 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attention-Based Denoising Model for Diffusion Weighted Imaging
Jun 02, 2026Diffusion-weighted imaging (DWI) is used for whole-body cancer screening, but it typically requires a long acquisition time. When the scan time is reduced, the image quality often suffers, leading to increased noise in the scans. Magnitude reconstruction in DWI introduces signal-dependent Rician noise, which makes denoising more challenging for conventional convolution-based methods. To address this limitation, we propose a noise-aware attention-driven denoising framework that integrates hierarchical Swin Transformer window attention with transformer-based multi-dimensional gated refinement for DWI restoration. The model incorporates explicit noise-level conditioning and residual reconstruction to enable adaptive suppression of heteroscedastic noise across a wide range of corruption levels. Experimental evaluation on corrupted DWI scans demonstrates strong restoration performance. Our model achieves a mean PSNR of 33.69~dB and SSIM of 0.8539 across noise levels from 1\% to 15\%, while maintaining stable behavior under severe noise conditions. These results indicate that attention-guided contextual modeling combined with channel-adaptive refinement provides a robust and generalizable solution for DWI denoising.
Alignment and Safety of Diffusion Models via Reinforcement Learning and Reward Modeling: A Survey
May 23, 2025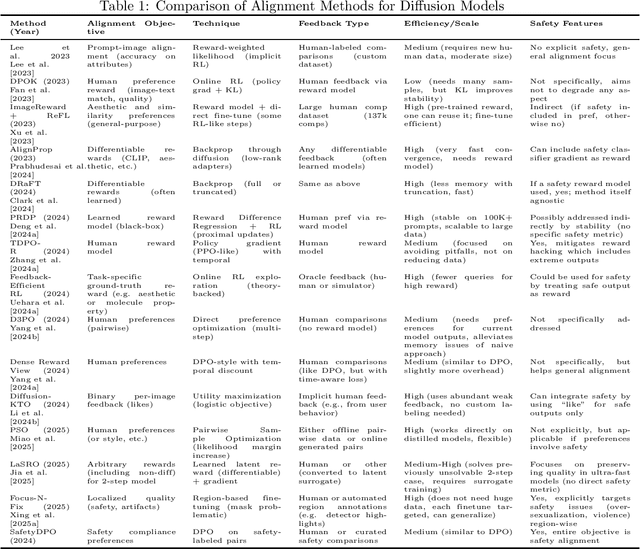
Diffusion models have emerged as leading generative models for images and other modalities, but aligning their outputs with human preferences and safety constraints remains a critical challenge. This thesis proposal investigates methods to align diffusion models using reinforcement learning (RL) and reward modeling. We survey recent advances in fine-tuning text-to-image diffusion models with human feedback, including reinforcement learning from human and AI feedback, direct preference optimization, and differentiable reward approaches. We classify these methods based on the type of feedback (human, automated, binary or ranked preferences), the fine-tuning technique (policy gradient, reward-weighted likelihood, direct backpropagation, etc.), and their efficiency and safety outcomes. We compare key algorithms and frameworks, highlighting how they improve alignment with user intent or safety standards, and discuss inter-relationships such as how newer methods build on or diverge from earlier ones. Based on the survey, we identify five promising research directions for the next two years: (1) multi-objective alignment with combined rewards, (2) efficient human feedback usage and active learning, (3) robust safety alignment against adversarial inputs, (4) continual and online alignment of diffusion models, and (5) interpretable and trustworthy reward modeling for generative images. Each direction is elaborated with its problem statement, challenges, related work, and a proposed research plan. The proposal is organized as a comprehensive document with literature review, comparative tables of methods, and detailed research plans, aiming to contribute new insights and techniques for safer and value-aligned diffusion-based generative AI.
A Survey of Safe Reinforcement Learning and Constrained MDPs: A Technical Survey on Single-Agent and Multi-Agent Safety
May 22, 2025Safe Reinforcement Learning (SafeRL) is the subfield of reinforcement learning that explicitly deals with safety constraints during the learning and deployment of agents. This survey provides a mathematically rigorous overview of SafeRL formulations based on Constrained Markov Decision Processes (CMDPs) and extensions to Multi-Agent Safe RL (SafeMARL). We review theoretical foundations of CMDPs, covering definitions, constrained optimization techniques, and fundamental theorems. We then summarize state-of-the-art algorithms in SafeRL for single agents, including policy gradient methods with safety guarantees and safe exploration strategies, as well as recent advances in SafeMARL for cooperative and competitive settings. Additionally, we propose five open research problems to advance the field, with three focusing on SafeMARL. Each problem is described with motivation, key challenges, and related prior work. This survey is intended as a technical guide for researchers interested in SafeRL and SafeMARL, highlighting key concepts, methods, and open future research directions.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Overlay Space-Air-Ground Integrated Networks with SWIPT-Empowered Aerial Communications
Jun 19, 2024



In this article, we consider overlay space-air-ground integrated networks (OSAGINs) where a low earth orbit (LEO) satellite communicates with ground users (GUs) with the assistance of an energy-constrained coexisting air-to-air (A2A) network. Particularly, a non-linear energy harvester with a hybrid SWIPT utilizing both power-splitting and time-switching energy harvesting (EH) techniques is employed at the aerial transmitter. Specifically, we take the random locations of the satellite, ground and aerial receivers to investigate the outage performance of both the satellite-to-ground and aerial networks leveraging the stochastic tools. By taking into account the Shadowed-Rician fading for satellite link, the Nakagami-\emph{m} for ground link, and the Rician fading for aerial link, we derive analytical expressions for the outage probability of these networks. For a comprehensive analysis of aerial network, we consider both the perfect and imperfect successive interference cancellation (SIC) scenarios. Through our analysis, we illustrate that, unlike linear EH, the implementation of non-linear EH provides accurate figures for any target rate, underscoring the significance of using non-linear EH models. Additionally, the influence of key parameters is emphasized, providing guidelines for the practical design of an energy-efficient as well as spectrum-efficient future non-terrestrial networks. Monte Carlo simulations validate the accuracy of our theoretical developments.
A Gauss-Newton Approach for Min-Max Optimization in Generative Adversarial Networks
Apr 10, 2024A novel first-order method is proposed for training generative adversarial networks (GANs). It modifies the Gauss-Newton method to approximate the min-max Hessian and uses the Sherman-Morrison inversion formula to calculate the inverse. The method corresponds to a fixed-point method that ensures necessary contraction. To evaluate its effectiveness, numerical experiments are conducted on various datasets commonly used in image generation tasks, such as MNIST, Fashion MNIST, CIFAR10, FFHQ, and LSUN. Our method is capable of generating high-fidelity images with greater diversity across multiple datasets. It also achieves the highest inception score for CIFAR10 among all compared methods, including state-of-the-art second-order methods. Additionally, its execution time is comparable to that of first-order min-max methods.
Alpha Elimination: Using Deep Reinforcement Learning to Reduce Fill-In during Sparse Matrix Decomposition
Oct 15, 2023A large number of computational and scientific methods commonly require decomposing a sparse matrix into triangular factors as LU decomposition. A common problem faced during this decomposition is that even though the given matrix may be very sparse, the decomposition may lead to a denser triangular factors due to fill-in. A significant fill-in may lead to prohibitively larger computational costs and memory requirement during decomposition as well as during the solve phase. To this end, several heuristic sparse matrix reordering methods have been proposed to reduce fill-in before the decomposition. However, finding an optimal reordering algorithm that leads to minimal fill-in during such decomposition is known to be a NP-hard problem. A reinforcement learning based approach is proposed for this problem. The sparse matrix reordering problem is formulated as a single player game. More specifically, Monte-Carlo tree search in combination with neural network is used as a decision making algorithm to search for the best move in our game. The proposed method, alphaElimination is found to produce significantly lesser non-zeros in the LU decomposition as compared to existing state-of-the-art heuristic algorithms with little to no increase in overall running time of the algorithm. The code for the project will be publicly available here\footnote{\url{https://github.com/misterpawan/alphaEliminationPaper}}.
Enhancing ML model accuracy for Digital VLSI circuits using diffusion models: A study on synthetic data generation
Oct 15, 2023



Generative AI has seen remarkable growth over the past few years, with diffusion models being state-of-the-art for image generation. This study investigates the use of diffusion models in generating artificial data generation for electronic circuits for enhancing the accuracy of subsequent machine learning models in tasks such as performance assessment, design, and testing when training data is usually known to be very limited. We utilize simulations in the HSPICE design environment with 22nm CMOS technology nodes to obtain representative real training data for our proposed diffusion model. Our results demonstrate the close resemblance of synthetic data using diffusion model to real data. We validate the quality of generated data, and demonstrate that data augmentation certainly effective in predictive analysis of VLSI design for digital circuits.
Reinforcement Learning Based Sensor Optimization for Bio-markers
Aug 21, 2023Radio frequency (RF) biosensors, in particular those based on inter-digitated capacitors (IDCs), are pivotal in areas like biomedical diagnosis, remote sensing, and wireless communication. Despite their advantages of low cost and easy fabrication, their sensitivity can be hindered by design imperfections, environmental factors, and circuit noise. This paper investigates enhancing the sensitivity of IDC-based RF sensors using novel reinforcement learning based Binary Particle Swarm Optimization (RLBPSO), and it is compared to Ant Colony Optimization (ACO), and other state-of-the-art methods. By focusing on optimizing design parameters like electrode design and finger width, the proposed study found notable improvements in sensor sensitivity. The proposed RLBPSO method shows best optimized design for various frequency ranges when compared to current state-of-the-art methods.
Explainable machine learning to enable high-throughput electrical conductivity optimization of doped conjugated polymers
Aug 08, 2023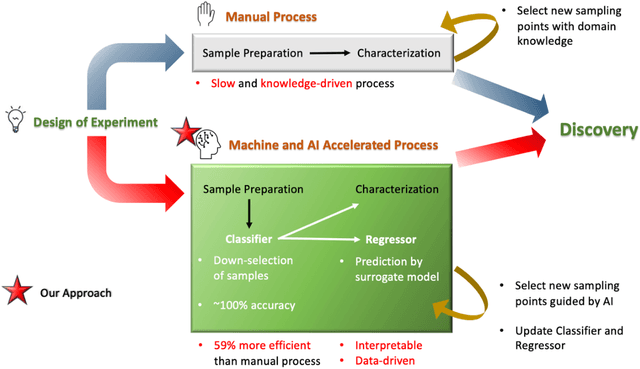



The combination of high-throughput experimentation techniques and machine learning (ML) has recently ushered in a new era of accelerated material discovery, enabling the identification of materials with cutting-edge properties. However, the measurement of certain physical quantities remains challenging to automate. Specifically, meticulous process control, experimentation and laborious measurements are required to achieve optimal electrical conductivity in doped polymer materials. We propose a ML approach, which relies on readily measured absorbance spectra, to accelerate the workflow associated with measuring electrical conductivity. The first ML model (classification model), accurately classifies samples with a conductivity >~25 to 100 S/cm, achieving a maximum of 100% accuracy rate. For the subset of highly conductive samples, we employed a second ML model (regression model), to predict their conductivities, yielding an impressive test R2 value of 0.984. To validate the approach, we showed that the models, neither trained on the samples with the two highest conductivities of 498 and 506 S/cm, were able to, in an extrapolative manner, correctly classify and predict them at satisfactory levels of errors. The proposed ML workflow results in an improvement in the efficiency of the conductivity measurements by 89% of the maximum achievable using our experimental techniques. Furthermore, our approach addressed the common challenge of the lack of explainability in ML models by exploiting bespoke mathematical properties of the descriptors and ML model, allowing us to gain corroborated insights into the spectral influences on conductivity. Through this study, we offer an accelerated pathway for optimizing the properties of doped polymer materials while showcasing the valuable insights that can be derived from purposeful utilization of ML in experimental science.