 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale High-Quality 3D Gaussian Head Reconstruction from Multi-View Captures
May 05, 2026We propose HeadsUp, a scalable feed-forward method for reconstructing high-quality 3D Gaussian heads from large-scale multi-camera setups. Our method employs an efficient encoder-decoder architecture that compresses input views into a compact latent representation. This latent representation is then decoded into a set of UV-parameterized 3D Gaussians anchored to a neutral head template. This UV representation decouples the number of 3D Gaussians from the number and resolution of input images, enabling training with many high-resolution input views. We train and evaluate our model on an internal dataset with more than 10,000 subjects, which is an order of magnitude larger than existing multi-view human head datasets. HeadsUp achieves state-of-the-art reconstruction quality and generalizes to novel identities without test-time optimization. We extensively analyze the scaling behavior of our model across identities, views, and model capacity, revealing practical insights for quality-compute trade-offs. Finally, we highlight the strength of our latent space by showcasing two downstream applications: generating novel 3D identities and animating the 3D heads with expression blendshapes.
Multilingual Language Models Encode Script Over Linguistic Structure
Apr 06, 2026Multilingual language models (LMs) organize representations for typologically and orthographically diverse languages into a shared parameter space, yet the nature of this internal organization remains elusive. In this work, we investigate which linguistic properties - abstract language identity or surface-form cues - shape multilingual representations. Focusing on compact, distilled models where representational trade-offs are explicit, we analyze language-associated units in Llama-3.2-1B and Gemma-2-2B using the Language Activation Probability Entropy (LAPE) metric, and further decompose activations with Sparse Autoencoders. We find that these units are strongly conditioned on orthography: romanization induces near-disjoint representations that align with neither native-script inputs nor English, while word-order shuffling has limited effect on unit identity. Probing shows that typological structure becomes increasingly accessible in deeper layers, while causal interventions indicate that generation is most sensitive to units that are invariant to surface-form perturbations rather than to units identified by typological alignment alone. Overall, our results suggest that multilingual LMs organize representations around surface form, with linguistic abstraction emerging gradually without collapsing into a unified interlingua.
Personality Prediction from Life Stories using Language Models
Jun 24, 2025Natural Language Processing (NLP) offers new avenues for personality assessment by leveraging rich, open-ended text, moving beyond traditional questionnaires. In this study, we address the challenge of modeling long narrative interview where each exceeds 2000 tokens so as to predict Five-Factor Model (FFM) personality traits. We propose a two-step approach: first, we extract contextual embeddings using sliding-window fine-tuning of pretrained language models; then, we apply Recurrent Neural Networks (RNNs) with attention mechanisms to integrate long-range dependencies and enhance interpretability. This hybrid method effectively bridges the strengths of pretrained transformers and sequence modeling to handle long-context data. Through ablation studies and comparisons with state-of-the-art long-context models such as LLaMA and Longformer, we demonstrate improvements in prediction accuracy, efficiency, and interpretability. Our results highlight the potential of combining language-based features with long-context modeling to advance personality assessment from life narratives.
Equitable Electronic Health Record Prediction with FAME: Fairness-Aware Multimodal Embedding
Jun 16, 2025



Electronic Health Record (EHR) data encompass diverse modalities -- text, images, and medical codes -- that are vital for clinical decision-making. To process these complex data, multimodal AI (MAI) has emerged as a powerful approach for fusing such information. However, most existing MAI models optimize for better prediction performance, potentially reinforcing biases across patient subgroups. Although bias-reduction techniques for multimodal models have been proposed, the individual strengths of each modality and their interplay in both reducing bias and optimizing performance remain underexplored. In this work, we introduce FAME (Fairness-Aware Multimodal Embeddings), a framework that explicitly weights each modality according to its fairness contribution. FAME optimizes both performance and fairness by incorporating a combined loss function. We leverage the Error Distribution Disparity Index (EDDI) to measure fairness across subgroups and propose a sign-agnostic aggregation method to balance fairness across subgroups, ensuring equitable model outcomes. We evaluate FAME with BEHRT and BioClinicalBERT, combining structured and unstructured EHR data, and demonstrate its effectiveness in terms of performance and fairness compared with other baselines across multiple EHR prediction tasks.
An Interoperable Machine Learning Pipeline for Pediatric Obesity Risk Estimation
Dec 12, 2024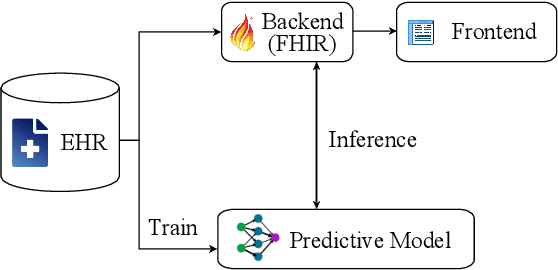
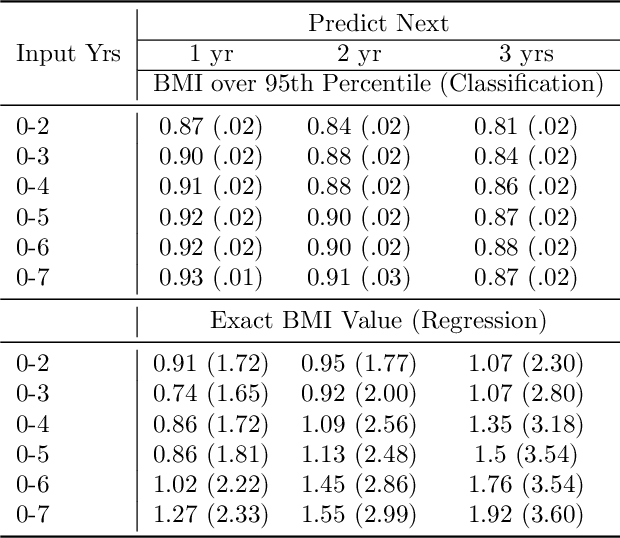
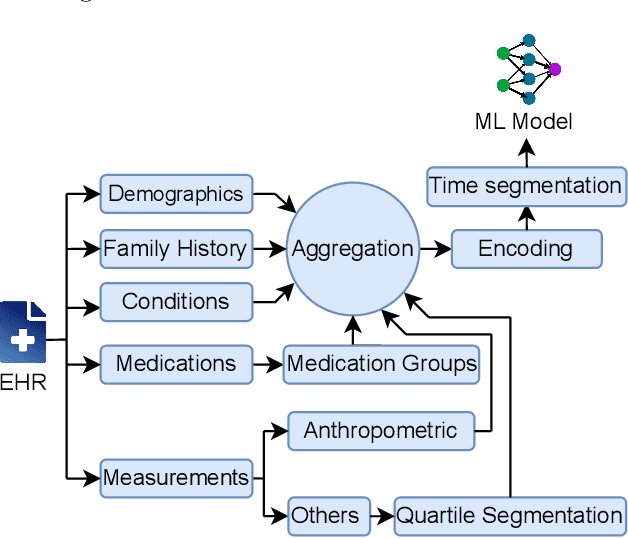
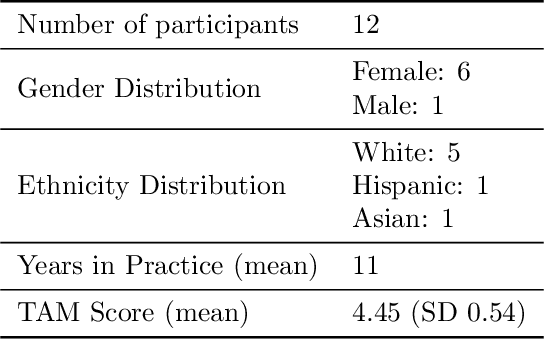
Reliable prediction of pediatric obesity can offer a valuable resource to providers, helping them engage in timely preventive interventions before the disease is established. Many efforts have been made to develop ML-based predictive models of obesity, and some studies have reported high predictive performances. However, no commonly used clinical decision support tool based on existing ML models currently exists. This study presents a novel end-to-end pipeline specifically designed for pediatric obesity prediction, which supports the entire process of data extraction, inference, and communication via an API or a user interface. While focusing only on routinely recorded data in pediatric electronic health records (EHRs), our pipeline uses a diverse expert-curated list of medical concepts to predict the 1-3 years risk of developing obesity. Furthermore, by using the Fast Healthcare Interoperability Resources (FHIR) standard in our design procedure, we specifically target facilitating low-effort integration of our pipeline with different EHR systems. In our experiments, we report the effectiveness of the predictive model as well as its alignment with the feedback from various stakeholders, including ML scientists, providers, health IT personnel, health administration representatives, and patient group representatives.
HealthGAT: Node Classifications in Electronic Health Records using Graph Attention Networks
Mar 26, 2024
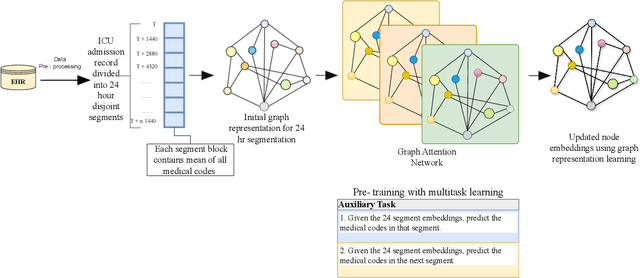
While electronic health records (EHRs) are widely used across various applications in healthcare, most applications use the EHRs in their raw (tabular) format. Relying on raw or simple data pre-processing can greatly limit the performance or even applicability of downstream tasks using EHRs. To address this challenge, we present HealthGAT, a novel graph attention network framework that utilizes a hierarchical approach to generate embeddings from EHR, surpassing traditional graph-based methods. Our model iteratively refines the embeddings for medical codes, resulting in improved EHR data analysis. We also introduce customized EHR-centric auxiliary pre-training tasks to leverage the rich medical knowledge embedded within the data. This approach provides a comprehensive analysis of complex medical relationships and offers significant advancement over standard data representation techniques. HealthGAT has demonstrated its effectiveness in various healthcare scenarios through comprehensive evaluations against established methodologies. Specifically, our model shows outstanding performance in node classification and downstream tasks such as predicting readmissions and diagnosis classifications. Our code is available at https://github.com/healthylaife/HealthGAT
An Extensive Data Processing Pipeline for MIMIC-IV
Apr 29, 2022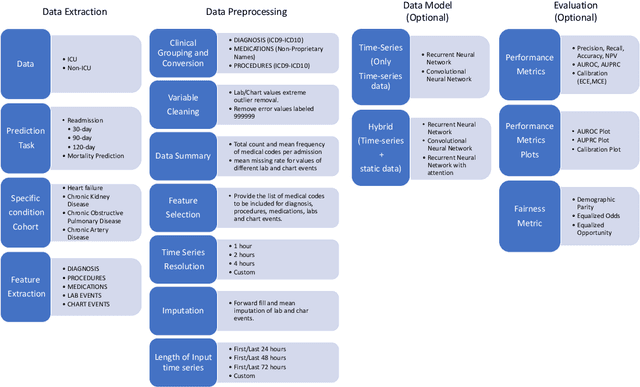

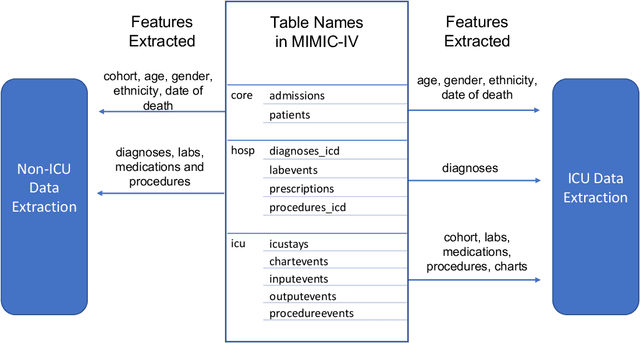
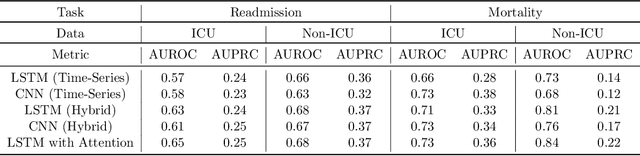
An increasing amount of research is being devoted to applying machine learning methods to electronic health record (EHR) data for various clinical tasks. This growing area of research has exposed the limitation of accessibility of EHR datasets for all, as well as the reproducibility of different modeling frameworks. One reason for these limitations is the lack of standardized pre-processing pipelines. MIMIC is a freely available EHR dataset in a raw format that has been used in numerous studies. The absence of standardized pre-processing steps serves as a major barrier to the wider adoption of the dataset. It also leads to different cohorts being used in downstream tasks, limiting the ability to compare the results among similar studies. Contrasting studies also use various distinct performance metrics, which can greatly reduce the ability to compare model results. In this work, we provide an end-to-end fully customizable pipeline to extract, clean, and pre-process data; and to predict and evaluate the fourth version of the MIMIC dataset (MIMIC-IV) for ICU and non-ICU-related clinical time-series prediction tasks.
Exploring the Scope of Using News Articles to Understand Development Patterns of Districts in India
Jul 03, 2021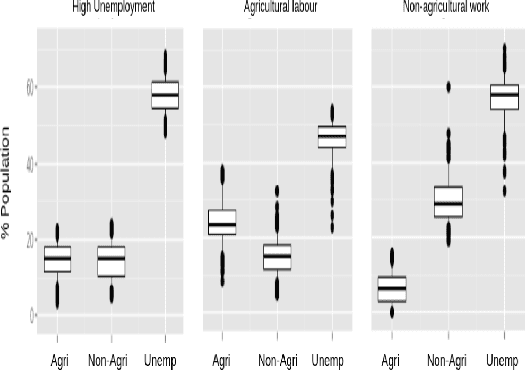
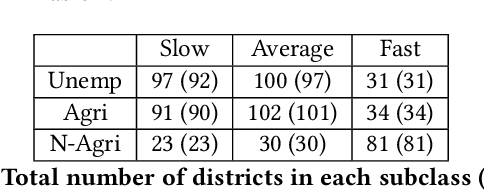
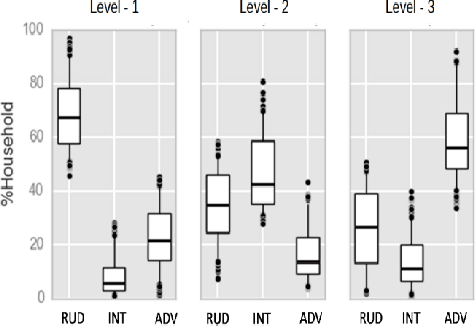

Understanding what factors bring about socio-economic development may often suffer from the streetlight effect, of analyzing the effect of only those variables that have been measured and are therefore available for analysis. How do we check whether all worthwhile variables have been instrumented and considered when building an econometric development model? We attempt to address this question by building unsupervised learning methods to identify and rank news articles about diverse events occurring in different districts of India, that can provide insights about what may have transpired in the districts. This can help determine whether variables related to these events are indeed available or not to model the development of these districts. We also describe several other applications that emerge from this approach, such as to use news articles to understand why pairs of districts that may have had similar socio-economic indicators approximately ten years back ended up at different levels of development currently, and another application that generates a newsfeed of unusual news articles that do not conform to news articles about typical districts with a similar socio-economic profile. These applications outline the need for qualitative data to augment models based on quantitative data, and are meant to open up research on new ways to mine information from unstructured qualitative data to understand development.
* 11 pages of main text, 4 pages of supplementary material
Generalized Iris Presentation Attack Detection Algorithm under Cross-Database Settings
Oct 25, 2020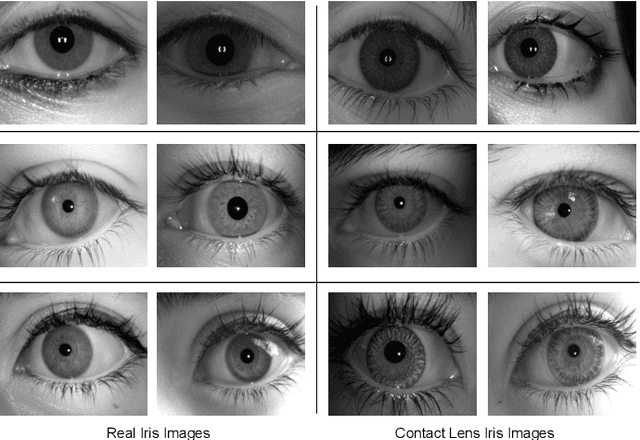

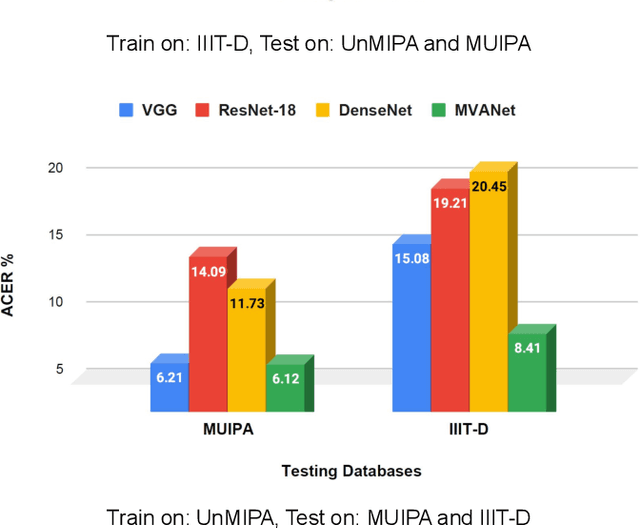

Presentation attacks are posing major challenges to most of the biometric modalities. Iris recognition, which is considered as one of the most accurate biometric modality for person identification, has also been shown to be vulnerable to advanced presentation attacks such as 3D contact lenses and textured lens. While in the literature, several presentation attack detection (PAD) algorithms are presented; a significant limitation is the generalizability against an unseen database, unseen sensor, and different imaging environment. To address this challenge, we propose a generalized deep learning-based PAD network, MVANet, which utilizes multiple representation layers. It is inspired by the simplicity and success of hybrid algorithm or fusion of multiple detection networks. The computational complexity is an essential factor in training deep neural networks; therefore, to reduce the computational complexity while learning multiple feature representation layers, a fixed base model has been used. The performance of the proposed network is demonstrated on multiple databases such as IIITD-WVU MUIPA and IIITD-CLI databases under cross-database training-testing settings, to assess the generalizability of the proposed algorithm.
Time-series Imputation and Prediction with Bi-Directional Generative Adversarial Networks
Sep 18, 2020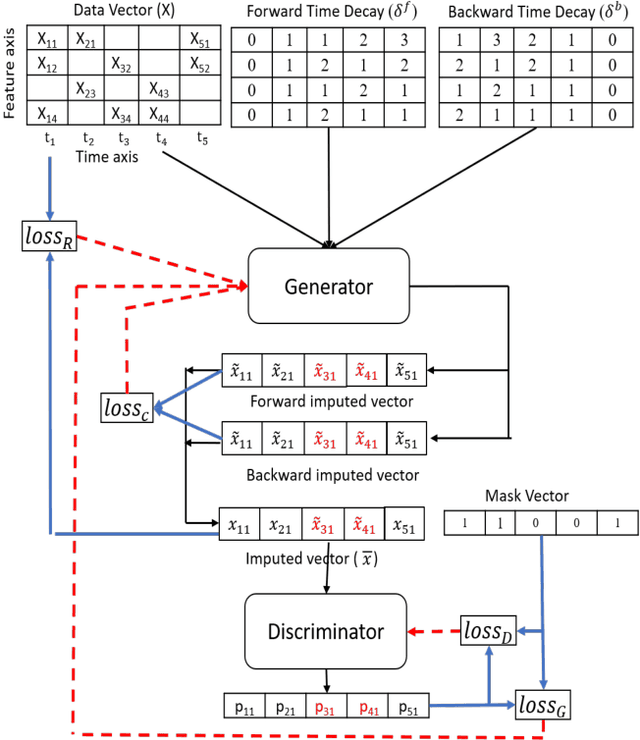
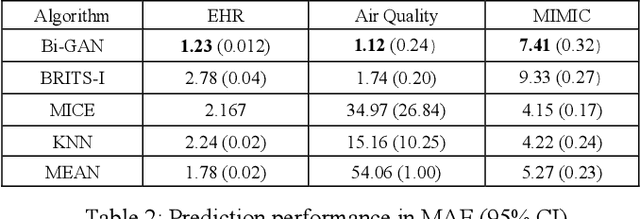
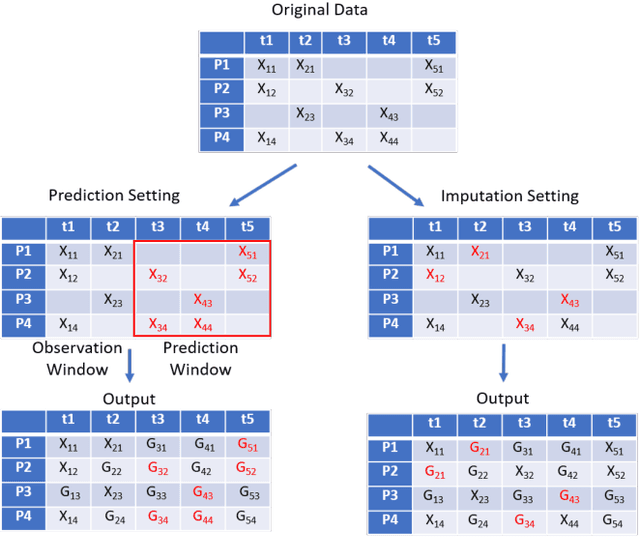

Multivariate time-series data are used in many classification and regression predictive tasks, and recurrent models have been widely used for such tasks. Most common recurrent models assume that time-series data elements are of equal length and the ordered observations are recorded at regular intervals. However, real-world time-series data have neither a similar length nor a same number of observations. They also have missing entries, which hinders the performance of predictive tasks. In this paper, we approach these issues by presenting a model for the combined task of imputing and predicting values for the irregularly observed and varying length time-series data with missing entries. Our proposed model (Bi-GAN) uses a bidirectional recurrent network in a generative adversarial setting. The generator is a bidirectional recurrent network that receives actual incomplete data and imputes the missing values. The discriminator attempts to discriminate between the actual and the imputed values in the output of the generator. Our model learns how to impute missing elements in-between (imputation) or outside of the input time steps (prediction), hence working as an effective any-time prediction tool for time-series data. Our method has three advantages to the state-of-the-art methods in the field: (a) single model can be used for both imputation and prediction tasks; (b) it can perform prediction task for time-series of varying length with missing data; (c) it does not require to know the observation and prediction time window during training which provides a flexible length of prediction window for both long-term and short-term predictions. We evaluate our model on two public datasets and on another large real-world electronic health records dataset to impute and predict body mass index (BMI) values in children and show its superior performance in both settings.