 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarden and Catch for Just-in-Time Assured LLM-Based Software Testing: Open Research Challenges
Apr 23, 2025



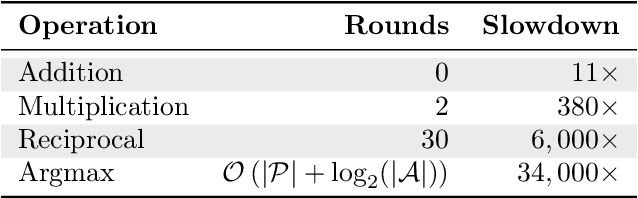
Despite decades of research and practice in automated software testing, several fundamental concepts remain ill-defined and under-explored, yet offer enormous potential real-world impact. We show that these concepts raise exciting new challenges in the context of Large Language Models for software test generation. More specifically, we formally define and investigate the properties of hardening and catching tests. A hardening test is one that seeks to protect against future regressions, while a catching test is one that catches such a regression or a fault in new functionality introduced by a code change. Hardening tests can be generated at any time and may become catching tests when a future regression is caught. We also define and motivate the Catching `Just-in-Time' (JiTTest) Challenge, in which tests are generated `just-in-time' to catch new faults before they land into production. We show that any solution to Catching JiTTest generation can also be repurposed to catch latent faults in legacy code. We enumerate possible outcomes for hardening and catching tests and JiTTests, and discuss open research problems, deployment options, and initial results from our work on automated LLM-based hardening at Meta. This paper\footnote{Author order is alphabetical. The corresponding author is Mark Harman.} was written to accompany the keynote by the authors at the ACM International Conference on the Foundations of Software Engineering (FSE) 2025.
Revisiting Reliability in Large-Scale Machine Learning Research Clusters
Oct 29, 2024



Reliability is a fundamental challenge in operating large-scale machine learning (ML) infrastructures, particularly as the scale of ML models and training clusters continues to grow. Despite decades of research on infrastructure failures, the impact of job failures across different scales remains unclear. This paper presents a view of managing two large, multi-tenant ML clusters, providing quantitative analysis, operational experience, and our own perspective in understanding and addressing reliability concerns at scale. Our analysis reveals that while large jobs are most vulnerable to failures, smaller jobs make up the majority of jobs in the clusters and should be incorporated into optimization objectives. We identify key workload properties, compare them across clusters, and demonstrate essential reliability requirements for pushing the boundaries of ML training at scale. We hereby introduce a taxonomy of failures and key reliability metrics, analyze 11 months of data from two state-of-the-art ML environments with over 150 million A100 GPU hours and 4 million jobs. Building on our data, we fit a failure model to project Mean Time to Failure for various GPU scales. We further propose a method to estimate a related metric, Effective Training Time Ratio, as a function of job parameters, and we use this model to gauge the efficacy of potential software mitigations at scale. Our work provides valuable insights and future research directions for improving the reliability of AI supercomputer clusters, emphasizing the need for flexible, workload-agnostic, and reliability-aware infrastructure, system software, and algorithms.
Parallel Composition of Weighted Finite-State Transducers
Oct 06, 2021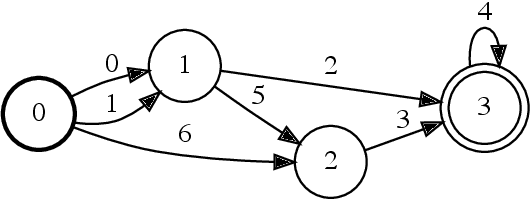


Finite-state transducers (FSTs) are frequently used in speech recognition. Transducer composition is an essential operation for combining different sources of information at different granularities. However, composition is also one of the more computationally expensive operations. Due to the heterogeneous structure of FSTs, parallel algorithms for composition are suboptimal in efficiency, generality, or both. We propose an algorithm for parallel composition and implement it on graphics processing units. We benchmark our parallel algorithm on the composition of random graphs and the composition of graphs commonly used in speech recognition. The parallel composition scales better with the size of the input graphs and for large graphs can be as much as 10 to 30 times faster than a sequential CPU algorithm.
CrypTen: Secure Multi-Party Computation Meets Machine Learning
Sep 02, 2021Secure multi-party computation (MPC) allows parties to perform computations on data while keeping that data private. This capability has great potential for machine-learning applications: it facilitates training of machine-learning models on private data sets owned by different parties, evaluation of one party's private model using another party's private data, etc. Although a range of studies implement machine-learning models via secure MPC, such implementations are not yet mainstream. Adoption of secure MPC is hampered by the absence of flexible software frameworks that "speak the language" of machine-learning researchers and engineers. To foster adoption of secure MPC in machine learning, we present CrypTen: a software framework that exposes popular secure MPC primitives via abstractions that are common in modern machine-learning frameworks, such as tensor computations, automatic differentiation, and modular neural networks. This paper describes the design of CrypTen and measure its performance on state-of-the-art models for text classification, speech recognition, and image classification. Our benchmarks show that CrypTen's GPU support and high-performance communication between (an arbitrary number of) parties allows it to perform efficient private evaluation of modern machine-learning models under a semi-honest threat model. For example, two parties using CrypTen can securely predict phonemes in speech recordings using Wav2Letter faster than real-time. We hope that CrypTen will spur adoption of secure MPC in the machine-learning community.
Privacy-Preserving Contextual Bandits
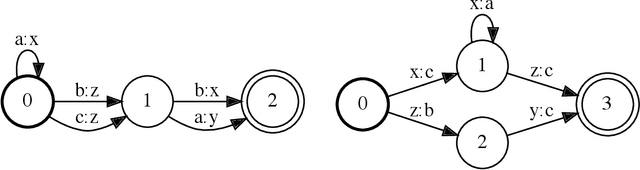
Oct 14, 2019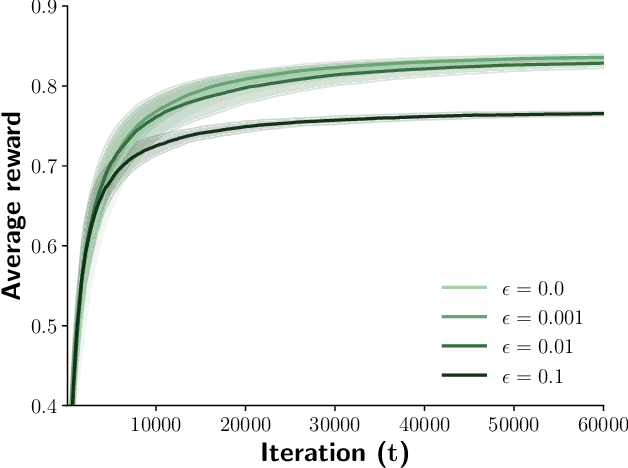
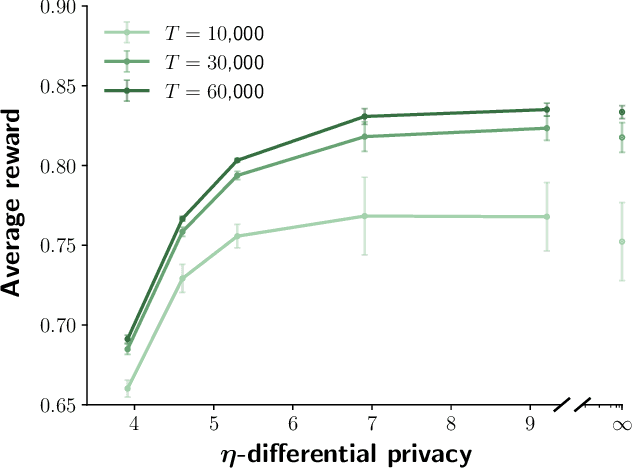
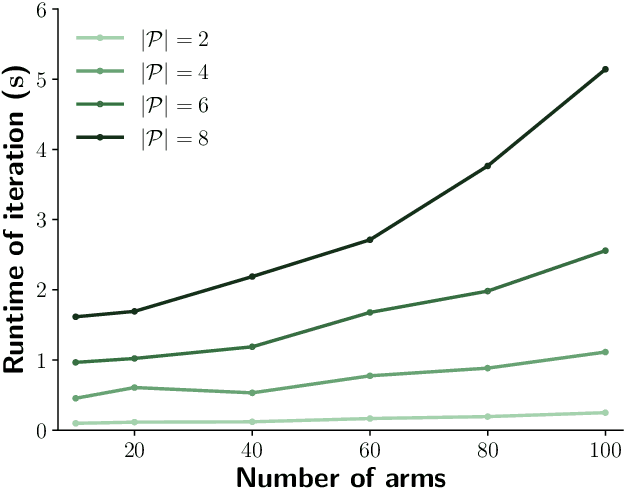
Contextual bandits are online learners that, given an input, select an arm and receive a reward for that arm. They use the reward as a learning signal and aim to maximize the total reward over the inputs. Contextual bandits are commonly used to solve recommendation or ranking problems. This paper considers a learning setting in which multiple parties aim to train a contextual bandit together in a private way: the parties aim to maximize the total reward but do not want to share any of the relevant information they possess with the other parties. Specifically, multiple parties have access to (different) features that may benefit the learner but that cannot be shared with other parties. One of the parties pulls the arm but other parties may not learn which arm was pulled. One party receives the reward but the other parties may not learn the reward value. This paper develops a privacy-preserving contextual bandit algorithm that combines secure multi-party computation with a differential private mechanism based on epsilon-greedy exploration in contextual bandits.
ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero
Feb 13, 2019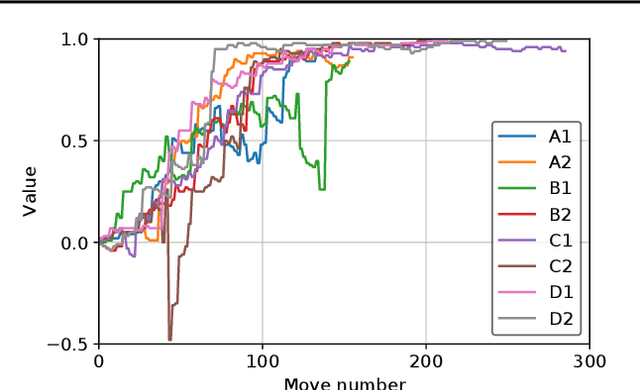

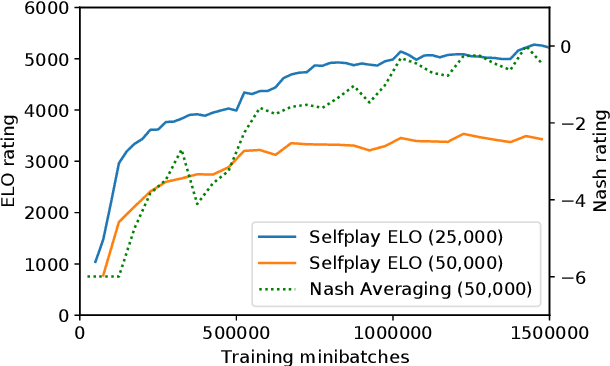
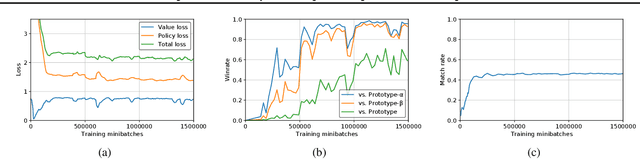
The AlphaGo, AlphaGo Zero, and AlphaZero series of algorithms are a remarkable demonstration of deep reinforcement learning's capabilities, achieving superhuman performance in the complex game of Go with progressively increasing autonomy. However, many obstacles remain in the understanding of and usability of these promising approaches by the research community. Toward elucidating unresolved mysteries and facilitating future research, we propose ELF OpenGo, an open-source reimplementation of the AlphaZero algorithm. ELF OpenGo is the first open-source Go AI to convincingly demonstrate superhuman performance with a perfect (20:0) record against global top professionals. We apply ELF OpenGo to conduct extensive ablation studies, and to identify and analyze numerous interesting phenomena in both the model training and in the gameplay inference procedures. Our code, models, selfplay datasets, and auxiliary data are publicly available.
Exploring Sparsity in Recurrent Neural Networks
Nov 06, 2017
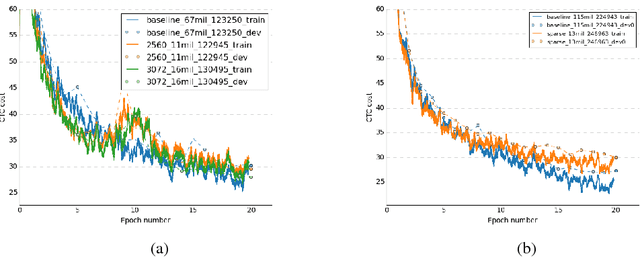

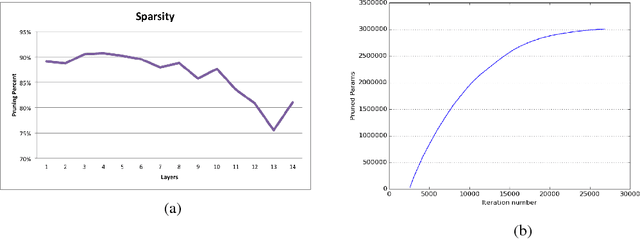
Recurrent Neural Networks (RNN) are widely used to solve a variety of problems and as the quantity of data and the amount of available compute have increased, so have model sizes. The number of parameters in recent state-of-the-art networks makes them hard to deploy, especially on mobile phones and embedded devices. The challenge is due to both the size of the model and the time it takes to evaluate it. In order to deploy these RNNs efficiently, we propose a technique to reduce the parameters of a network by pruning weights during the initial training of the network. At the end of training, the parameters of the network are sparse while accuracy is still close to the original dense neural network. The network size is reduced by 8x and the time required to train the model remains constant. Additionally, we can prune a larger dense network to achieve better than baseline performance while still reducing the total number of parameters significantly. Pruning RNNs reduces the size of the model and can also help achieve significant inference time speed-up using sparse matrix multiply. Benchmarks show that using our technique model size can be reduced by 90% and speed-up is around 2x to 7x.
Deep Voice: Real-time Neural Text-to-Speech
Mar 07, 2017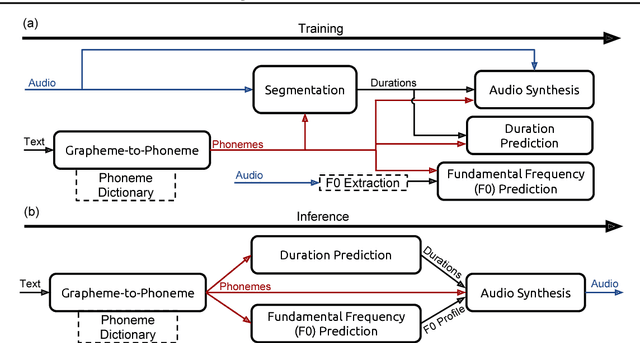
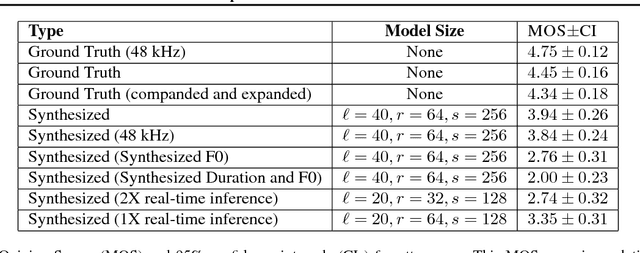
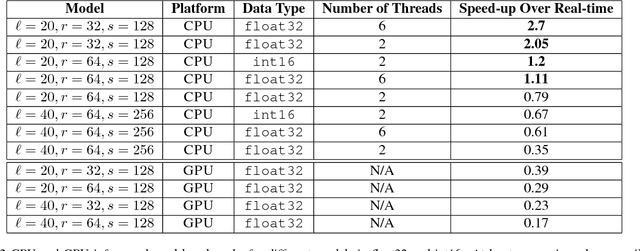
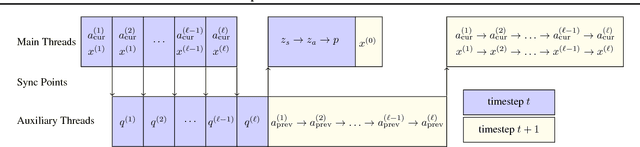
We present Deep Voice, a production-quality text-to-speech system constructed entirely from deep neural networks. Deep Voice lays the groundwork for truly end-to-end neural speech synthesis. The system comprises five major building blocks: a segmentation model for locating phoneme boundaries, a grapheme-to-phoneme conversion model, a phoneme duration prediction model, a fundamental frequency prediction model, and an audio synthesis model. For the segmentation model, we propose a novel way of performing phoneme boundary detection with deep neural networks using connectionist temporal classification (CTC) loss. For the audio synthesis model, we implement a variant of WaveNet that requires fewer parameters and trains faster than the original. By using a neural network for each component, our system is simpler and more flexible than traditional text-to-speech systems, where each component requires laborious feature engineering and extensive domain expertise. Finally, we show that inference with our system can be performed faster than real time and describe optimized WaveNet inference kernels on both CPU and GPU that achieve up to 400x speedups over existing implementations.
Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
Dec 08, 2015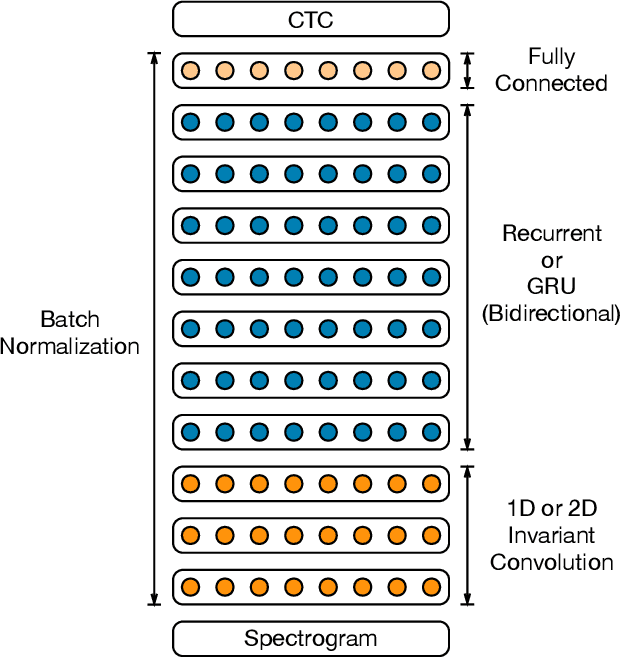
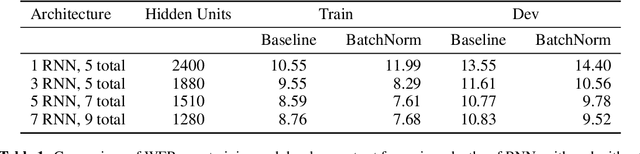
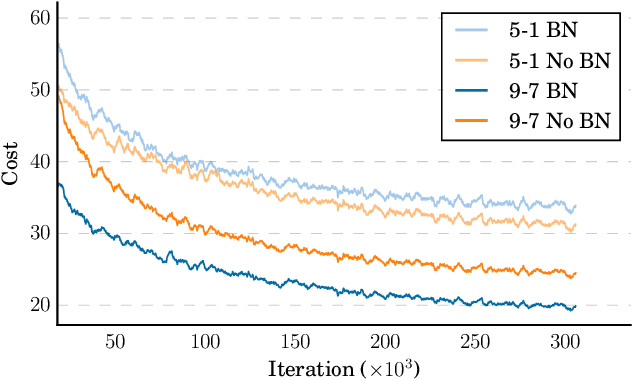
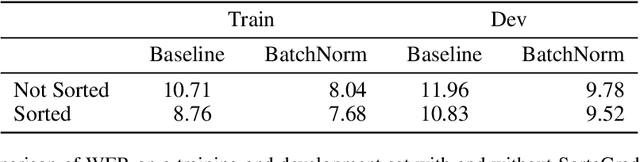
We show that an end-to-end deep learning approach can be used to recognize either English or Mandarin Chinese speech--two vastly different languages. Because it replaces entire pipelines of hand-engineered components with neural networks, end-to-end learning allows us to handle a diverse variety of speech including noisy environments, accents and different languages. Key to our approach is our application of HPC techniques, resulting in a 7x speedup over our previous system. Because of this efficiency, experiments that previously took weeks now run in days. This enables us to iterate more quickly to identify superior architectures and algorithms. As a result, in several cases, our system is competitive with the transcription of human workers when benchmarked on standard datasets. Finally, using a technique called Batch Dispatch with GPUs in the data center, we show that our system can be inexpensively deployed in an online setting, delivering low latency when serving users at scale.
Deep Speech: Scaling up end-to-end speech recognition
Dec 19, 2014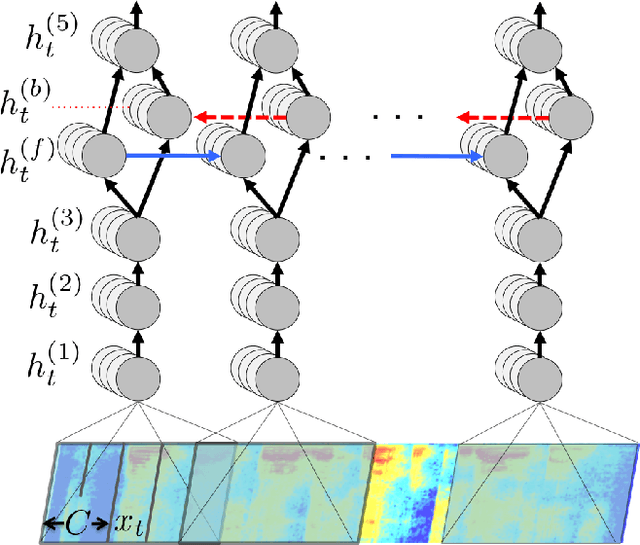

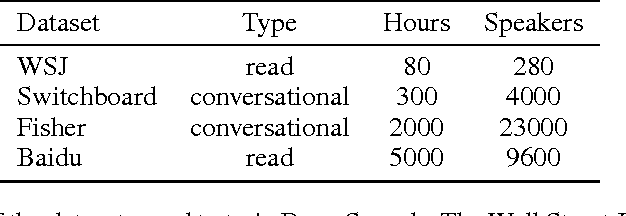

We present a state-of-the-art speech recognition system developed using end-to-end deep learning. Our architecture is significantly simpler than traditional speech systems, which rely on laboriously engineered processing pipelines; these traditional systems also tend to perform poorly when used in noisy environments. In contrast, our system does not need hand-designed components to model background noise, reverberation, or speaker variation, but instead directly learns a function that is robust to such effects. We do not need a phoneme dictionary, nor even the concept of a "phoneme." Key to our approach is a well-optimized RNN training system that uses multiple GPUs, as well as a set of novel data synthesis techniques that allow us to efficiently obtain a large amount of varied data for training. Our system, called Deep Speech, outperforms previously published results on the widely studied Switchboard Hub5'00, achieving 16.0% error on the full test set. Deep Speech also handles challenging noisy environments better than widely used, state-of-the-art commercial speech systems.