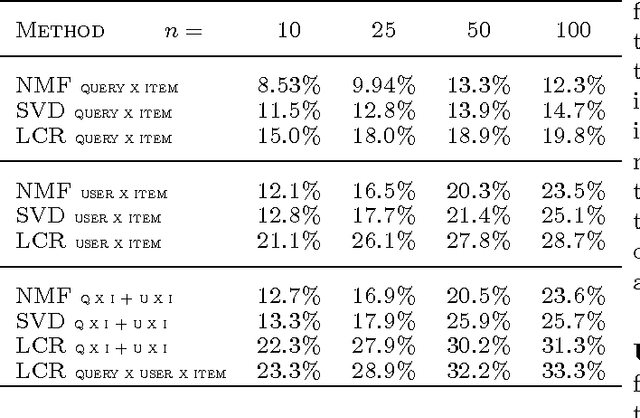
Retrieval tasks typically require a ranking of items given a query. Collaborative filtering tasks, on the other hand, learn to model user's preferences over items. In this paper we study the joint problem of recommending items to a user with respect to a given query, which is a surprisingly common task. This setup differs from the standard collaborative filtering one in that we are given a query x user x item tensor for training instead of the more traditional user x item matrix. Compared to document retrieval we do have a query, but we may or may not have content features (we will consider both cases) and we can also take account of the user's profile. We introduce a factorized model for this new task that optimizes the top-ranked items returned for the given query and user. We report empirical results where it outperforms several baselines.