 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Bias Mitigation through Proxy Sensitive Attribute Label Generation
Dec 26, 2023Addressing bias in the trained machine learning system often requires access to sensitive attributes. In practice, these attributes are not available either due to legal and policy regulations or data unavailability for a given demographic. Existing bias mitigation algorithms are limited in their applicability to real-world scenarios as they require access to sensitive attributes to achieve fairness. In this research work, we aim to address this bottleneck through our proposed unsupervised proxy-sensitive attribute label generation technique. Towards this end, we propose a two-stage approach of unsupervised embedding generation followed by clustering to obtain proxy-sensitive labels. The efficacy of our work relies on the assumption that bias propagates through non-sensitive attributes that are correlated to the sensitive attributes and, when mapped to the high dimensional latent space, produces clusters of different demographic groups that exist in the data. Experimental results demonstrate that bias mitigation using existing algorithms such as Fair Mixup and Adversarial Debiasing yields comparable results on derived proxy labels when compared against using true sensitive attributes.
GroupMixNorm Layer for Learning Fair Models
Dec 19, 2023Recent research has identified discriminatory behavior of automated prediction algorithms towards groups identified on specific protected attributes (e.g., gender, ethnicity, age group, etc.). When deployed in real-world scenarios, such techniques may demonstrate biased predictions resulting in unfair outcomes. Recent literature has witnessed algorithms for mitigating such biased behavior mostly by adding convex surrogates of fairness metrics such as demographic parity or equalized odds in the loss function, which are often not easy to estimate. This research proposes a novel in-processing based GroupMixNorm layer for mitigating bias from deep learning models. The GroupMixNorm layer probabilistically mixes group-level feature statistics of samples across different groups based on the protected attribute. The proposed method improves upon several fairness metrics with minimal impact on overall accuracy. Analysis on benchmark tabular and image datasets demonstrates the efficacy of the proposed method in achieving state-of-the-art performance. Further, the experimental analysis also suggests the robustness of the GroupMixNorm layer against new protected attributes during inference and its utility in eliminating bias from a pre-trained network.
Transitioning from Real to Synthetic data: Quantifying the bias in model
May 10, 2021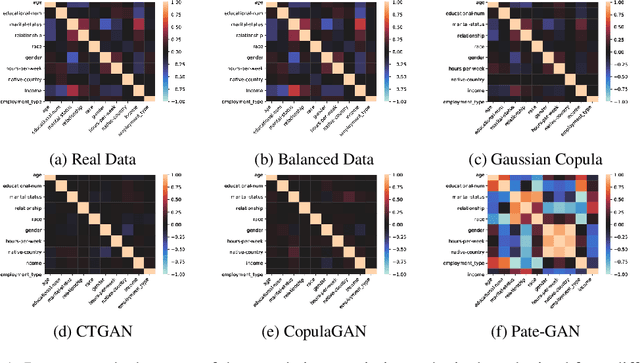
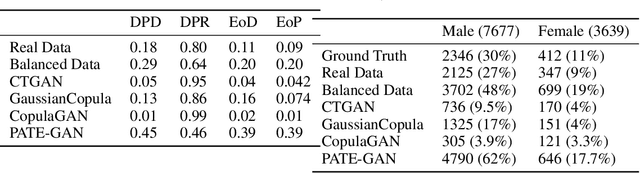
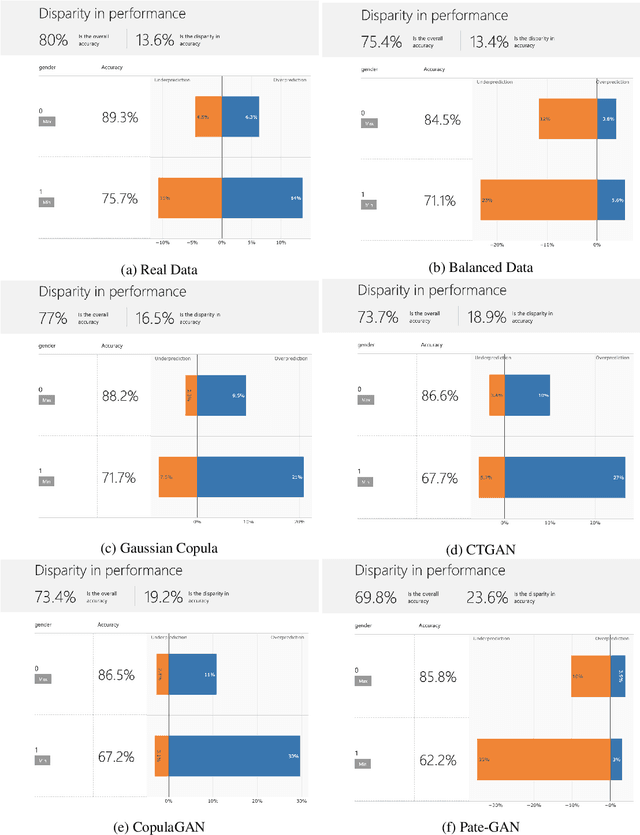
With the advent of generative modeling techniques, synthetic data and its use has penetrated across various domains from unstructured data such as image, text to structured dataset modeling healthcare outcome, risk decisioning in financial domain, and many more. It overcomes various challenges such as limited training data, class imbalance, restricted access to dataset owing to privacy issues. To ensure the trained model used for automated decisioning purposes makes a fair decision there exist prior work to quantify and mitigate those issues. This study aims to establish a trade-off between bias and fairness in the models trained using synthetic data. Variants of synthetic data generation techniques were studied to understand bias amplification including differentially private generation schemes. Through experiments on a tabular dataset, we demonstrate there exist a varying levels of bias impact on models trained using synthetic data. Techniques generating less correlated feature performs well as evident through fairness metrics with 94\%, 82\%, and 88\% relative drop in DPD (demographic parity difference), EoD (equality of odds) and EoP (equality of opportunity) respectively, and 24\% relative improvement in DRP (demographic parity ratio) with respect to the real dataset. We believe the outcome of our research study will help data science practitioners understand the bias in the use of synthetic data.