 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMD-CSDNetwork: Multi-Domain Cross Stitched Network for Deepfake Detection
Paper and Code
Sep 15, 2021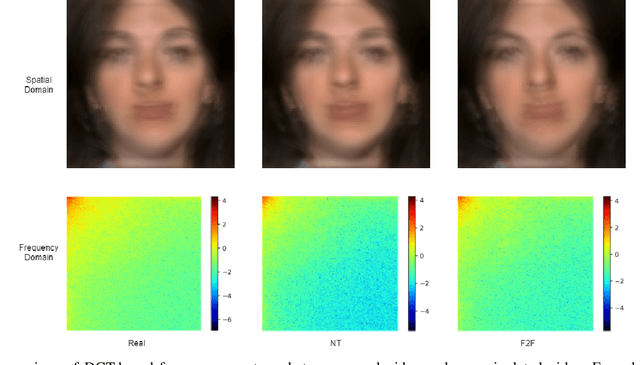
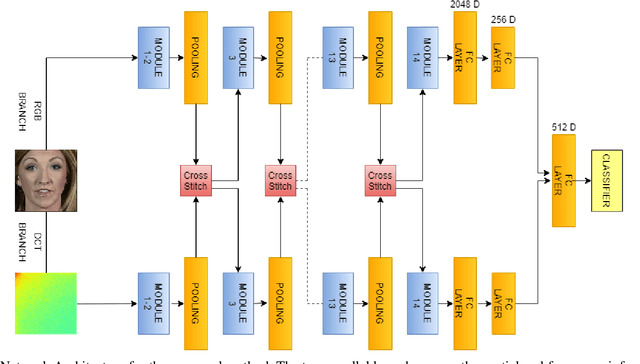
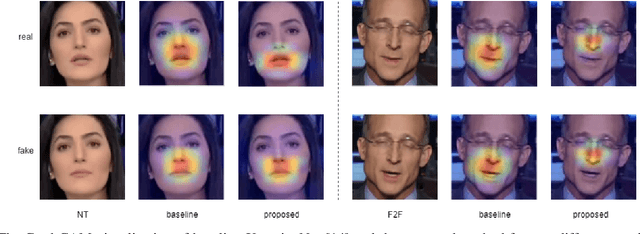
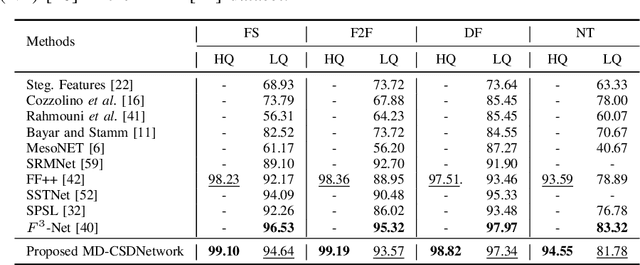
The rapid progress in the ease of creating and spreading ultra-realistic media over social platforms calls for an urgent need to develop a generalizable deepfake detection technique. It has been observed that current deepfake generation methods leave discriminative artifacts in the frequency spectrum of fake images and videos. Inspired by this observation, in this paper, we present a novel approach, termed as MD-CSDNetwork, for combining the features in the spatial and frequency domains to mine a shared discriminative representation for classifying \textit{deepfakes}. MD-CSDNetwork is a novel cross-stitched network with two parallel branches carrying the spatial and frequency information, respectively. We hypothesize that these multi-domain input data streams can be considered as related supervisory signals. The supervision from both branches ensures better performance and generalization. Further, the concept of cross-stitch connections is utilized where they are inserted between the two branches to learn an optimal combination of domain-specific and shared representations from other domains automatically. Extensive experiments are conducted on the popular benchmark dataset namely FaceForeniscs++ for forgery classification. We report improvements over all the manipulation types in FaceForensics++ dataset and comparable results with state-of-the-art methods for cross-database evaluation on the Celeb-DF dataset and the Deepfake Detection Dataset.