 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Reliability in Large-Scale Machine Learning Research Clusters
Oct 29, 2024



Reliability is a fundamental challenge in operating large-scale machine learning (ML) infrastructures, particularly as the scale of ML models and training clusters continues to grow. Despite decades of research on infrastructure failures, the impact of job failures across different scales remains unclear. This paper presents a view of managing two large, multi-tenant ML clusters, providing quantitative analysis, operational experience, and our own perspective in understanding and addressing reliability concerns at scale. Our analysis reveals that while large jobs are most vulnerable to failures, smaller jobs make up the majority of jobs in the clusters and should be incorporated into optimization objectives. We identify key workload properties, compare them across clusters, and demonstrate essential reliability requirements for pushing the boundaries of ML training at scale. We hereby introduce a taxonomy of failures and key reliability metrics, analyze 11 months of data from two state-of-the-art ML environments with over 150 million A100 GPU hours and 4 million jobs. Building on our data, we fit a failure model to project Mean Time to Failure for various GPU scales. We further propose a method to estimate a related metric, Effective Training Time Ratio, as a function of job parameters, and we use this model to gauge the efficacy of potential software mitigations at scale. Our work provides valuable insights and future research directions for improving the reliability of AI supercomputer clusters, emphasizing the need for flexible, workload-agnostic, and reliability-aware infrastructure, system software, and algorithms.
Explainable machine learning to enable high-throughput electrical conductivity optimization of doped conjugated polymers
Aug 08, 2023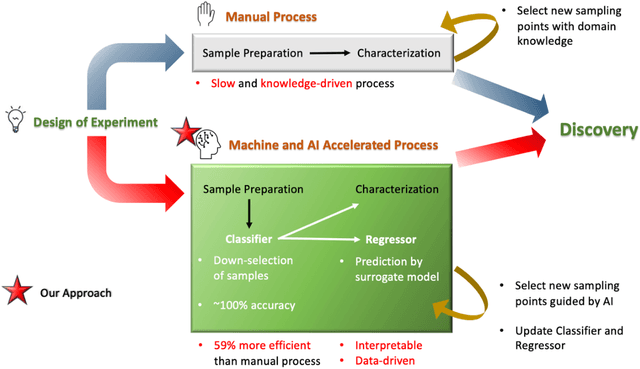



The combination of high-throughput experimentation techniques and machine learning (ML) has recently ushered in a new era of accelerated material discovery, enabling the identification of materials with cutting-edge properties. However, the measurement of certain physical quantities remains challenging to automate. Specifically, meticulous process control, experimentation and laborious measurements are required to achieve optimal electrical conductivity in doped polymer materials. We propose a ML approach, which relies on readily measured absorbance spectra, to accelerate the workflow associated with measuring electrical conductivity. The first ML model (classification model), accurately classifies samples with a conductivity >~25 to 100 S/cm, achieving a maximum of 100% accuracy rate. For the subset of highly conductive samples, we employed a second ML model (regression model), to predict their conductivities, yielding an impressive test R2 value of 0.984. To validate the approach, we showed that the models, neither trained on the samples with the two highest conductivities of 498 and 506 S/cm, were able to, in an extrapolative manner, correctly classify and predict them at satisfactory levels of errors. The proposed ML workflow results in an improvement in the efficiency of the conductivity measurements by 89% of the maximum achievable using our experimental techniques. Furthermore, our approach addressed the common challenge of the lack of explainability in ML models by exploiting bespoke mathematical properties of the descriptors and ML model, allowing us to gain corroborated insights into the spectral influences on conductivity. Through this study, we offer an accelerated pathway for optimizing the properties of doped polymer materials while showcasing the valuable insights that can be derived from purposeful utilization of ML in experimental science.