 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow AI Agents Reshape Knowledge Work: Autonomy, Efficiency, and Scope
Jun 05, 2026Frontier AI systems are bridging the gap between intelligence and utility by shifting from conversational assistants to autonomous agents that execute tasks end to end. Using production data from Perplexity's Search and Computer products, we study this transition by examining how AI agents accelerate and reshape knowledge work. Three key empirical findings emerge. First, using sessions with near-identical initial query pairs as natural experiments for the same underlying task attempted with both products, Computer performs 26 minutes of autonomous work per user session, versus 33 seconds for Search. Computer automates task decomposition and execution that Search users might otherwise manually orchestrate and implement. As a result, Computer shifts follow-up query distribution toward higher-order work such as verification and extension. Autonomy also increases execution quality, with per-query dissatisfaction rates 55% lower on Computer than on Search. Second, due to its autonomy advantage, Computer reduces completion time from 269 to 36 minutes on matched tasks, lowering estimated time and cost by 87% and 94%, respectively, compared to humans equipped with Search alone. Third, Computer changes the scope of work that users attempt: Computer queries more often cross occupational boundaries, require higher-order cognition, draw on broader expertise, take the form of composite tasks that bundle interdependent subtasks into a single query, and unlock work activities that are essentially absent from Search usage among the same users. Together, the evidence indicates that AI agents accelerate workflows, enhance output quality, reduce costs, and expand the breadth and depth of automated work.
Security Considerations for Artificial Intelligence Agents
Mar 12, 2026This article, a lightly adapted version of Perplexity's response to NIST/CAISI Request for Information 2025-0035, details our observations and recommendations concerning the security of frontier AI agents. These insights are informed by Perplexity's experience operating general-purpose agentic systems used by millions of users and thousands of enterprises in both controlled and open-world environments. Agent architectures change core assumptions around code-data separation, authority boundaries, and execution predictability, creating new confidentiality, integrity, and availability failure modes. We map principal attack surfaces across tools, connectors, hosting boundaries, and multi-agent coordination, with particular emphasis on indirect prompt injection, confused-deputy behavior, and cascading failures in long-running workflows. We then assess current defenses as a layered stack: input-level and model-level mitigations, sandboxed execution, and deterministic policy enforcement for high-consequence actions. Finally, we identify standards and research gaps, including adaptive security benchmarks, policy models for delegation and privilege control, and guidance for secure multi-agent system design aligned with NIST risk management principles.
DRACO: a Cross-Domain Benchmark for Deep Research Accuracy, Completeness, and Objectivity
Feb 12, 2026We present DRACO (Deep Research Accuracy, Completeness, and Objectivity), a benchmark of complex deep research tasks. These tasks, which span 10 domains and draw on information sources from 40 countries, originate from anonymized real-world usage patterns within a large-scale deep research system. Tasks are sampled from a de-identified dataset of Perplexity Deep Research requests, then filtered and augmented to ensure that the tasks are anonymized, open-ended and complex, objectively evaluable, and representative of the broad scope of real-world deep research use cases. Outputs are graded against task-specific rubrics along four dimensions: factual accuracy (accuracy), breadth and depth of analysis (including completeness), presentation quality (including objectivity), and citation quality. DRACO is publicly available at https://hf.co/datasets/perplexity-ai/draco.
The Adoption and Usage of AI Agents: Early Evidence from Perplexity
Dec 10, 2025



This paper presents the first large-scale field study of the adoption, usage intensity, and use cases of general-purpose AI agents operating in open-world web environments. Our analysis centers on Comet, an AI-powered browser developed by Perplexity, and its integrated agent, Comet Assistant. Drawing on hundreds of millions of anonymized user interactions, we address three fundamental questions: Who is using AI agents? How intensively are they using them? And what are they using them for? Our findings reveal substantial heterogeneity in adoption and usage across user segments. Earlier adopters, users in countries with higher GDP per capita and educational attainment, and individuals working in digital or knowledge-intensive sectors -- such as digital technology, academia, finance, marketing, and entrepreneurship -- are more likely to adopt or actively use the agent. To systematically characterize the substance of agent usage, we introduce a hierarchical agentic taxonomy that organizes use cases across three levels: topic, subtopic, and task. The two largest topics, Productivity & Workflow and Learning & Research, account for 57% of all agentic queries, while the two largest subtopics, Courses and Shopping for Goods, make up 22%. The top 10 out of 90 tasks represent 55% of queries. Personal use constitutes 55% of queries, while professional and educational contexts comprise 30% and 16%, respectively. In the short term, use cases exhibit strong stickiness, but over time users tend to shift toward more cognitively oriented topics. The diffusion of increasingly capable AI agents carries important implications for researchers, businesses, policymakers, and educators, inviting new lines of inquiry into this rapidly emerging class of AI capabilities.
Personality Prediction from Life Stories using Language Models
Jun 24, 2025Natural Language Processing (NLP) offers new avenues for personality assessment by leveraging rich, open-ended text, moving beyond traditional questionnaires. In this study, we address the challenge of modeling long narrative interview where each exceeds 2000 tokens so as to predict Five-Factor Model (FFM) personality traits. We propose a two-step approach: first, we extract contextual embeddings using sliding-window fine-tuning of pretrained language models; then, we apply Recurrent Neural Networks (RNNs) with attention mechanisms to integrate long-range dependencies and enhance interpretability. This hybrid method effectively bridges the strengths of pretrained transformers and sequence modeling to handle long-context data. Through ablation studies and comparisons with state-of-the-art long-context models such as LLaMA and Longformer, we demonstrate improvements in prediction accuracy, efficiency, and interpretability. Our results highlight the potential of combining language-based features with long-context modeling to advance personality assessment from life narratives.
Recent Developments in AI and USPTO Open Data
Jul 12, 2022The USPTO disseminates one of the largest publicly accessible repositories of scientific, technical, and commercial data worldwide. USPTO data has historically seen frequent use in fields such as patent analytics, economics, and prosecution & litigation tools. This article highlights an emerging class of usecases directed to the research, development, and application of artificial intelligence technology. Such usecases contemplate both the delivery of artificial intelligence capabilities for practical IP applications and the enablement of future state-of-the-art artificial intelligence research via USPTO data products. Examples from both within and beyond the USPTO are offered as case studies.
Energy-based models for atomic-resolution protein conformations
Apr 27, 2020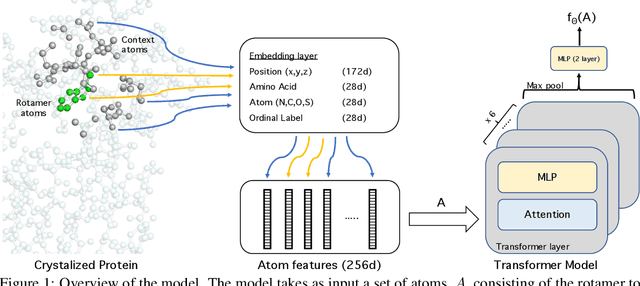
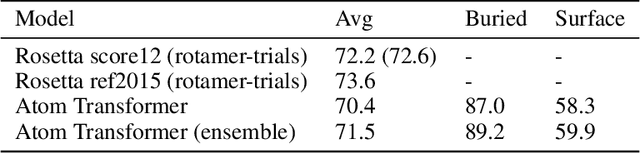
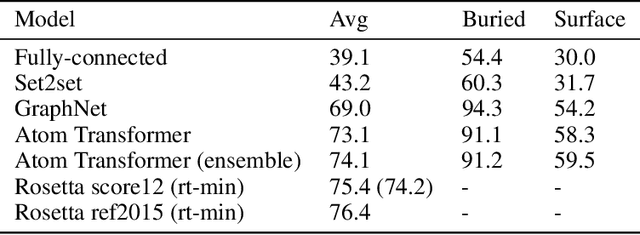
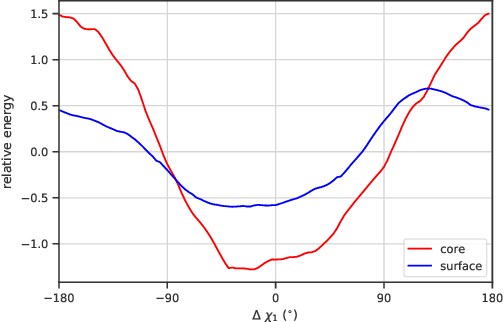
We propose an energy-based model (EBM) of protein conformations that operates at atomic scale. The model is trained solely on crystallized protein data. By contrast, existing approaches for scoring conformations use energy functions that incorporate knowledge of physical principles and features that are the complex product of several decades of research and tuning. To evaluate the model, we benchmark on the rotamer recovery task, the problem of predicting the conformation of a side chain from its context within a protein structure, which has been used to evaluate energy functions for protein design. The model achieves performance close to that of the Rosetta energy function, a state-of-the-art method widely used in protein structure prediction and design. An investigation of the model's outputs and hidden representations finds that it captures physicochemical properties relevant to protein energy.
* Accepted to ICLR 2020
On the adequacy of untuned warmup for adaptive optimization
Oct 09, 2019


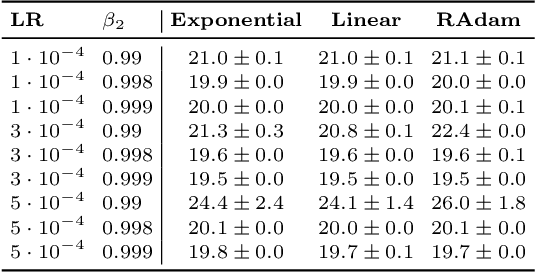
Adaptive optimization algorithms such as Adam (Kingma & Ba, 2014) are widely used in deep learning. The stability of such algorithms is often improved with a warmup schedule for the learning rate. Motivated by the difficulty of choosing and tuning warmup schedules, Liu et al. (2019) propose automatic variance rectification of Adam's adaptive learning rate, claiming that this rectified approach ("RAdam") surpasses the vanilla Adam algorithm and reduces the need for expensive tuning of Adam with warmup. In this work, we point out various shortcomings of this analysis. We then provide an alternative explanation for the necessity of warmup based on the magnitude of the update term, which is of greater relevance to training stability. Finally, we provide some "rule-of-thumb" warmup schedules, and we demonstrate that simple untuned warmup of Adam performs more-or-less identically to RAdam in typical practical settings. We conclude by suggesting that practitioners stick to linear warmup with Adam, with a sensible default being linear warmup over $2 / (1 - \beta_2)$ training iterations.
ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero
Feb 13, 2019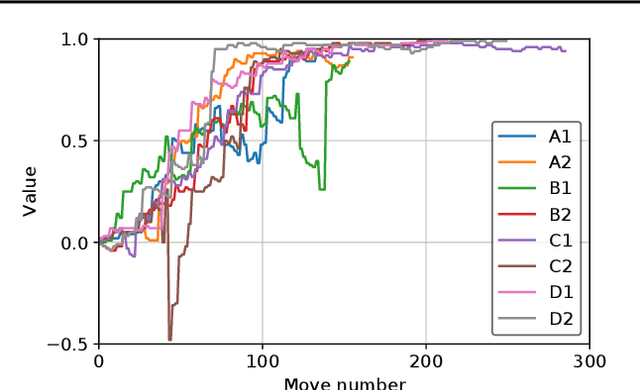

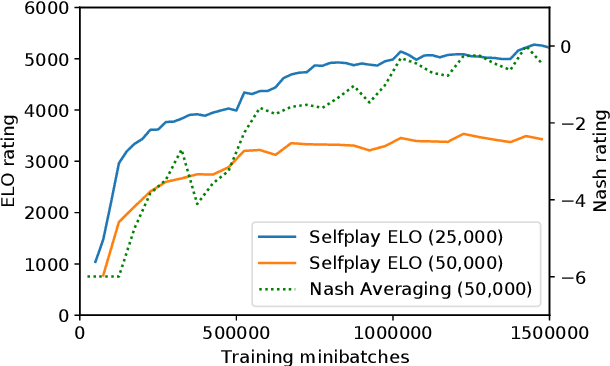
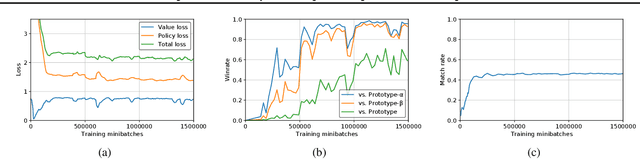
The AlphaGo, AlphaGo Zero, and AlphaZero series of algorithms are a remarkable demonstration of deep reinforcement learning's capabilities, achieving superhuman performance in the complex game of Go with progressively increasing autonomy. However, many obstacles remain in the understanding of and usability of these promising approaches by the research community. Toward elucidating unresolved mysteries and facilitating future research, we propose ELF OpenGo, an open-source reimplementation of the AlphaZero algorithm. ELF OpenGo is the first open-source Go AI to convincingly demonstrate superhuman performance with a perfect (20:0) record against global top professionals. We apply ELF OpenGo to conduct extensive ablation studies, and to identify and analyze numerous interesting phenomena in both the model training and in the gameplay inference procedures. Our code, models, selfplay datasets, and auxiliary data are publicly available.
Quasi-hyperbolic momentum and Adam for deep learning
Oct 16, 2018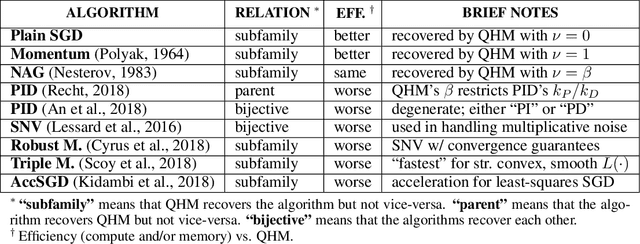
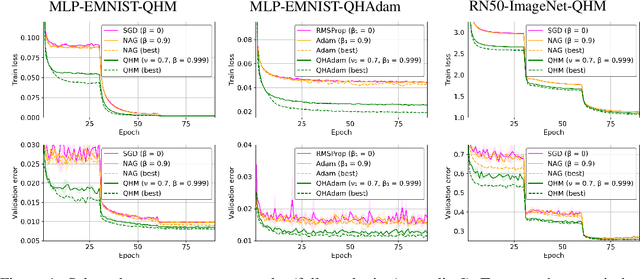
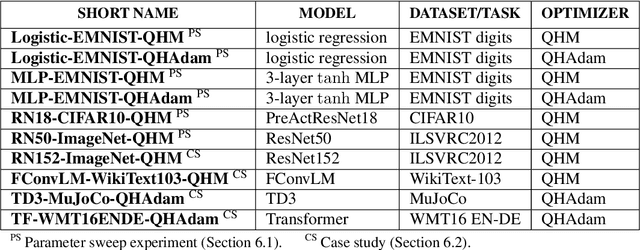

Momentum-based acceleration of stochastic gradient descent (SGD) is widely used in deep learning. We propose the quasi-hyperbolic momentum algorithm (QHM) as an extremely simple alteration of momentum SGD, averaging a plain SGD step with a momentum step. We describe numerous connections to and identities with other algorithms, and we characterize the set of two-state optimization algorithms that QHM can recover. Finally, we propose a QH variant of Adam called QHAdam, and we empirically demonstrate that our algorithms lead to significantly improved training in a variety of settings, including a new state-of-the-art result on WMT16 EN-DE. We hope that these empirical results, combined with the conceptual and practical simplicity of QHM and QHAdam, will spur interest from both practitioners and researchers. PyTorch code is immediately available.