 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOzone Cues Mitigate Reflected Downwelling Radiance in LWIR Absorption-Based Ranging
Feb 27, 2026Passive long-wave infrared (LWIR) absorption-based ranging relies on atmospheric absorption to estimate distances to objects from their emitted thermal radiation. First demonstrated decades ago for objects much hotter than the air and recently extended to scenes with low temperature variations, this ranging has depended on reflected radiance being negligible. Downwelling radiance is especially problematic, sometimes causing large inaccuracies. In two new ranging methods, we use characteristic features from ozone absorption to estimate the contribution of reflected downwelling radiance. The quadspectral method gives a simple closed-form range estimate from four narrowband measurements, two at a water vapor absorption line and two at an ozone absorption line. The hyperspectral method uses a broader spectral range to improve accuracy while also providing estimates of temperature, emissivity profiles, and contributions of downwelling from a collection of zenith angles. Experimental results demonstrate improved ranging accuracy, in one case reducing error from over 100 m when reflected light is not modeled to 6.8 m with the quadspectral method and 1.2 m with the hyperspectral method.
Beam Cross Sections Create Mixtures: Improving Feature Localization in Secondary Electron Imaging
Aug 13, 2025Secondary electron (SE) imaging techniques, such as scanning electron microscopy and helium ion microscopy (HIM), use electrons emitted by a sample in response to a focused beam of charged particles incident at a grid of raster scan positions. Spot size -- the diameter of the incident beam's spatial profile -- is one of the limiting factors for resolution, along with various sources of noise in the SE signal. The effect of the beam spatial profile is commonly understood as convolutional. We show that under a simple and plausible physical abstraction for the beam, though convolution describes the mean of the SE counts, the full distribution of SE counts is a mixture. We demonstrate that this more detailed modeling can enable resolution improvements over conventional estimators through a stylized application in semiconductor inspection of localizing the edge in a two-valued sample. We derive Fisher information about edge location in conventional and time-resolved measurements (TRM) and also derive the maximum likelihood estimate (MLE) from the latter. Empirically, the MLE computed from TRM is approximately efficient except at very low beam diameter, so Fisher information comparisons are predictive of performance and can be used to optimize the beam diameter relative to the raster scan spacing. Monte Carlo simulations show that the MLE gives a 5-fold reduction in root mean-squared error (RMSE) of edge localization as compared to conventional interpolation-based estimation. Applied to three real HIM datasets, the average RMSE reduction factor is 5.4.
A Novel Sector-Based Algorithm for an Optimized Star-Galaxy Classification
Apr 01, 2024This paper introduces a novel sector-based methodology for star-galaxy classification, leveraging the latest Sloan Digital Sky Survey data (SDSS-DR18). By strategically segmenting the sky into sectors aligned with SDSS observational patterns and employing a dedicated convolutional neural network (CNN), we achieve state-of-the-art performance for star galaxy classification. Our preliminary results demonstrate a promising pathway for efficient and precise astronomical analysis, especially in real-time observational settings.
Online Beam Current Estimation in Particle Beam Microscopy
Nov 20, 2021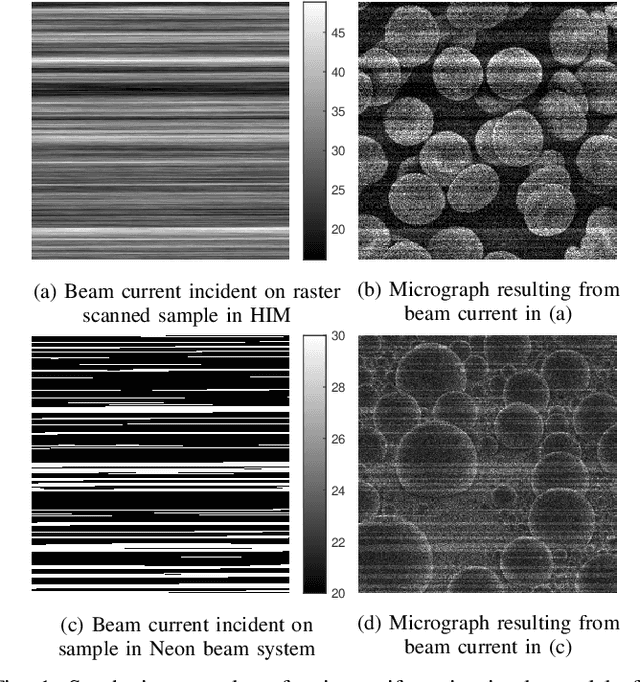
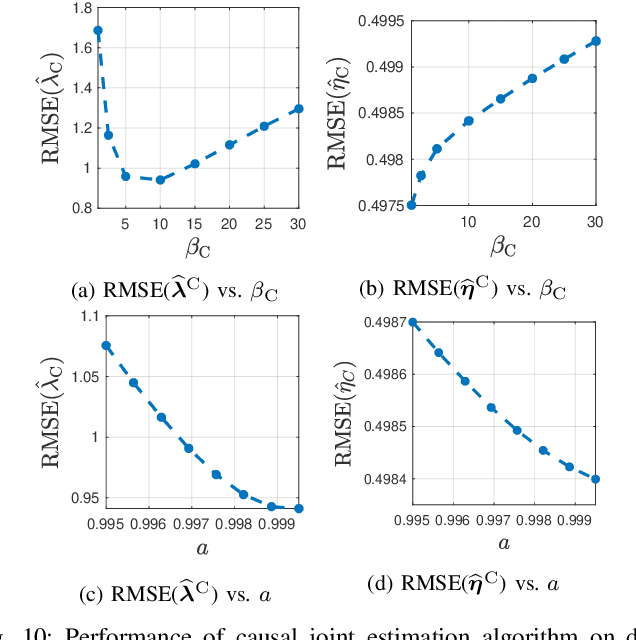
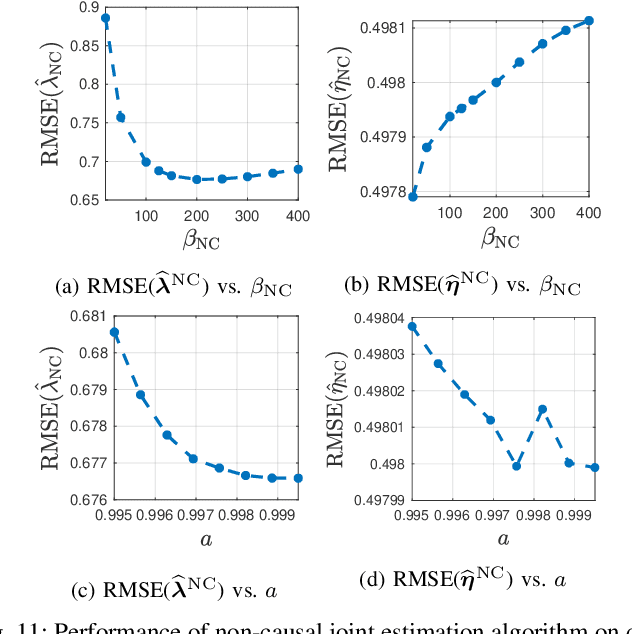
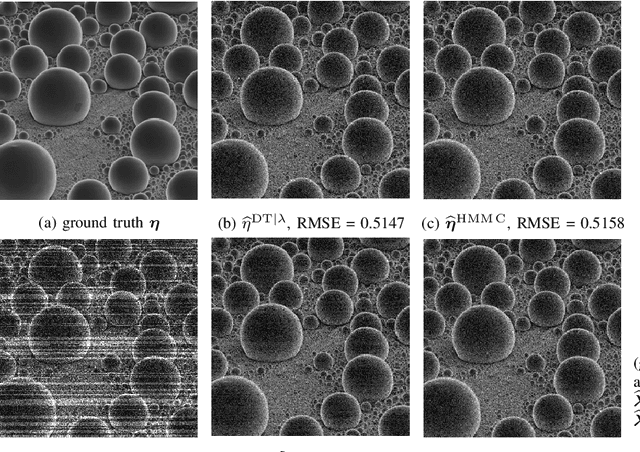
In conventional particle beam microscopy, knowledge of the beam current is essential for accurate micrograph formation and sample milling. This generally necessitates offline calibration of the instrument. In this work, we establish that beam current can be estimated online, from the same secondary electron count data that is used to form micrographs. Our methods depend on the recently introduced time-resolved measurement concept, which combines multiple short measurements at a single pixel and has previously been shown to partially mitigate the effect of beam current variation on micrograph accuracy. We analyze the problem of jointly estimating beam current and secondary electron yield using the Cramer-Rao bound. Joint estimators operating at a single pixel and estimators that exploit models for inter-pixel correlation and Markov beam current variation are proposed and tested on synthetic microscopy data. Our estimates of secondary electron yield that incorporate explicit beam current estimation beat state-of-the-art methods, resulting in micrograph accuracy nearly indistinguishable from what is obtained with perfect beam current knowledge. Our novel beam current estimation could help improve milling outcomes, prevent sample damage, and enable online instrument diagnostics.
MD-CSDNetwork: Multi-Domain Cross Stitched Network for Deepfake Detection
Sep 15, 2021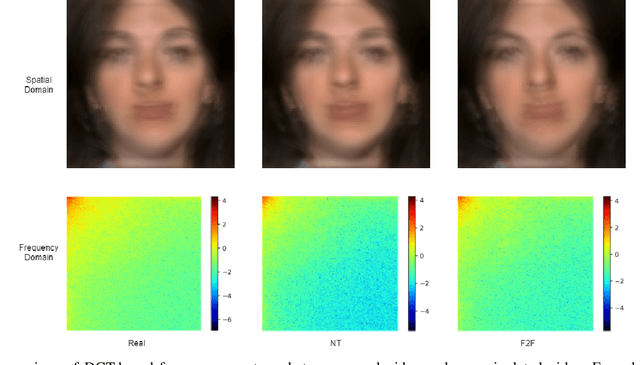
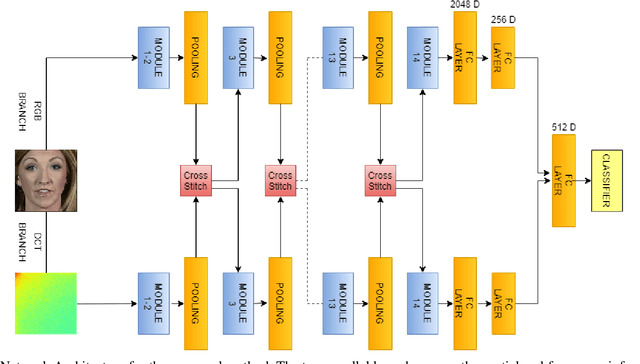
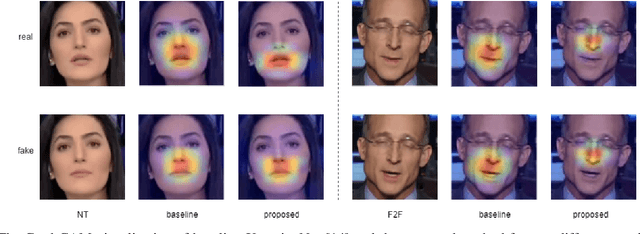
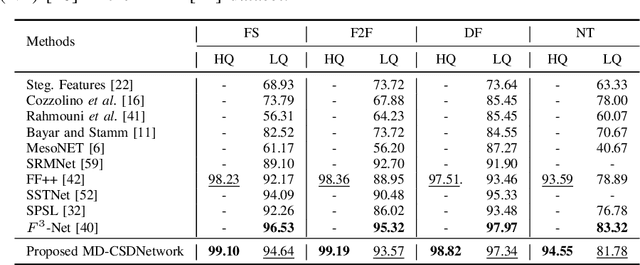
The rapid progress in the ease of creating and spreading ultra-realistic media over social platforms calls for an urgent need to develop a generalizable deepfake detection technique. It has been observed that current deepfake generation methods leave discriminative artifacts in the frequency spectrum of fake images and videos. Inspired by this observation, in this paper, we present a novel approach, termed as MD-CSDNetwork, for combining the features in the spatial and frequency domains to mine a shared discriminative representation for classifying \textit{deepfakes}. MD-CSDNetwork is a novel cross-stitched network with two parallel branches carrying the spatial and frequency information, respectively. We hypothesize that these multi-domain input data streams can be considered as related supervisory signals. The supervision from both branches ensures better performance and generalization. Further, the concept of cross-stitch connections is utilized where they are inserted between the two branches to learn an optimal combination of domain-specific and shared representations from other domains automatically. Extensive experiments are conducted on the popular benchmark dataset namely FaceForeniscs++ for forgery classification. We report improvements over all the manipulation types in FaceForensics++ dataset and comparable results with state-of-the-art methods for cross-database evaluation on the Celeb-DF dataset and the Deepfake Detection Dataset.
Evaluating Empathetic Chatbots in Customer Service Settings
Jan 05, 2021

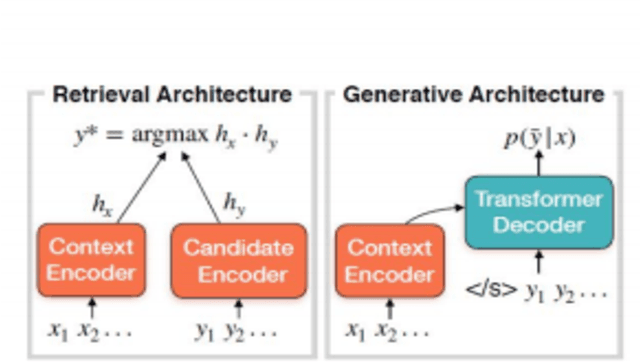
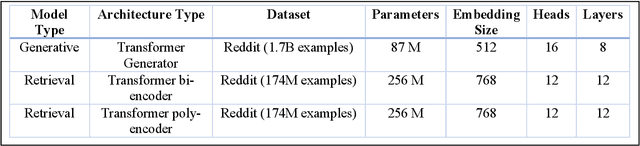
Customer service is a setting that calls for empathy in live human agent responses. Recent advances have demonstrated how open-domain chatbots can be trained to demonstrate empathy when responding to live human utterances. We show that a blended skills chatbot model that responds to customer queries is more likely to resemble actual human agent response if it is trained to recognize emotion and exhibit appropriate empathy, than a model without such training. For our analysis, we leverage a Twitter customer service dataset containing several million customer<->agent dialog examples in customer service contexts from 20 well-known brands.
WaveTransform: Crafting Adversarial Examples via Input Decomposition
Oct 29, 2020
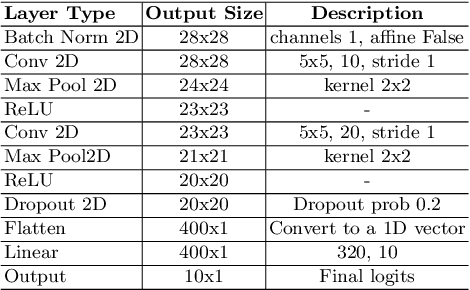
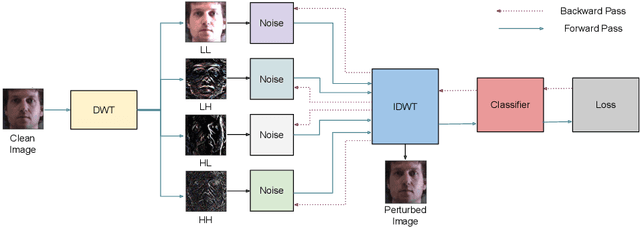
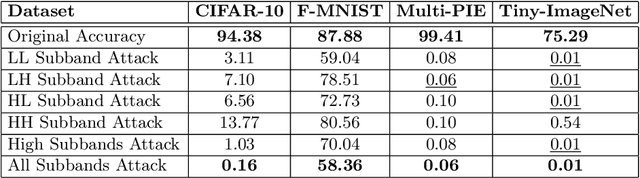
Frequency spectrum has played a significant role in learning unique and discriminating features for object recognition. Both low and high frequency information present in images have been extracted and learnt by a host of representation learning techniques, including deep learning. Inspired by this observation, we introduce a novel class of adversarial attacks, namely `WaveTransform', that creates adversarial noise corresponding to low-frequency and high-frequency subbands, separately (or in combination). The frequency subbands are analyzed using wavelet decomposition; the subbands are corrupted and then used to construct an adversarial example. Experiments are performed using multiple databases and CNN models to establish the effectiveness of the proposed WaveTransform attack and analyze the importance of a particular frequency component. The robustness of the proposed attack is also evaluated through its transferability and resiliency against a recent adversarial defense algorithm. Experiments show that the proposed attack is effective against the defense algorithm and is also transferable across CNNs.
Attack Agnostic Adversarial Defense via Visual Imperceptible Bound
Oct 25, 2020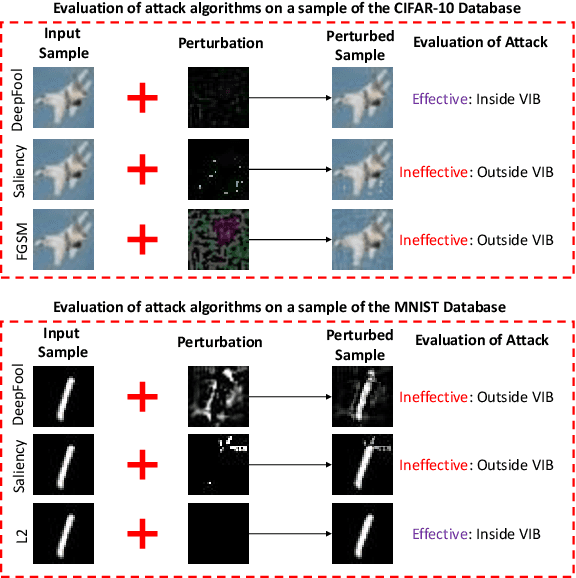
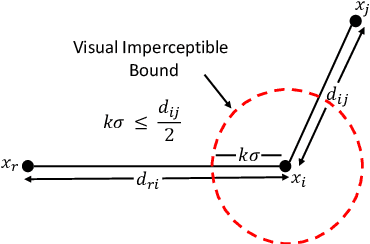
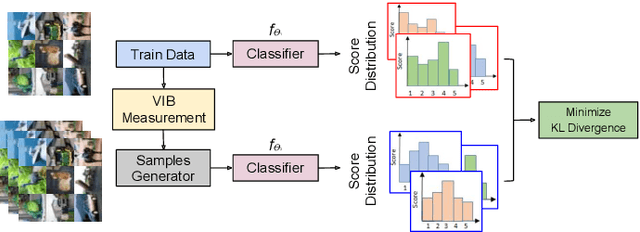
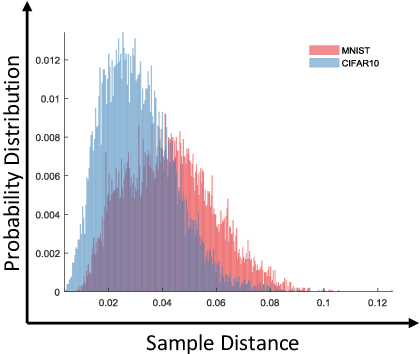
The high susceptibility of deep learning algorithms against structured and unstructured perturbations has motivated the development of efficient adversarial defense algorithms. However, the lack of generalizability of existing defense algorithms and the high variability in the performance of the attack algorithms for different databases raises several questions on the effectiveness of the defense algorithms. In this research, we aim to design a defense model that is robust within a certain bound against both seen and unseen adversarial attacks. This bound is related to the visual appearance of an image, and we termed it as \textit{Visual Imperceptible Bound (VIB)}. To compute this bound, we propose a novel method that uses the database characteristics. The VIB is further used to measure the effectiveness of attack algorithms. The performance of the proposed defense model is evaluated on the MNIST, CIFAR-10, and Tiny ImageNet databases on multiple attacks that include C\&W ($l_2$) and DeepFool. The proposed defense model is not only able to increase the robustness against several attacks but also retain or improve the classification accuracy on an original clean test set. The proposed algorithm is attack agnostic, i.e. it does not require any knowledge of the attack algorithm.
MixNet for Generalized Face Presentation Attack Detection
Oct 25, 2020
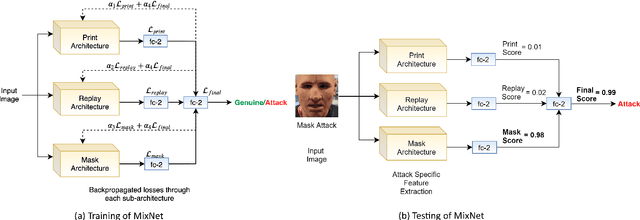

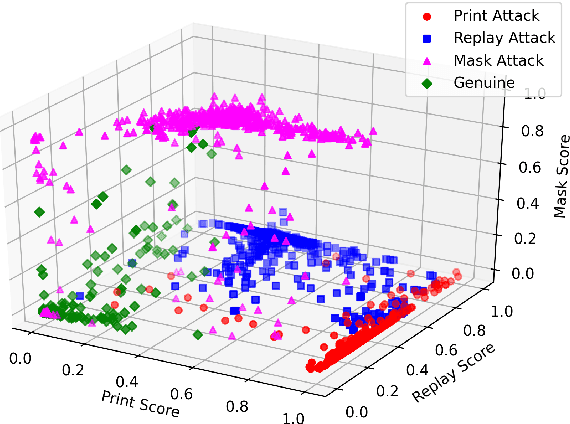
The non-intrusive nature and high accuracy of face recognition algorithms have led to their successful deployment across multiple applications ranging from border access to mobile unlocking and digital payments. However, their vulnerability against sophisticated and cost-effective presentation attack mediums raises essential questions regarding its reliability. In the literature, several presentation attack detection algorithms are presented; however, they are still far behind from reality. The major problem with existing work is the generalizability against multiple attacks both in the seen and unseen setting. The algorithms which are useful for one kind of attack (such as print) perform unsatisfactorily for another type of attack (such as silicone masks). In this research, we have proposed a deep learning-based network termed as \textit{MixNet} to detect presentation attacks in cross-database and unseen attack settings. The proposed algorithm utilizes state-of-the-art convolutional neural network architectures and learns the feature mapping for each attack category. Experiments are performed using multiple challenging face presentation attack databases such as SMAD and Spoof In the Wild (SiW-M) databases. Extensive experiments and comparison with existing state of the art algorithms show the effectiveness of the proposed algorithm.
Generalized Iris Presentation Attack Detection Algorithm under Cross-Database Settings
Oct 25, 2020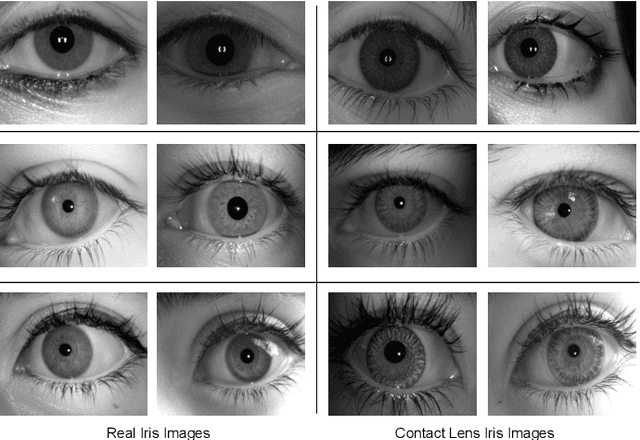

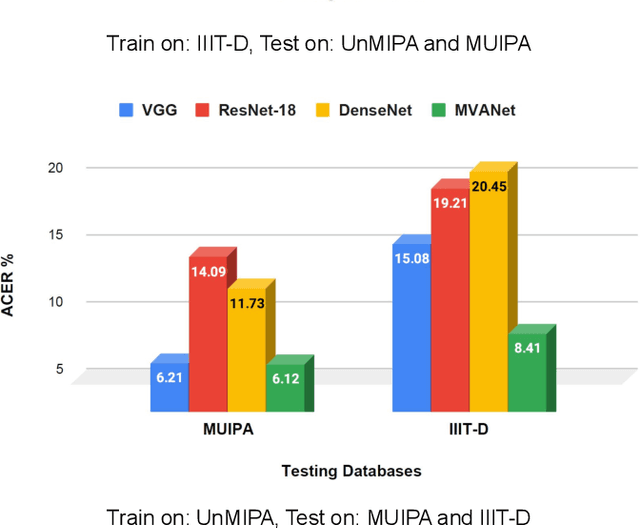

Presentation attacks are posing major challenges to most of the biometric modalities. Iris recognition, which is considered as one of the most accurate biometric modality for person identification, has also been shown to be vulnerable to advanced presentation attacks such as 3D contact lenses and textured lens. While in the literature, several presentation attack detection (PAD) algorithms are presented; a significant limitation is the generalizability against an unseen database, unseen sensor, and different imaging environment. To address this challenge, we propose a generalized deep learning-based PAD network, MVANet, which utilizes multiple representation layers. It is inspired by the simplicity and success of hybrid algorithm or fusion of multiple detection networks. The computational complexity is an essential factor in training deep neural networks; therefore, to reduce the computational complexity while learning multiple feature representation layers, a fixed base model has been used. The performance of the proposed network is demonstrated on multiple databases such as IIITD-WVU MUIPA and IIITD-CLI databases under cross-database training-testing settings, to assess the generalizability of the proposed algorithm.