 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Reliability in Large-Scale Machine Learning Research Clusters
Oct 29, 2024



Reliability is a fundamental challenge in operating large-scale machine learning (ML) infrastructures, particularly as the scale of ML models and training clusters continues to grow. Despite decades of research on infrastructure failures, the impact of job failures across different scales remains unclear. This paper presents a view of managing two large, multi-tenant ML clusters, providing quantitative analysis, operational experience, and our own perspective in understanding and addressing reliability concerns at scale. Our analysis reveals that while large jobs are most vulnerable to failures, smaller jobs make up the majority of jobs in the clusters and should be incorporated into optimization objectives. We identify key workload properties, compare them across clusters, and demonstrate essential reliability requirements for pushing the boundaries of ML training at scale. We hereby introduce a taxonomy of failures and key reliability metrics, analyze 11 months of data from two state-of-the-art ML environments with over 150 million A100 GPU hours and 4 million jobs. Building on our data, we fit a failure model to project Mean Time to Failure for various GPU scales. We further propose a method to estimate a related metric, Effective Training Time Ratio, as a function of job parameters, and we use this model to gauge the efficacy of potential software mitigations at scale. Our work provides valuable insights and future research directions for improving the reliability of AI supercomputer clusters, emphasizing the need for flexible, workload-agnostic, and reliability-aware infrastructure, system software, and algorithms.
Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations and Hardware Implications
Nov 29, 2018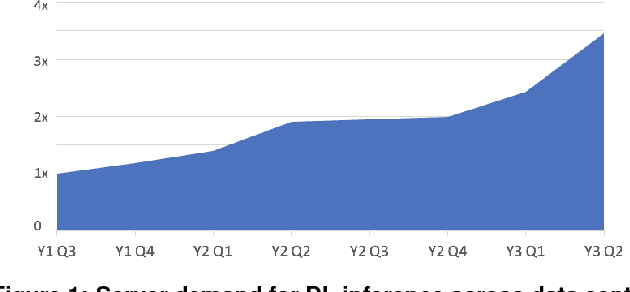
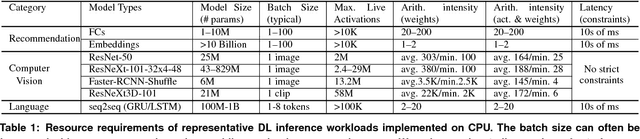
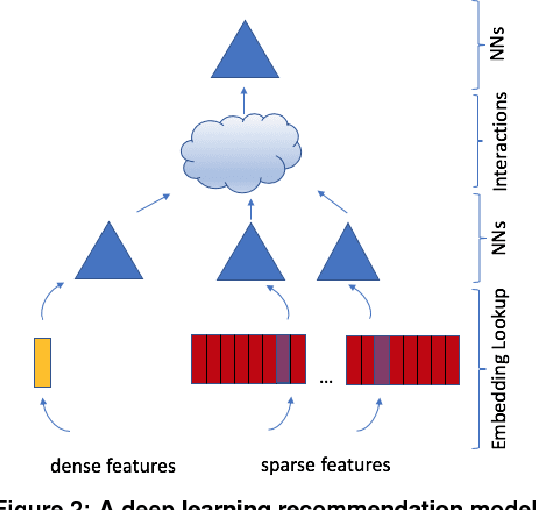
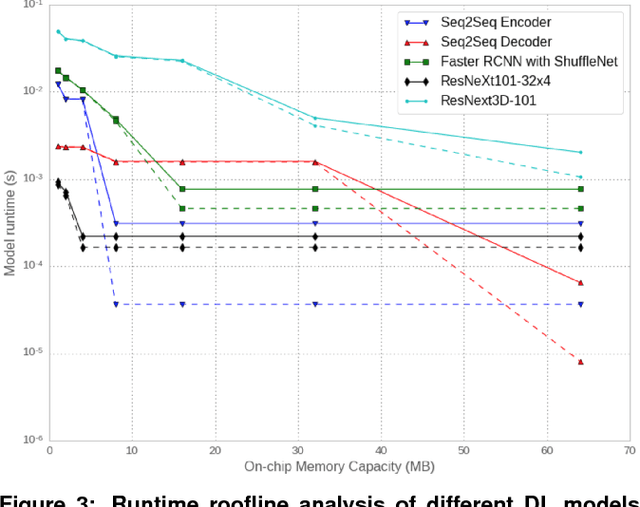
The application of deep learning techniques resulted in remarkable improvement of machine learning models. In this paper provides detailed characterizations of deep learning models used in many Facebook social network services. We present computational characteristics of our models, describe high performance optimizations targeting existing systems, point out their limitations and make suggestions for the future general-purpose/accelerated inference hardware. Also, we highlight the need for better co-design of algorithms, numerics and computing platforms to address the challenges of workloads often run in data centers.