 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeemg2qwerty: A Large Dataset with Baselines for Touch Typing using Surface Electromyography
Oct 26, 2024



Surface electromyography (sEMG) non-invasively measures signals generated by muscle activity with sufficient sensitivity to detect individual spinal neurons and richness to identify dozens of gestures and their nuances. Wearable wrist-based sEMG sensors have the potential to offer low friction, subtle, information rich, always available human-computer inputs. To this end, we introduce emg2qwerty, a large-scale dataset of non-invasive electromyographic signals recorded at the wrists while touch typing on a QWERTY keyboard, together with ground-truth annotations and reproducible baselines. With 1,135 sessions spanning 108 users and 346 hours of recording, this is the largest such public dataset to date. These data demonstrate non-trivial, but well defined hierarchical relationships both in terms of the generative process, from neurons to muscles and muscle combinations, as well as in terms of domain shift across users and user sessions. Applying standard modeling techniques from the closely related field of Automatic Speech Recognition (ASR), we show strong baseline performance on predicting key-presses using sEMG signals alone. We believe the richness of this task and dataset will facilitate progress in several problems of interest to both the machine learning and neuroscientific communities. Dataset and code can be accessed at https://github.com/facebookresearch/emg2qwerty.
ImportantAug: a data augmentation agent for speech
Dec 14, 2021



We introduce ImportantAug, a technique to augment training data for speech classification and recognition models by adding noise to unimportant regions of the speech and not to important regions. Importance is predicted for each utterance by a data augmentation agent that is trained to maximize the amount of noise it adds while minimizing its impact on recognition performance. The effectiveness of our method is illustrated on version two of the Google Speech Commands (GSC) dataset. On the standard GSC test set, it achieves a 23.3% relative error rate reduction compared to conventional noise augmentation which applies noise to speech without regard to where it might be most effective. It also provides a 25.4% error rate reduction compared to a baseline without data augmentation. Additionally, the proposed ImportantAug outperforms the conventional noise augmentation and the baseline on two test sets with additional noise added.
Large scale evaluation of importance maps in automatic speech recognition
May 21, 2020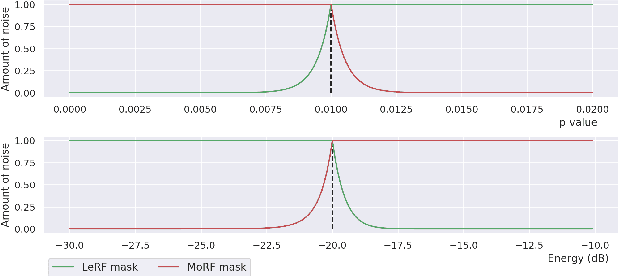


In this paper, we propose a metric that we call the structured saliency benchmark (SSBM) to evaluate importance maps computed for automatic speech recognizers on individual utterances. These maps indicate time-frequency points of the utterance that are most important for correct recognition of a target word. Our evaluation technique is not only suitable for standard classification tasks, but is also appropriate for structured prediction tasks like sequence-to-sequence models. Additionally, we use this approach to perform a large scale comparison of the importance maps created by our previously introduced technique using "bubble noise" to identify important points through correlation with a baseline approach based on smoothed speech energy and forced alignment. Our results show that the bubble analysis approach is better at identifying important speech regions than this baseline on 100 sentences from the AMI corpus.
Speaker independence of neural vocoders and their effect on parametric resynthesis speech enhancement
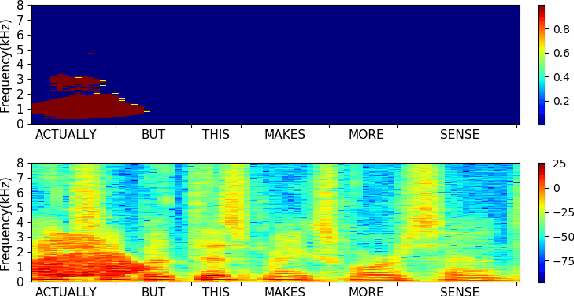
Nov 14, 2019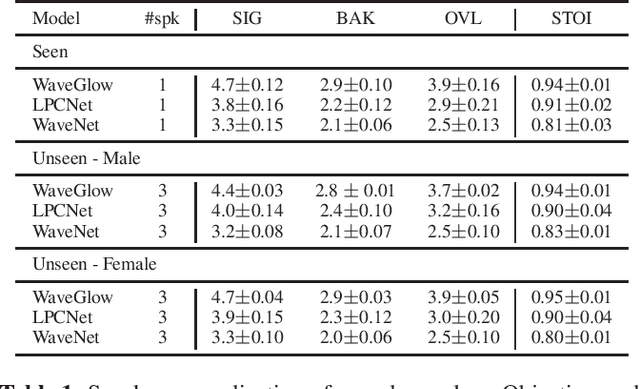

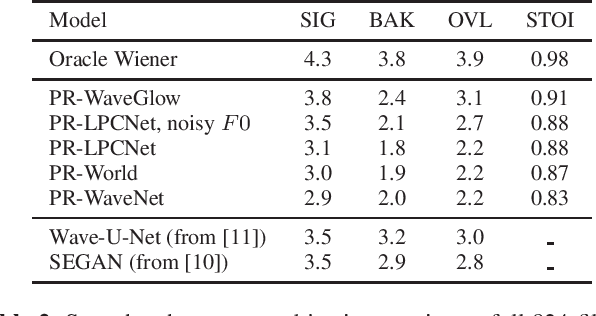

Traditional speech enhancement systems produce speech with compromised quality. Here we propose to use the high quality speech generation capability of neural vocoders for better quality speech enhancement. We term this parametric resynthesis (PR). In previous work, we showed that PR systems generate high quality speech for a single speaker using two neural vocoders, WaveNet and WaveGlow. Both these vocoders are traditionally speaker dependent. Here we first show that when trained on data from enough speakers, these vocoders can generate speech from unseen speakers, both male and female, with similar quality as seen speakers in training. Next using these two vocoders and a new vocoder LPCNet, we evaluate the noise reduction quality of PR on unseen speakers and show that objective signal and overall quality is higher than the state-of-the-art speech enhancement systems Wave-U-Net, Wavenet-denoise, and SEGAN. Moreover, in subjective quality, multiple-speaker PR out-performs the oracle Wiener mask.
Parametric Resynthesis with neural vocoders
Jun 16, 2019
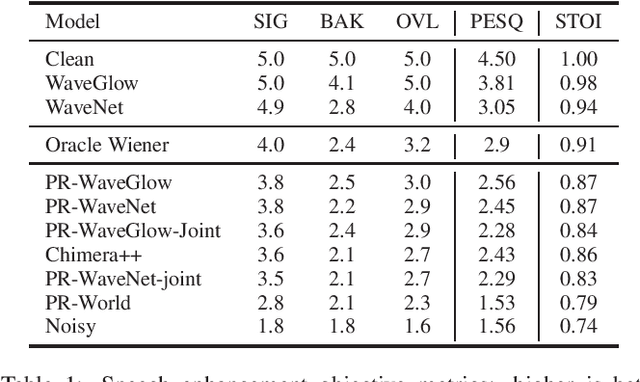
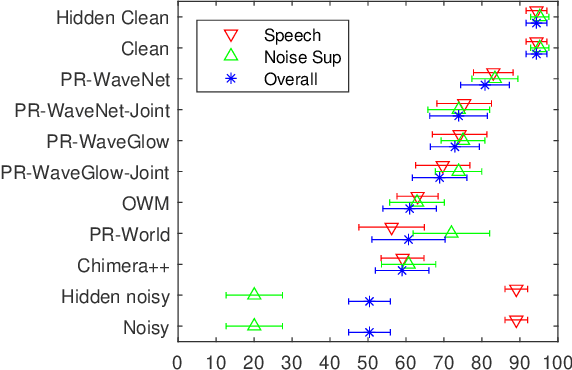
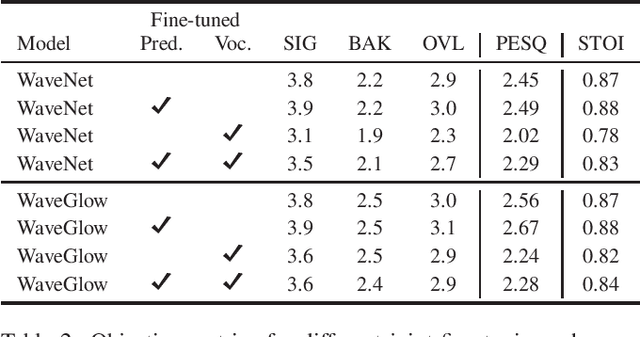
Noise suppression systems generally produce output speech with copromised quality. We propose to utilize the high quality speech generation capability of neural vocoders for noise suppression. We use a neural network to predict clean mel-spectrogram features from noisy speech and then compare two neural vocoders, WaveNet and WaveGlow, for synthesizing clean speech from the predicted mel spectrogram. Both WaveNet and WaveGlow achieve better subjective and objective quality scores than the source separation model Chimera++. Further, WaveNet and WaveGlow also achieve significantly better subjective quality ratings than the oracle Wiener mask. Moreover, we observe that between WaveNet and WaveGlow, WaveNet achieves the best subjective quality scores, although at the cost of much slower waveform generation.
Speech denoising by parametric resynthesis
Apr 02, 2019
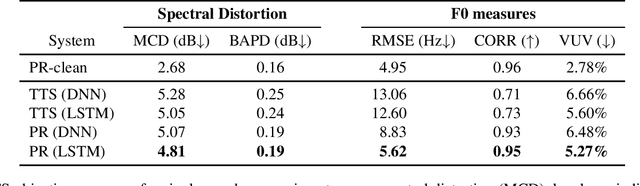
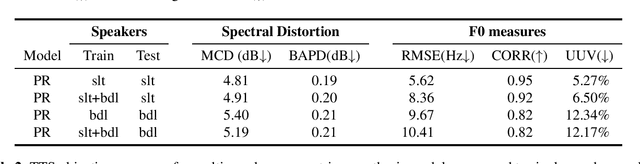

This work proposes the use of clean speech vocoder parameters as the target for a neural network performing speech enhancement. These parameters have been designed for text-to-speech synthesis so that they both produce high-quality resyntheses and also are straightforward to model with neural networks, but have not been utilized in speech enhancement until now. In comparison to a matched text-to-speech system that is given the ground truth transcripts of the noisy speech, our model is able to produce more natural speech because it has access to the true prosody in the noisy speech. In comparison to two denoising systems, the oracle Wiener mask and a DNN-based mask predictor, our model equals the oracle Wiener mask in subjective quality and intelligibility and surpasses the realistic system. A vocoder-based upper bound shows that there is still room for improvement with this approach beyond the oracle Wiener mask. We test speaker-dependence with two speakers and show that a single model can be used for multiple speakers.