 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised COSMOS Autoencoder: Learning Beyond the Euclidean Loss!
Paper and Code
Oct 15, 2018

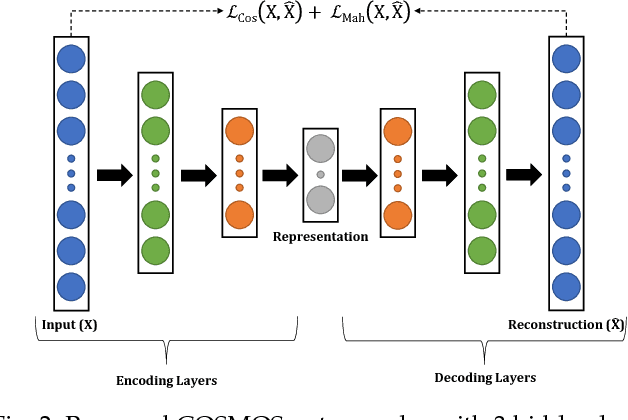
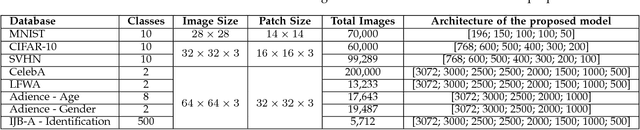
Autoencoders are unsupervised deep learning models used for learning representations. In literature, autoencoders have shown to perform well on a variety of tasks spread across multiple domains, thereby establishing widespread applicability. Typically, an autoencoder is trained to generate a model that minimizes the reconstruction error between the input and the reconstructed output, computed in terms of the Euclidean distance. While this can be useful for applications related to unsupervised reconstruction, it may not be optimal for classification. In this paper, we propose a novel Supervised COSMOS Autoencoder which utilizes a multi-objective loss function to learn representations that simultaneously encode the (i) "similarity" between the input and reconstructed vectors in terms of their direction, (ii) "distribution" of pixel values of the reconstruction with respect to the input sample, while also incorporating (iii) "discriminability" in the feature learning pipeline. The proposed autoencoder model incorporates a Cosine similarity and Mahalanobis distance based loss function, along with supervision via Mutual Information based loss. Detailed analysis of each component of the proposed model motivates its applicability for feature learning in different classification tasks. The efficacy of Supervised COSMOS autoencoder is demonstrated via extensive experimental evaluations on different image datasets. The proposed model outperforms existing algorithms on MNIST, CIFAR-10, and SVHN databases. It also yields state-of-the-art results on CelebA, LFWA, Adience, and IJB-A databases for attribute prediction and face recognition, respectively.