 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroupMixNorm Layer for Learning Fair Models
Dec 19, 2023Recent research has identified discriminatory behavior of automated prediction algorithms towards groups identified on specific protected attributes (e.g., gender, ethnicity, age group, etc.). When deployed in real-world scenarios, such techniques may demonstrate biased predictions resulting in unfair outcomes. Recent literature has witnessed algorithms for mitigating such biased behavior mostly by adding convex surrogates of fairness metrics such as demographic parity or equalized odds in the loss function, which are often not easy to estimate. This research proposes a novel in-processing based GroupMixNorm layer for mitigating bias from deep learning models. The GroupMixNorm layer probabilistically mixes group-level feature statistics of samples across different groups based on the protected attribute. The proposed method improves upon several fairness metrics with minimal impact on overall accuracy. Analysis on benchmark tabular and image datasets demonstrates the efficacy of the proposed method in achieving state-of-the-art performance. Further, the experimental analysis also suggests the robustness of the GroupMixNorm layer against new protected attributes during inference and its utility in eliminating bias from a pre-trained network.
Morality-based Assertion and Homophily on Social Media: A Cultural Comparison between English and Japanese Languages
Aug 24, 2021

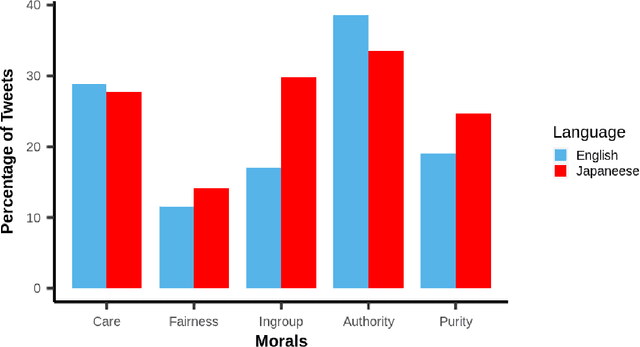

Moral psychology is a domain that deals with moral identity, appraisals and emotions. Previous work has greatly focused on moral development and the associated role of culture. Knowing that language is an inherent element of a culture, we used the social media platform Twitter for comparing the moral behaviors of Japanese users with English users. The five basic moral foundations i.e., Care, Fairness, Ingroup, Authority and Purity, along with the associated emotional valence are compared for English and Japanese tweets. The tweets from Japanese users depicted relatively higher Fairness, Ingroup and Purity. As far as emotions related to morality are concerned, the English tweets expressed more positive emotions for all moral dimensions. Considering the role of moral similarities in connecting users on social media, we quantified homophily concerning different moral dimensions using our proposed method. The moral dimensions Care, Authority and Purity for English and Ingroup for Japanese depicted homophily on Twitter. Overall, our study uncovers the underlying cultural differences with respect to moral behavior in English and Japanese speaking users.
Semi-supervised Learning for Marked Temporal Point Processes
Jul 16, 2021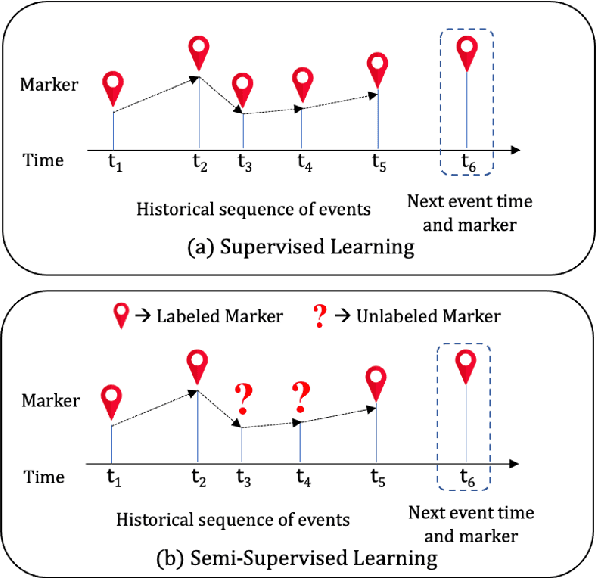
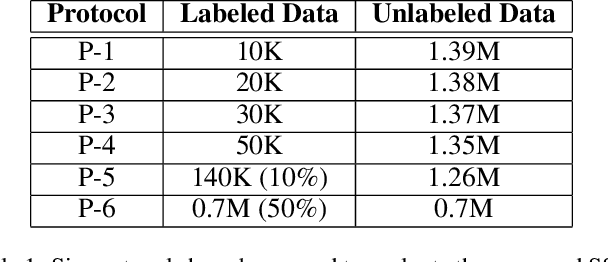
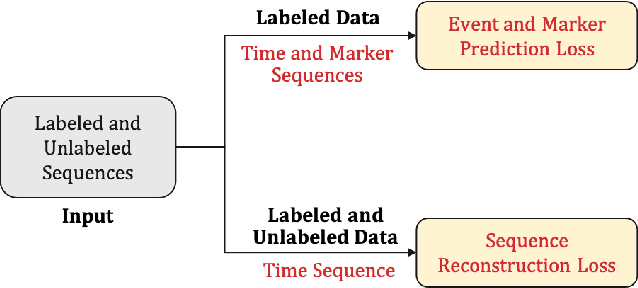
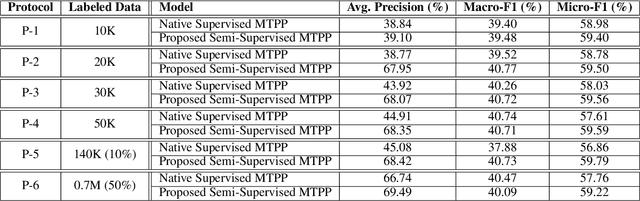
Temporal Point Processes (TPPs) are often used to represent the sequence of events ordered as per the time of occurrence. Owing to their flexible nature, TPPs have been used to model different scenarios and have shown applicability in various real-world applications. While TPPs focus on modeling the event occurrence, Marked Temporal Point Process (MTPP) focuses on modeling the category/class of the event as well (termed as the marker). Research in MTPP has garnered substantial attention over the past few years, with an extensive focus on supervised algorithms. Despite the research focus, limited attention has been given to the challenging problem of developing solutions in semi-supervised settings, where algorithms have access to a mix of labeled and unlabeled data. This research proposes a novel algorithm for Semi-supervised Learning for Marked Temporal Point Processes (SSL-MTPP) applicable in such scenarios. The proposed SSL-MTPP algorithm utilizes a combination of labeled and unlabeled data for learning a robust marker prediction model. The proposed algorithm utilizes an RNN-based Encoder-Decoder module for learning effective representations of the time sequence. The efficacy of the proposed algorithm has been demonstrated via multiple protocols on the Retweet dataset, where the proposed SSL-MTPP demonstrates improved performance in comparison to the traditional supervised learning approach.
Enhancing Fine-Grained Classification for Low Resolution Images
May 01, 2021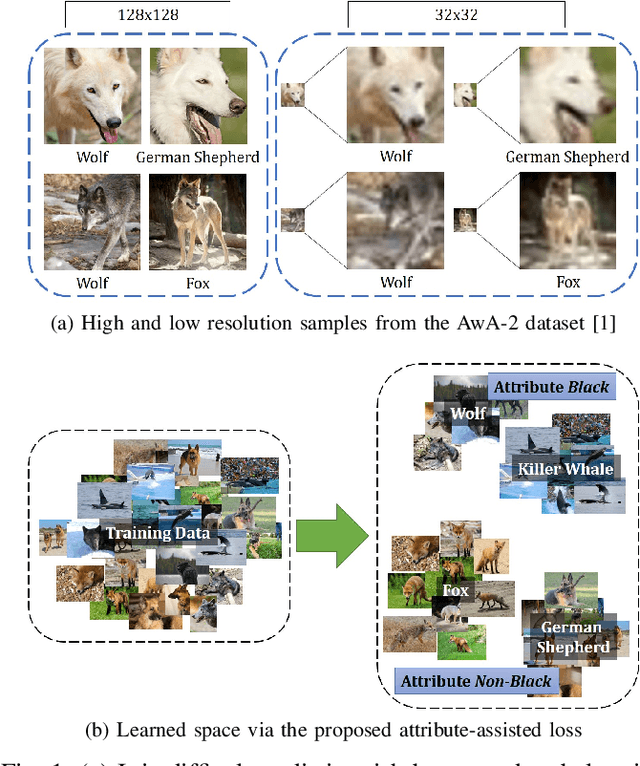
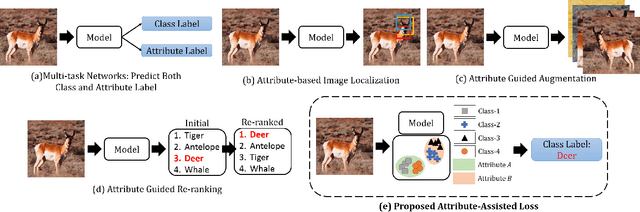

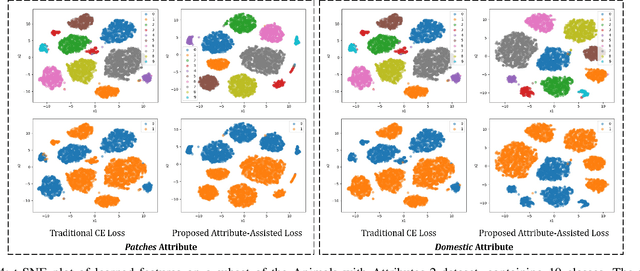
Low resolution fine-grained classification has widespread applicability for applications where data is captured at a distance such as surveillance and mobile photography. While fine-grained classification with high resolution images has received significant attention, limited attention has been given to low resolution images. These images suffer from the inherent challenge of limited information content and the absence of fine details useful for sub-category classification. This results in low inter-class variations across samples of visually similar classes. In order to address these challenges, this research proposes a novel attribute-assisted loss, which utilizes ancillary information to learn discriminative features for classification. The proposed loss function enables a model to learn class-specific discriminative features, while incorporating attribute-level separability. Evaluation is performed on multiple datasets with different models, for four resolutions varying from 32x32 to 224x224. Different experiments demonstrate the efficacy of the proposed attributeassisted loss for low resolution fine-grained classification.
On the Robustness of Face Recognition Algorithms Against Attacks and Bias
Feb 07, 2020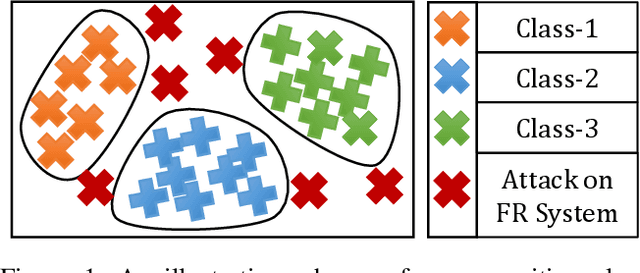



Face recognition algorithms have demonstrated very high recognition performance, suggesting suitability for real world applications. Despite the enhanced accuracies, robustness of these algorithms against attacks and bias has been challenged. This paper summarizes different ways in which the robustness of a face recognition algorithm is challenged, which can severely affect its intended working. Different types of attacks such as physical presentation attacks, disguise/makeup, digital adversarial attacks, and morphing/tampering using GANs have been discussed. We also present a discussion on the effect of bias on face recognition models and showcase that factors such as age and gender variations affect the performance of modern algorithms. The paper also presents the potential reasons for these challenges and some of the future research directions for increasing the robustness of face recognition models.
Dual Directed Capsule Network for Very Low Resolution Image Recognition
Aug 27, 2019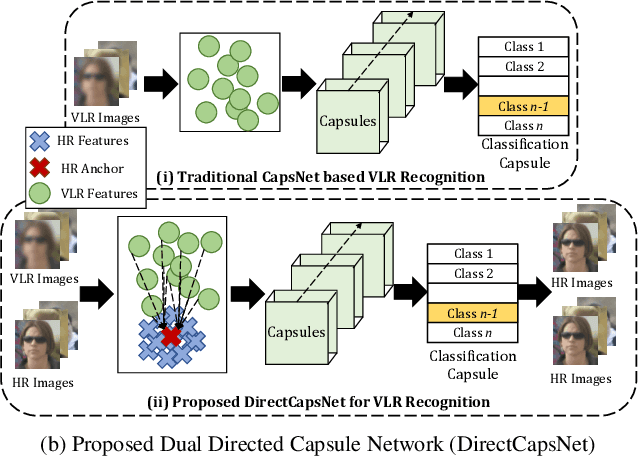
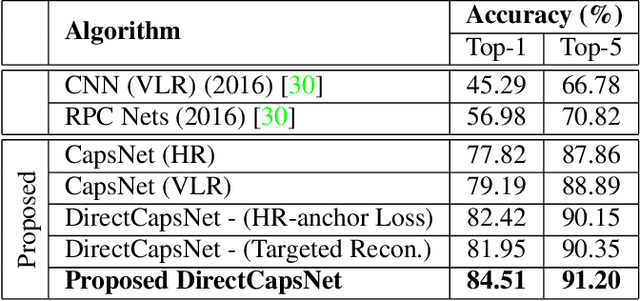

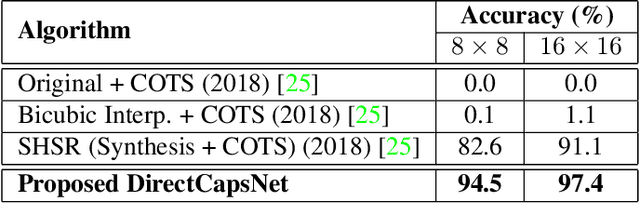
Very low resolution (VLR) image recognition corresponds to classifying images with resolution 16x16 or less. Though it has widespread applicability when objects are captured at a very large stand-off distance (e.g. surveillance scenario) or from wide angle mobile cameras, it has received limited attention. This research presents a novel Dual Directed Capsule Network model, termed as DirectCapsNet, for addressing VLR digit and face recognition. The proposed architecture utilizes a combination of capsule and convolutional layers for learning an effective VLR recognition model. The architecture also incorporates two novel loss functions: (i) the proposed HR-anchor loss and (ii) the proposed targeted reconstruction loss, in order to overcome the challenges of limited information content in VLR images. The proposed losses use high resolution images as auxiliary data during training to "direct" discriminative feature learning. Multiple experiments for VLR digit classification and VLR face recognition are performed along with comparisons with state-of-the-art algorithms. The proposed DirectCapsNet consistently showcases state-of-the-art results; for example, on the UCCS face database, it shows over 95\% face recognition accuracy when 16x16 images are matched with 80x80 images.
Deep Learning for Face Recognition: Pride or Prejudiced?
Apr 02, 2019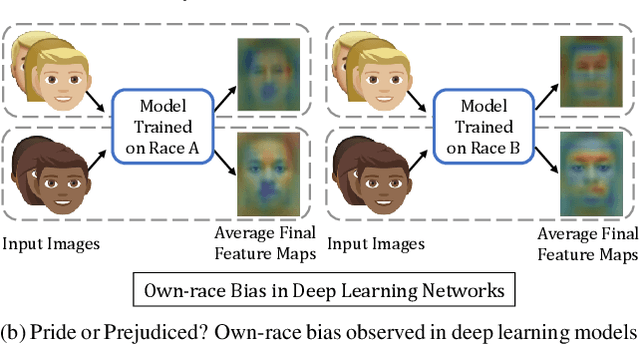
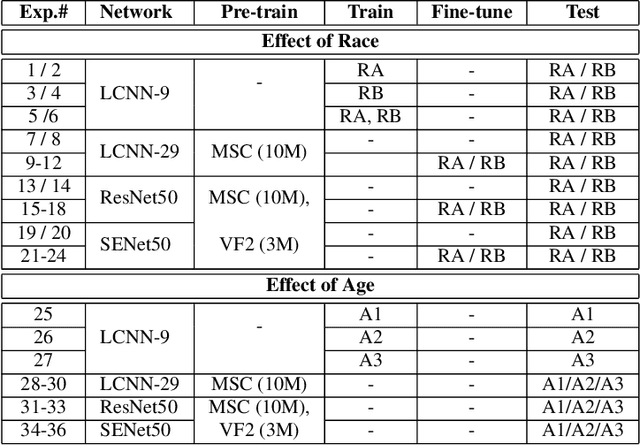


Do very high accuracies of deep networks suggest pride of effective AI or are deep networks prejudiced? Do they suffer from in-group biases (own-race-bias and own-age-bias), and mimic the human behavior? Is in-group specific information being encoded sub-consciously by the deep networks? This research attempts to answer these questions and presents an in-depth analysis of `bias' in deep learning based face recognition systems. This is the first work which decodes if and where bias is encoded for face recognition. Taking cues from cognitive studies, we inspect if deep networks are also affected by social in- and out-group effect. Networks are analyzed for own-race and own-age bias, both of which have been well established in human beings. The sub-conscious behavior of face recognition models is examined to understand if they encode race or age specific features for face recognition. Analysis is performed based on 36 experiments conducted on multiple datasets. Four deep learning networks either trained from scratch or pre-trained on over 10M images are used. Variations across class activation maps and feature visualizations provide novel insights into the functioning of deep learning systems, suggesting behavior similar to humans. It is our belief that a better understanding of state-of-the-art deep learning networks would enable researchers to address the given challenge of bias in AI, and develop fairer systems.
A Comprehensive Overview of Biometric Fusion
Feb 08, 2019
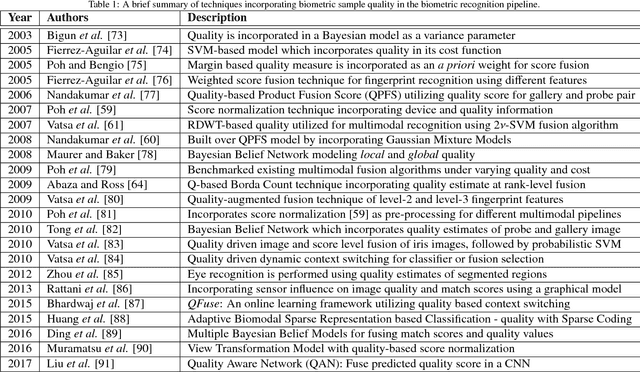
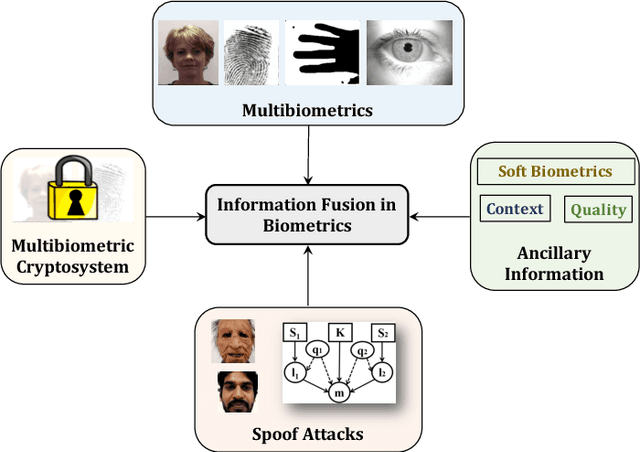
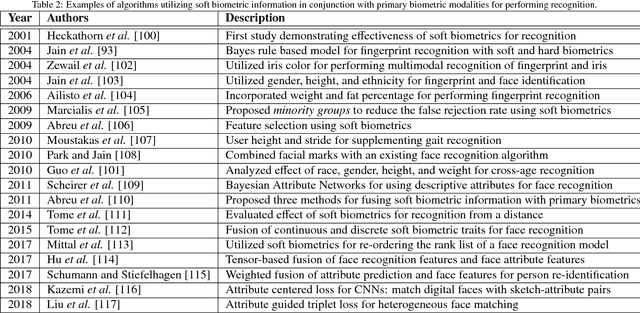
The performance of a biometric system that relies on a single biometric modality (e.g., fingerprints only) is often stymied by various factors such as poor data quality or limited scalability. Multibiometric systems utilize the principle of fusion to combine information from multiple sources in order to improve recognition accuracy whilst addressing some of the limitations of single-biometric systems. The past two decades have witnessed the development of a large number of biometric fusion schemes. This paper presents an overview of biometric fusion with specific focus on three questions: what to fuse, when to fuse, and how to fuse. A comprehensive review of techniques incorporating ancillary information in the biometric recognition pipeline is also presented. In this regard, the following topics are discussed: (i) incorporating data quality in the biometric recognition pipeline; (ii) combining soft biometric attributes with primary biometric identifiers; (iii) utilizing contextual information to improve biometric recognition accuracy; and (iv) performing continuous authentication using ancillary information. In addition, the use of information fusion principles for presentation attack detection and multibiometric cryptosystems is also discussed. Finally, some of the research challenges in biometric fusion are enumerated. The purpose of this article is to provide readers a comprehensive overview of the role of information fusion in biometrics.
Recognizing Disguised Faces in the Wild
Nov 21, 2018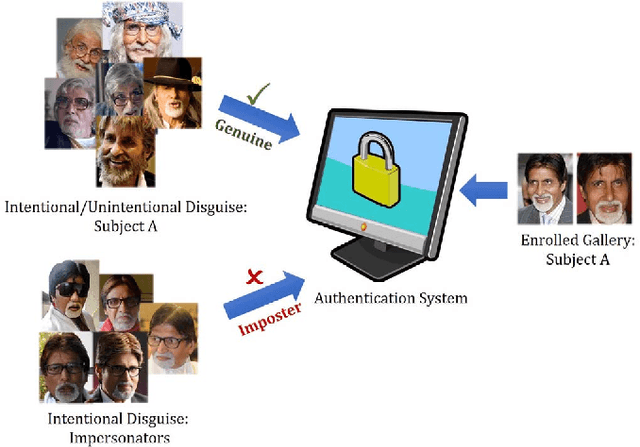

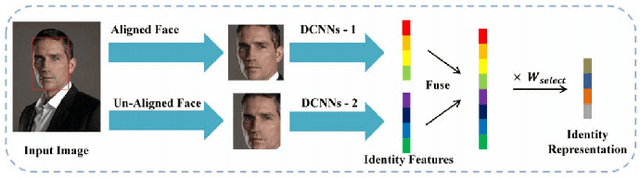
Research in face recognition has seen tremendous growth over the past couple of decades. Beginning from algorithms capable of performing recognition in constrained environments, the current face recognition systems achieve very high accuracies on large-scale unconstrained face datasets. While upcoming algorithms continue to achieve improved performance, a majority of the face recognition systems are susceptible to failure under disguise variations, one of the most challenging covariate of face recognition. Most of the existing disguise datasets contain images with limited variations, often captured in controlled settings. This does not simulate a real world scenario, where both intentional and unintentional unconstrained disguises are encountered by a face recognition system. In this paper, a novel Disguised Faces in the Wild (DFW) dataset is proposed which contains over 11000 images of 1000 identities with different types of disguise accessories. The dataset is collected from the Internet, resulting in unconstrained face images similar to real world settings. This is the first-of-a-kind dataset with the availability of impersonator and genuine obfuscated face images for each subject. The proposed dataset has been analyzed in terms of three levels of difficulty: (i) easy, (ii) medium, and (iii) hard in order to showcase the challenging nature of the problem. It is our view that the research community can greatly benefit from the DFW dataset in terms of developing algorithms robust to such adversaries. The proposed dataset was released as part of the First International Workshop and Competition on Disguised Faces in the Wild at CVPR, 2018. This paper presents the DFW dataset in detail, including the evaluation protocols, baseline results, performance analysis of the submissions received as part of the competition, and three levels of difficulties of the DFW challenge dataset.
Supervised COSMOS Autoencoder: Learning Beyond the Euclidean Loss!
Oct 15, 2018

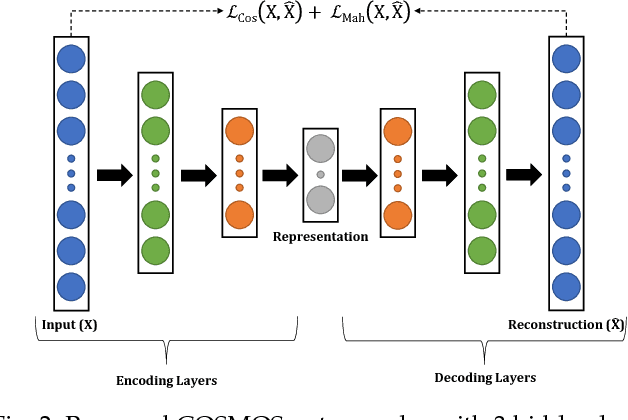
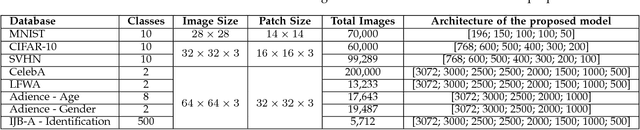
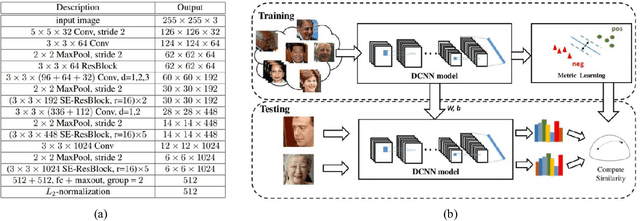
Autoencoders are unsupervised deep learning models used for learning representations. In literature, autoencoders have shown to perform well on a variety of tasks spread across multiple domains, thereby establishing widespread applicability. Typically, an autoencoder is trained to generate a model that minimizes the reconstruction error between the input and the reconstructed output, computed in terms of the Euclidean distance. While this can be useful for applications related to unsupervised reconstruction, it may not be optimal for classification. In this paper, we propose a novel Supervised COSMOS Autoencoder which utilizes a multi-objective loss function to learn representations that simultaneously encode the (i) "similarity" between the input and reconstructed vectors in terms of their direction, (ii) "distribution" of pixel values of the reconstruction with respect to the input sample, while also incorporating (iii) "discriminability" in the feature learning pipeline. The proposed autoencoder model incorporates a Cosine similarity and Mahalanobis distance based loss function, along with supervision via Mutual Information based loss. Detailed analysis of each component of the proposed model motivates its applicability for feature learning in different classification tasks. The efficacy of Supervised COSMOS autoencoder is demonstrated via extensive experimental evaluations on different image datasets. The proposed model outperforms existing algorithms on MNIST, CIFAR-10, and SVHN databases. It also yields state-of-the-art results on CelebA, LFWA, Adience, and IJB-A databases for attribute prediction and face recognition, respectively.