 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence In Patent And Market Intelligence: A New Paradigm For Technology Scouting
Jul 27, 2025This paper presents the development of an AI powered software platform that leverages advanced large language models (LLMs) to transform technology scouting and solution discovery in industrial R&D. Traditional approaches to solving complex research and development challenges are often time consuming, manually driven, and heavily dependent on domain specific expertise. These methods typically involve navigating fragmented sources such as patent repositories, commercial product catalogs, and competitor data, leading to inefficiencies and incomplete insights. The proposed platform utilizes cutting edge LLM capabilities including semantic understanding, contextual reasoning, and cross-domain knowledge extraction to interpret problem statements and retrieve high-quality, sustainable solutions. The system processes unstructured patent texts, such as claims and technical descriptions, and systematically extracts potential innovations aligned with the given problem context. These solutions are then algorithmically organized under standardized technical categories and subcategories to ensure clarity and relevance across interdisciplinary domains. In addition to patent analysis, the platform integrates commercial intelligence by identifying validated market solutions and active organizations addressing similar challenges. This combined insight sourced from both intellectual property and real world product data enables R&D teams to assess not only technical novelty but also feasibility, scalability, and sustainability. The result is a comprehensive, AI driven scouting engine that reduces manual effort, accelerates innovation cycles, and enhances decision making in complex R&D environments.
Artificial Intelligence implementation of onboard flexible payload and adaptive beamforming using commercial off-the-shelf devices
May 03, 2025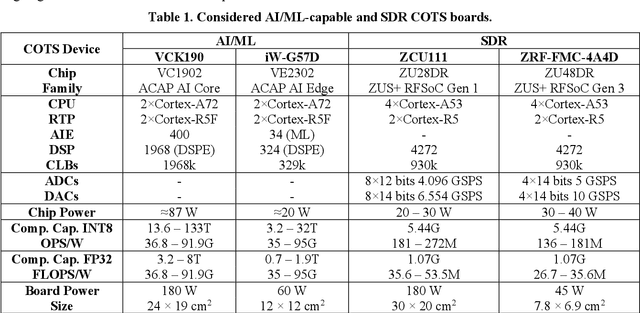
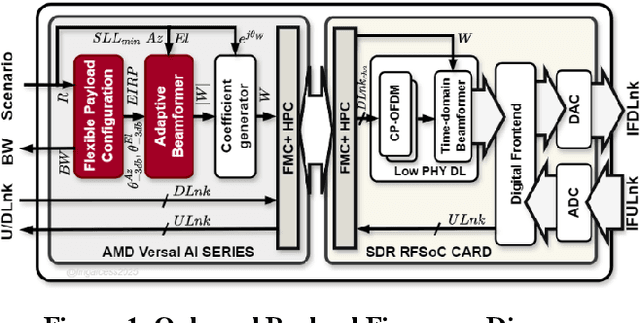


Very High Throughput satellites typically provide multibeam coverage, however, a common problem is that there can be a mismatch between the capacity of each beam and the traffic demand: some beams may fall short, while others exceed the requirements. This challenge can be addressed by integrating machine learning with flexible payload and adaptive beamforming techniques. These methods allow for dynamic allocation of payload resources based on real-time capacity needs. As artificial intelligence advances, its ability to automate tasks, enhance efficiency, and increase precision is proving invaluable, especially in satellite communications, where traditional optimization methods are often computationally intensive. AI-driven solutions offer faster, more effective ways to handle complex satellite communication tasks. Artificial intelligence in space has more constraints than other fields, considering the radiation effects, the spaceship power capabilities, mass, and area. Current onboard processing uses legacy space-certified general-purpose processors, costly application-specific integrated circuits, or field-programmable gate arrays subjected to a highly stringent certification process. The increased performance demands of onboard processors to satisfy the accelerated data rates and autonomy requirements have rendered current space-graded processors obsolete. This work is focused on transforming the satellite payload using artificial intelligence and machine learning methodologies over available commercial off-the-shelf chips for onboard processing. The objectives include validating artificial intelligence-driven scenarios, focusing on flexible payload and adaptive beamforming as machine learning models onboard. Results show that machine learning models significantly improve signal quality, spectral efficiency, and throughput compared to conventional payload.
Measured Hockey-Stick Divergence and its Applications to Quantum Pufferfish Privacy
Jan 21, 2025The hockey-stick divergence is a fundamental quantity characterizing several statistical privacy frameworks that ensure privacy for classical and quantum data. In such quantum privacy frameworks, the adversary is allowed to perform all possible measurements. However, in practice, there are typically limitations to the set of measurements that can be performed. To this end, here, we comprehensively analyze the measured hockey-stick divergence under several classes of practically relevant measurement classes. We prove several of its properties, including data processing and convexity. We show that it is efficiently computable by semi-definite programming for some classes of measurements and can be analytically evaluated for Werner and isotropic states. Notably, we show that the measured hockey-stick divergence characterizes optimal privacy parameters in the quantum pufferfish privacy framework. With this connection and the developed technical tools, we enable methods to quantify and audit privacy for several practically relevant settings. Lastly, we introduce the measured hockey-stick divergence of channels and explore its applications in ensuring privacy for channels.
Automated Extraction and Creation of FBS Design Reasoning Knowledge Graphs from Structured Data in Product Catalogues Lacking Contextual Information
Dec 08, 2024



Ontology-based knowledge graphs (KG) are desirable for effective knowledge management and reuse in various decision making scenarios, including design. Creating and populating extensive KG based on specific ontological models can be highly labour and time-intensive unless automated processes are developed for knowledge extraction and graph creation. Most research and development on automated extraction and creation of KG is based on extensive unstructured data sets that provide contextual information. However, some of the most useful information about the products and services of a company has traditionally been recorded as structured data. Such structured data sets rarely follow a standard ontology, do not capture explicit mapping of relationships between the entities, and provide no contextual information. Therefore, this research reports a method and digital workflow developed to address this gap. The developed method and workflow employ rule-based techniques to extract and create a Function Behaviour-Structure (FBS) ontology-based KG from legacy structured data, especially specification sheets and product catalogues. The solution approach consists of two main components: a process for deriving context and context-based classification rules for FBS ontology concepts and a workflow for populating and retrieving the FBS ontology-based KG. KG and Natural Language Processing (NLP) are used to automate knowledge extraction, representation, and retrieval. The workflow's effectiveness is demonstrated via pilot implementation in an industrial context. Insights gained from the pilot study are reported regarding the challenges and opportunities, including discussing the FBS ontology and concepts.
Artificial Intelligence Satellite Telecommunication Testbed using Commercial Off-The-Shelf Chipsets
May 28, 2024
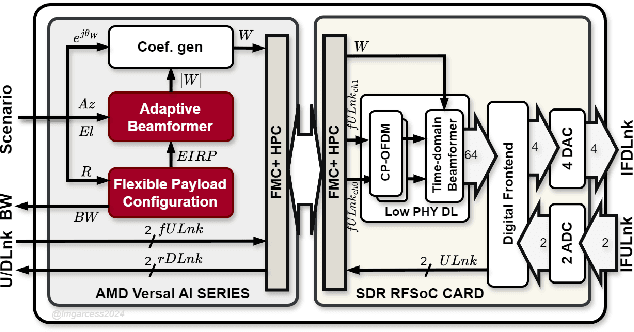
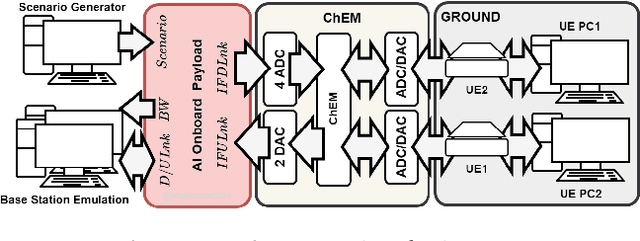

The Artificial Intelligence Satellite Telecommunications Testbed (AISTT), part of the ESA project SPAICE, is focused on the transformation of the satellite payload by using artificial intelligence (AI) and machine learning (ML) methodologies over available commercial off-the-shelf (COTS) AI chips for on-board processing. The objectives include validating artificial intelligence-driven SATCOM scenarios such as interference detection, spectrum sharing, radio resource management, decoding, and beamforming. The study highlights hardware selection and payload architecture. Preliminary results show that ML models significantly improve signal quality, spectral efficiency, and throughput compared to conventional payload. Moreover, the testbed aims to evaluate the performance and application of AI-capable COTS chips in onboard SATCOM contexts.
LeanAI: A method for AEC practitioners to effectively plan AI implementations
Jun 29, 2023
Recent developments in Artificial Intelligence (AI) provide unprecedented automation opportunities in the Architecture, Engineering, and Construction (AEC) industry. However, despite the enthusiasm regarding the use of AI, 85% of current big data projects fail. One of the main reasons for AI project failures in the AEC industry is the disconnect between those who plan or decide to use AI and those who implement it. AEC practitioners often lack a clear understanding of the capabilities and limitations of AI, leading to a failure to distinguish between what AI should solve, what it can solve, and what it will solve, treating these categories as if they are interchangeable. This lack of understanding results in the disconnect between AI planning and implementation because the planning is based on a vision of what AI should solve without considering if it can or will solve it. To address this challenge, this work introduces the LeanAI method. The method has been developed using data from several ongoing longitudinal studies analyzing AI implementations in the AEC industry, which involved 50+ hours of interview data. The LeanAI method delineates what AI should solve, what it can solve, and what it will solve, forcing practitioners to clearly articulate these components early in the planning process itself by involving the relevant stakeholders. By utilizing the method, practitioners can effectively plan AI implementations, thus increasing the likelihood of success and ultimately speeding up the adoption of AI. A case example illustrates the usefulness of the method.
Digital Twin: Where do humans fit in?
Jan 08, 2023Digital Twin (DT) technology is far from being comprehensive and mature, resulting in their piecemeal implementation in practice where some functions are automated by DTs, and others are still performed by humans. This piecemeal implementation of DTs often leaves practitioners wondering what roles (or functions) to allocate to DTs in a work system, and how might it impact humans. A lack of knowledge about the roles that humans and DTs play in a work system can result in significant costs, misallocation of resources, unrealistic expectations from DTs, and strategic misalignments. To alleviate this challenge, this paper answers the research question: When humans work with DTs, what types of roles can a DT play, and to what extent can those roles be automated? Specifically, we propose a two-dimensional conceptual framework, Levels of Digital Twin (LoDT). The framework is an integration of the types of roles a DT can play, broadly categorized under (1) Observer, (2) Analyst, (3) Decision Maker, and (4) Action Executor, and the extent of automation for each of these roles, divided into five different levels ranging from completely manual to fully automated. A particular DT can play any number of roles at varying levels. The framework can help practitioners systematically plan DT deployments, clearly communicate goals and deliverables, and lay out a strategic vision. A case study illustrates the usefulness of the framework.
A new perspective on Digital Twins: Imparting intelligence and agency to entities
Oct 11, 2022

Despite the Digital Twin (DT) concept being in the industry for a long time, it remains ambiguous, unable to differentiate itself from information models, general computing, and simulation technologies. Part of this confusion stems from previous studies overlooking the DT's bidirectional nature, that enables the shift of agency (delegating control) from humans to physical elements, something that was not possible with earlier technologies. Thus, we present DTs in a new light by viewing them as a means of imparting intelligence and agency to entities, emphasizing that DTs are not just expert-centric tools but are active systems that extend the capabilities of the entities being twinned. This new perspective on DTs can help reduce confusion and humanize the concept by starting discussions about how intelligent a DT should be, and its roles and responsibilities, as well as setting a long-term direction for DTs.
End-to-end deep learning for directly estimating grape yield from ground-based imagery
Aug 04, 2022



Yield estimation is a powerful tool in vineyard management, as it allows growers to fine-tune practices to optimize yield and quality. However, yield estimation is currently performed using manual sampling, which is time-consuming and imprecise. This study demonstrates the application of proximal imaging combined with deep learning for yield estimation in vineyards. Continuous data collection using a vehicle-mounted sensing kit combined with collection of ground truth yield data at harvest using a commercial yield monitor allowed for the generation of a large dataset of 23,581 yield points and 107,933 images. Moreover, this study was conducted in a mechanically managed commercial vineyard, representing a challenging environment for image analysis but a common set of conditions in the California Central Valley. Three model architectures were tested: object detection, CNN regression, and transformer models. The object detection model was trained on hand-labeled images to localize grape bunches, and either bunch count or pixel area was summed to correlate with grape yield. Conversely, regression models were trained end-to-end to predict grape yield from image data without the need for hand labeling. Results demonstrated that both a transformer as well as the object detection model with pixel area processing performed comparably, with a mean absolute percent error of 18% and 18.5%, respectively on a representative holdout dataset. Saliency mapping was used to demonstrate the attention of the CNN model was localized near the predicted location of grape bunches, as well as on the top of the grapevine canopy. Overall, the study showed the applicability of proximal imaging and deep learning for prediction of grapevine yield on a large scale. Additionally, the end-to-end modeling approach was able to perform comparably to the object detection approach while eliminating the need for hand-labeling.
Digital Twin: From Concept to Practice
Jan 14, 2022



Recent technological developments and advances in Artificial Intelligence (AI) have enabled sophisticated capabilities to be a part of Digital Twin (DT), virtually making it possible to introduce automation into all aspects of work processes. Given these possibilities that DT can offer, practitioners are facing increasingly difficult decisions regarding what capabilities to select while deploying a DT in practice. The lack of research in this field has not helped either. It has resulted in the rebranding and reuse of emerging technological capabilities like prediction, simulation, AI, and Machine Learning (ML) as necessary constituents of DT. Inappropriate selection of capabilities in a DT can result in missed opportunities, strategic misalignments, inflated expectations, and risk of it being rejected as just hype by the practitioners. To alleviate this challenge, this paper proposes the digitalization framework, designed and developed by following a Design Science Research (DSR) methodology over a period of 18 months. The framework can help practitioners select an appropriate level of sophistication in a DT by weighing the pros and cons for each level, deciding evaluation criteria for the digital twin system, and assessing the implications of the selected DT on the organizational processes and strategies, and value creation. Three real-life case studies illustrate the application and usefulness of the framework.