 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAge Gap Reducer-GAN for Recognizing Age-Separated Faces
Nov 11, 2020



In this paper, we propose a novel algorithm for matching faces with temporal variations caused due to age progression. The proposed generative adversarial network algorithm is a unified framework that combines facial age estimation and age-separated face verification. The key idea of this approach is to learn the age variations across time by conditioning the input image on the subject's gender and the target age group to which the face needs to be progressed. The loss function accounts for reducing the age gap between the original image and generated face image as well as preserving the identity. Both visual fidelity and quantitative evaluations demonstrate the efficacy of the proposed architecture on different facial age databases for age-separated face recognition.
Supervised COSMOS Autoencoder: Learning Beyond the Euclidean Loss!
Oct 15, 2018

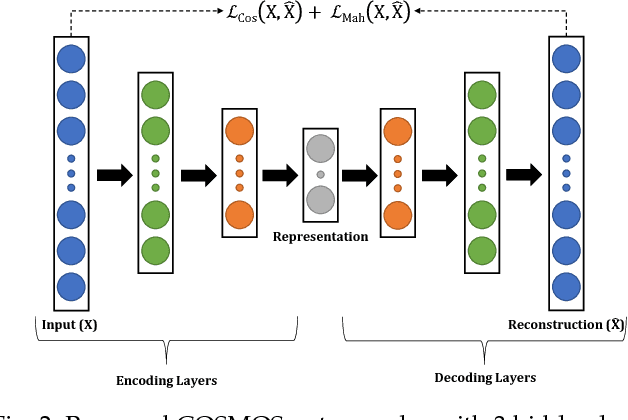
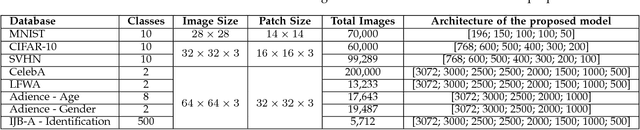
Autoencoders are unsupervised deep learning models used for learning representations. In literature, autoencoders have shown to perform well on a variety of tasks spread across multiple domains, thereby establishing widespread applicability. Typically, an autoencoder is trained to generate a model that minimizes the reconstruction error between the input and the reconstructed output, computed in terms of the Euclidean distance. While this can be useful for applications related to unsupervised reconstruction, it may not be optimal for classification. In this paper, we propose a novel Supervised COSMOS Autoencoder which utilizes a multi-objective loss function to learn representations that simultaneously encode the (i) "similarity" between the input and reconstructed vectors in terms of their direction, (ii) "distribution" of pixel values of the reconstruction with respect to the input sample, while also incorporating (iii) "discriminability" in the feature learning pipeline. The proposed autoencoder model incorporates a Cosine similarity and Mahalanobis distance based loss function, along with supervision via Mutual Information based loss. Detailed analysis of each component of the proposed model motivates its applicability for feature learning in different classification tasks. The efficacy of Supervised COSMOS autoencoder is demonstrated via extensive experimental evaluations on different image datasets. The proposed model outperforms existing algorithms on MNIST, CIFAR-10, and SVHN databases. It also yields state-of-the-art results on CelebA, LFWA, Adience, and IJB-A databases for attribute prediction and face recognition, respectively.
Learning A Shared Transform Model for Skull to Digital Face Image Matching
Aug 14, 2018
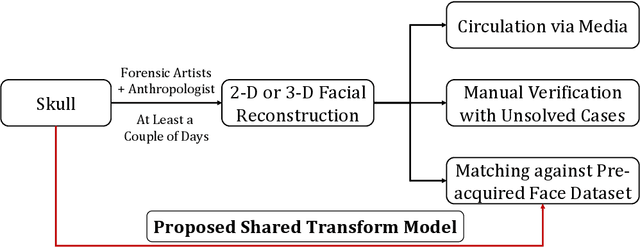
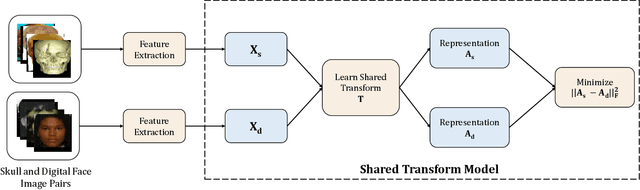
Human skull identification is an arduous task, traditionally requiring the expertise of forensic artists and anthropologists. This paper is an effort to automate the process of matching skull images to digital face images, thereby establishing an identity of the skeletal remains. In order to achieve this, a novel Shared Transform Model is proposed for learning discriminative representations. The model learns robust features while reducing the intra-class variations between skulls and digital face images. Such a model can assist law enforcement agencies by speeding up the process of skull identification, and reducing the manual load. Experimental evaluation performed on two pre-defined protocols of the publicly available IdentifyMe dataset demonstrates the efficacy of the proposed model.
Supervised Mixed Norm Autoencoder for Kinship Verification in Unconstrained Videos
May 30, 2018



Identifying kinship relations has garnered interest due to several applications such as organizing and tagging the enormous amount of videos being uploaded on the Internet. Existing research in kinship verification primarily focuses on kinship prediction with image pairs. In this research, we propose a new deep learning framework for kinship verification in unconstrained videos using a novel Supervised Mixed Norm regularization Autoencoder (SMNAE). This new autoencoder formulation introduces class-specific sparsity in the weight matrix. The proposed three-stage SMNAE based kinship verification framework utilizes the learned spatio-temporal representation in the video frames for verifying kinship in a pair of videos. A new kinship video (KIVI) database of more than 500 individuals with variations due to illumination, pose, occlusion, ethnicity, and expression is collected for this research. It comprises a total of 355 true kin video pairs with over 250,000 still frames. The effectiveness of the proposed framework is demonstrated on the KIVI database and six existing kinship databases. On the KIVI database, SMNAE yields video-based kinship verification accuracy of 83.18% which is at least 3.2% better than existing algorithms. The algorithm is also evaluated on six publicly available kinship databases and compared with best-reported results. It is observed that the proposed SMNAE consistently yields best results on all the databases
Hierarchical Representation Learning for Kinship Verification
May 27, 2018



Kinship verification has a number of applications such as organizing large collections of images and recognizing resemblances among humans. In this research, first, a human study is conducted to understand the capabilities of human mind and to identify the discriminatory areas of a face that facilitate kinship-cues. Utilizing the information obtained from the human study, a hierarchical Kinship Verification via Representation Learning (KVRL) framework is utilized to learn the representation of different face regions in an unsupervised manner. We propose a novel approach for feature representation termed as filtered contractive deep belief networks (fcDBN). The proposed feature representation encodes relational information present in images using filters and contractive regularization penalty. A compact representation of facial images of kin is extracted as an output from the learned model and a multi-layer neural network is utilized to verify the kin accurately. A new WVU Kinship Database is created which consists of multiple images per subject to facilitate kinship verification. The results show that the proposed deep learning framework (KVRL-fcDBN) yields stateof-the-art kinship verification accuracy on the WVU Kinship database and on four existing benchmark datasets. Further, kinship information is used as a soft biometric modality to boost the performance of face verification via product of likelihood ratio and support vector machine based approaches. Using the proposed KVRL-fcDBN framework, an improvement of over 20% is observed in the performance of face verification.
Learning Structure and Strength of CNN Filters for Small Sample Size Training
Mar 30, 2018


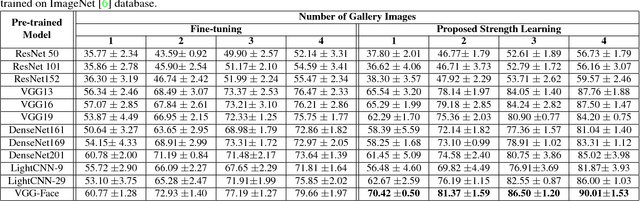
Convolutional Neural Networks have provided state-of-the-art results in several computer vision problems. However, due to a large number of parameters in CNNs, they require a large number of training samples which is a limiting factor for small sample size problems. To address this limitation, we propose SSF-CNN which focuses on learning the structure and strength of filters. The structure of the filter is initialized using a dictionary-based filter learning algorithm and the strength of the filter is learned using the small sample training data. The architecture provides the flexibility of training with both small and large training databases and yields good accuracies even with small size training data. The effectiveness of the algorithm is first demonstrated on MNIST, CIFAR10, and NORB databases, with a varying number of training samples. The results show that SSF-CNN significantly reduces the number of parameters required for training while providing high accuracies the test databases. On small sample size problems such as newborn face recognition and Omniglot, it yields state-of-the-art results. Specifically, on the IIITD Newborn Face Database, the results demonstrate improvement in rank-1 identification accuracy by at least 10%.
Synthetic Iris Presentation Attack using iDCGAN
Oct 29, 2017



Reliability and accuracy of iris biometric modality has prompted its large-scale deployment for critical applications such as border control and national ID projects. The extensive growth of iris recognition systems has raised apprehensions about susceptibility of these systems to various attacks. In the past, researchers have examined the impact of various iris presentation attacks such as textured contact lenses and print attacks. In this research, we present a novel presentation attack using deep learning based synthetic iris generation. Utilizing the generative capability of deep convolutional generative adversarial networks and iris quality metrics, we propose a new framework, named as iDCGAN (iris deep convolutional generative adversarial network) for generating realistic appearing synthetic iris images. We demonstrate the effect of these synthetically generated iris images as presentation attack on iris recognition by using a commercial system. The state-of-the-art presentation attack detection framework, DESIST is utilized to analyze if it can discriminate these synthetically generated iris images from real images. The experimental results illustrate that mitigating the proposed synthetic presentation attack is of paramount importance.
Face Sketch Matching via Coupled Deep Transform Learning
Oct 09, 2017
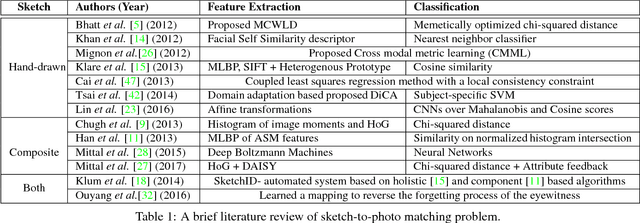

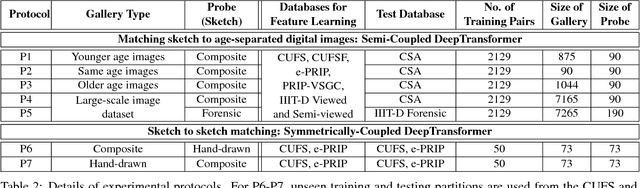
Face sketch to digital image matching is an important challenge of face recognition that involves matching across different domains. Current research efforts have primarily focused on extracting domain invariant representations or learning a mapping from one domain to the other. In this research, we propose a novel transform learning based approach termed as DeepTransformer, which learns a transformation and mapping function between the features of two domains. The proposed formulation is independent of the input information and can be applied with any existing learned or hand-crafted feature. Since the mapping function is directional in nature, we propose two variants of DeepTransformer: (i) semi-coupled and (ii) symmetrically-coupled deep transform learning. This research also uses a novel IIIT-D Composite Sketch with Age (CSA) variations database which contains sketch images of 150 subjects along with age-separated digital photos. The performance of the proposed models is evaluated on a novel application of sketch-to-sketch matching, along with sketch-to-digital photo matching. Experimental results demonstrate the robustness of the proposed models in comparison to existing state-of-the-art sketch matching algorithms and a commercial face recognition system.
On Matching Skulls to Digital Face Images: A Preliminary Approach
Oct 08, 2017
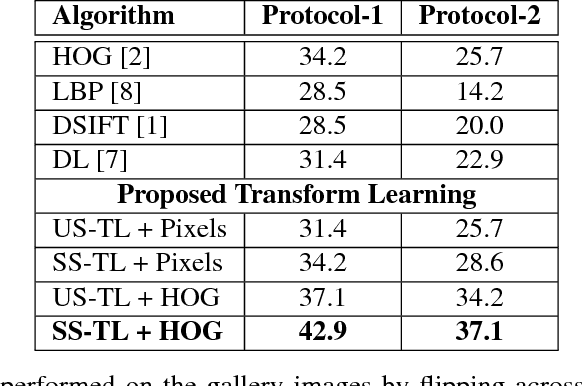
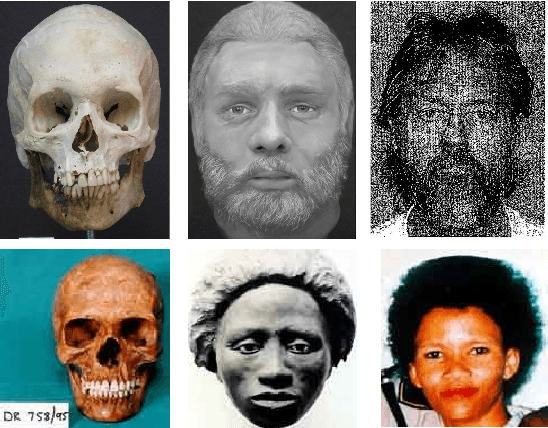

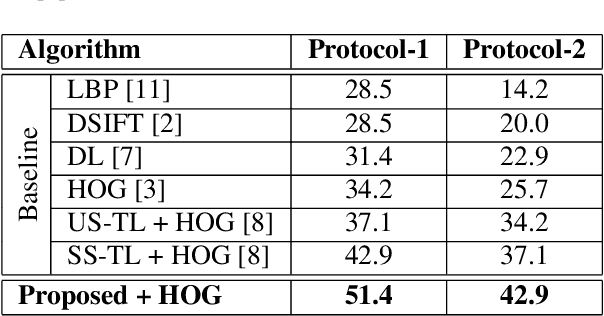
Forensic application of automatically matching skull with face images is an important research area linking biometrics with practical applications in forensics. It is an opportunity for biometrics and face recognition researchers to help the law enforcement and forensic experts in giving an identity to unidentified human skulls. It is an extremely challenging problem which is further exacerbated due to lack of any publicly available database related to this problem. This is the first research in this direction with a two-fold contribution: (i) introducing the first of its kind skull-face image pair database, IdentifyMe, and (ii) presenting a preliminary approach using the proposed semi-supervised formulation of transform learning. The experimental results and comparison with existing algorithms showcase the challenging nature of the problem. We assert that the availability of the database will inspire researchers to build sophisticated skull-to-face matching algorithms.
Gender and Ethnicity Classification of Iris Images using Deep Class-Encoder
Oct 08, 2017

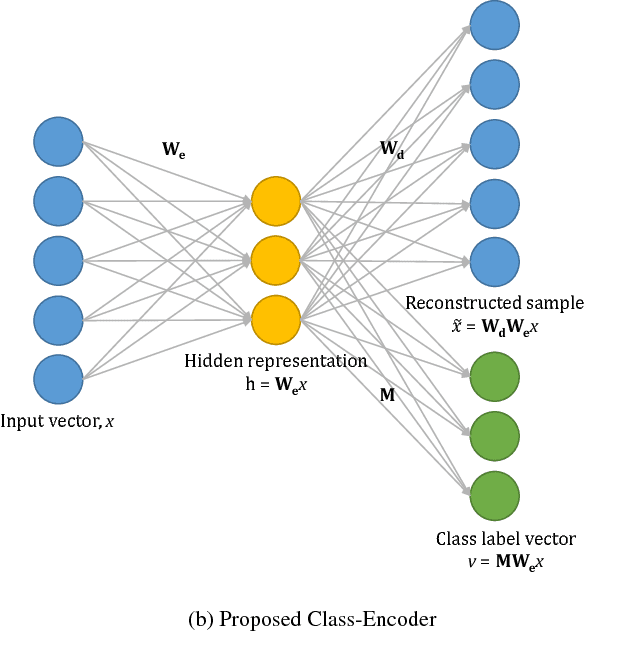

Soft biometric modalities have shown their utility in different applications including reducing the search space significantly. This leads to improved recognition performance, reduced computation time, and faster processing of test samples. Some common soft biometric modalities are ethnicity, gender, age, hair color, iris color, presence of facial hair or moles, and markers. This research focuses on performing ethnicity and gender classification on iris images. We present a novel supervised autoencoder based approach, Deep Class-Encoder, which uses class labels to learn discriminative representation for the given sample by mapping the learned feature vector to its label. The proposed model is evaluated on two datasets each for ethnicity and gender classification. The results obtained using the proposed Deep Class-Encoder demonstrate its effectiveness in comparison to existing approaches and state-of-the-art methods.