 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSinLlama -- A Large Language Model for Sinhala
Aug 12, 2025Low-resource languages such as Sinhala are often overlooked by open-source Large Language Models (LLMs). In this research, we extend an existing multilingual LLM (Llama-3-8B) to better serve Sinhala. We enhance the LLM tokenizer with Sinhala specific vocabulary and perform continual pre-training on a cleaned 10 million Sinhala corpus, resulting in the SinLlama model. This is the very first decoder-based open-source LLM with explicit Sinhala support. When SinLlama was instruction fine-tuned for three text classification tasks, it outperformed base and instruct variants of Llama-3-8B by a significant margin.
Leveraging Synthetic Data for Question Answering with Multilingual LLMs in the Agricultural Domain
Jul 22, 2025



Enabling farmers to access accurate agriculture-related information in their native languages in a timely manner is crucial for the success of the agriculture field. Although large language models (LLMs) can be used to implement Question Answering (QA) systems, simply using publicly available general-purpose LLMs in agriculture typically offer generic advisories, lacking precision in local and multilingual contexts due to insufficient domain-specific training and scarcity of high-quality, region-specific datasets. Our study addresses these limitations by generating multilingual synthetic agricultural datasets (English, Hindi, Punjabi) from agriculture-specific documents and fine-tuning language-specific LLMs. Our evaluation on curated multilingual datasets demonstrates significant improvements in factual accuracy, relevance, and agricultural consensus for the fine-tuned models compared to their baseline counterparts. These results highlight the efficacy of synthetic data-driven, language-specific fine-tuning as an effective strategy to improve the performance of LLMs in agriculture, especially in multilingual and low-resource settings. By enabling more accurate and localized agricultural advisory services, this study provides a meaningful step toward bridging the knowledge gap in AI-driven agricultural solutions for diverse linguistic communities.
Large Language Models for Ingredient Substitution in Food Recipes using Supervised Fine-tuning and Direct Preference Optimization
Dec 06, 2024



In this paper, we address the challenge of recipe personalization through ingredient substitution. We make use of Large Language Models (LLMs) to build an ingredient substitution system designed to predict plausible substitute ingredients within a given recipe context. Given that the use of LLMs for this task has been barely done, we carry out an extensive set of experiments to determine the best LLM, prompt, and the fine-tuning setups. We further experiment with methods such as multi-task learning, two-stage fine-tuning, and Direct Preference Optimization (DPO). The experiments are conducted using the publicly available Recipe1MSub corpus. The best results are produced by the Mistral7-Base LLM after fine-tuning and DPO. This result outperforms the strong baseline available for the same corpus with a Hit@1 score of 22.04. Thus we believe that this research represents a significant step towards enabling personalized and creative culinary experiences by utilizing LLM-based ingredient substitution.
Morality-based Assertion and Homophily on Social Media: A Cultural Comparison between English and Japanese Languages
Aug 24, 2021

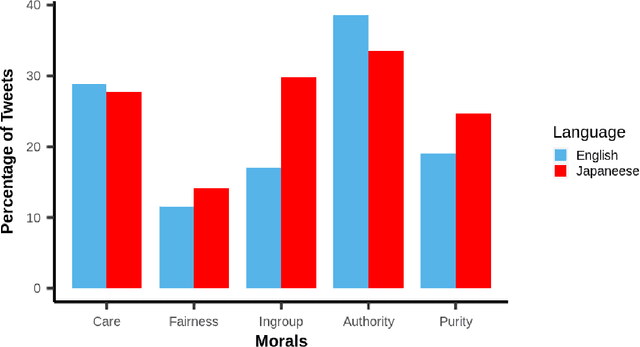

Moral psychology is a domain that deals with moral identity, appraisals and emotions. Previous work has greatly focused on moral development and the associated role of culture. Knowing that language is an inherent element of a culture, we used the social media platform Twitter for comparing the moral behaviors of Japanese users with English users. The five basic moral foundations i.e., Care, Fairness, Ingroup, Authority and Purity, along with the associated emotional valence are compared for English and Japanese tweets. The tweets from Japanese users depicted relatively higher Fairness, Ingroup and Purity. As far as emotions related to morality are concerned, the English tweets expressed more positive emotions for all moral dimensions. Considering the role of moral similarities in connecting users on social media, we quantified homophily concerning different moral dimensions using our proposed method. The moral dimensions Care, Authority and Purity for English and Ingroup for Japanese depicted homophily on Twitter. Overall, our study uncovers the underlying cultural differences with respect to moral behavior in English and Japanese speaking users.
What a million Indian farmers say?: A crowdsourcing-based method for pest surveillance
Aug 07, 2021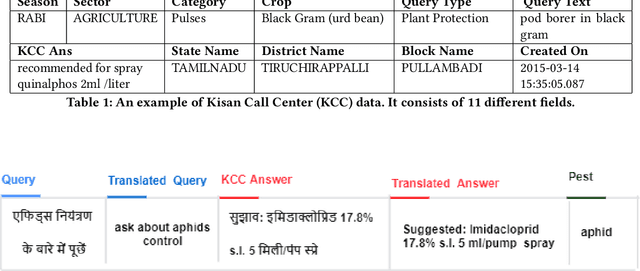


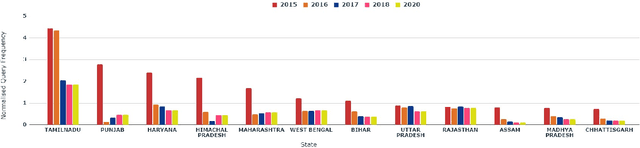
Many different technologies are used to detect pests in the crops, such as manual sampling, sensors, and radar. However, these methods have scalability issues as they fail to cover large areas, are uneconomical and complex. This paper proposes a crowdsourced based method utilising the real-time farmer queries gathered over telephones for pest surveillance. We developed data-driven strategies by aggregating and analyzing historical data to find patterns and get future insights into pest occurrence. We showed that it can be an accurate and economical method for pest surveillance capable of enveloping a large area with high spatio-temporal granularity. Forecasting the pest population will help farmers in making informed decisions at the right time. This will also help the government and policymakers to make the necessary preparations as and when required and may also ensure food security.
Neural Machine Translation for Low-Resource Languages: A Survey
Jun 29, 2021
Neural Machine Translation (NMT) has seen a tremendous spurt of growth in less than ten years, and has already entered a mature phase. While considered as the most widely used solution for Machine Translation, its performance on low-resource language pairs still remains sub-optimal compared to the high-resource counterparts, due to the unavailability of large parallel corpora. Therefore, the implementation of NMT techniques for low-resource language pairs has been receiving the spotlight in the recent NMT research arena, thus leading to a substantial amount of research reported on this topic. This paper presents a detailed survey of research advancements in low-resource language NMT (LRL-NMT), along with a quantitative analysis aimed at identifying the most popular solutions. Based on our findings from reviewing previous work, this survey paper provides a set of guidelines to select the possible NMT technique for a given LRL data setting. It also presents a holistic view of the LRL-NMT research landscape and provides a list of recommendations to further enhance the research efforts on LRL-NMT.
Can Self Reported Symptoms Predict Daily COVID-19 Cases?
May 18, 2021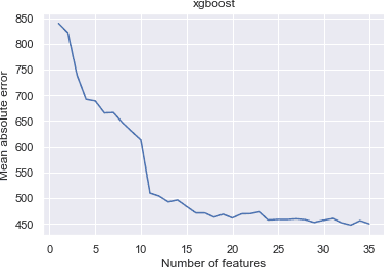
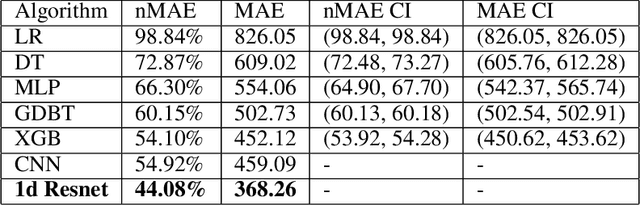
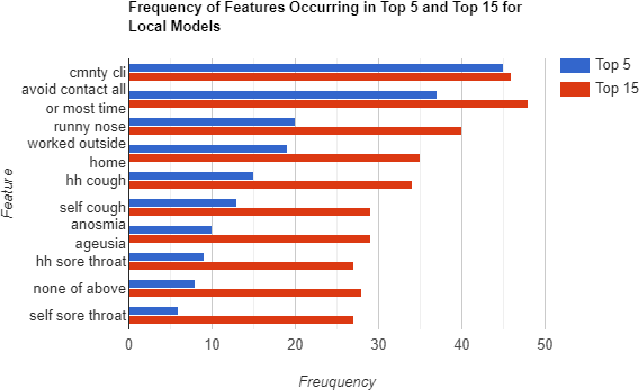

The COVID-19 pandemic has impacted lives and economies across the globe, leading to many deaths. While vaccination is an important intervention, its roll-out is slow and unequal across the globe. Therefore, extensive testing still remains one of the key methods to monitor and contain the virus. Testing on a large scale is expensive and arduous. Hence, we need alternate methods to estimate the number of cases. Online surveys have been shown to be an effective method for data collection amidst the pandemic. In this work, we develop machine learning models to estimate the prevalence of COVID-19 using self-reported symptoms. Our best model predicts the daily cases with a mean absolute error (MAE) of 226.30 (normalized MAE of 27.09%) per state, which demonstrates the possibility of predicting the actual number of confirmed cases by utilizing self-reported symptoms. The models are developed at two levels of data granularity - local models, which are trained at the state level, and a single global model which is trained on the combined data aggregated across all states. Our results indicate a lower error on the local models as opposed to the global model. In addition, we also show that the most important symptoms (features) vary considerably from state to state. This work demonstrates that the models developed on crowd-sourced data, curated via online platforms, can complement the existing epidemiological surveillance infrastructure in a cost-effective manner.
Cooperative control of multi-agent systems to locate source of an odor
Nov 10, 2017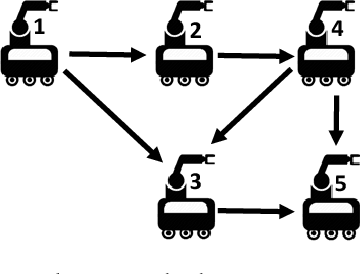
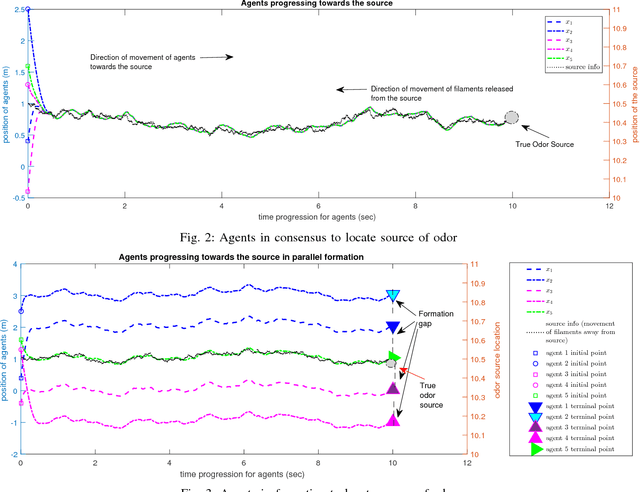
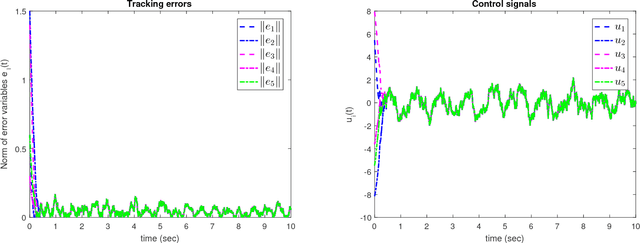
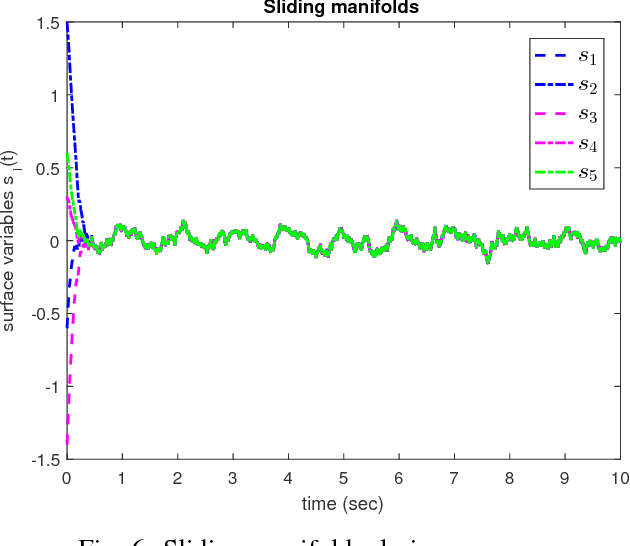
This work targets the problem of odor source localization by multi-agent systems. A hierarchical cooperative control has been put forward to solve the problem of locating source of an odor by driving the agents in consensus when at least one agent obtains information about location of the source. Synthesis of the proposed controller has been carried out in a hierarchical manner of group decision making, path planning and control. Decision making utilizes information of the agents using conventional Particle Swarm Algorithm and information of the movement of filaments to predict the location of the odor source. The predicted source location in the decision level is then utilized to map a trajectory and pass that information to the control level. The distributed control layer uses sliding mode controllers known for their inherent robustness and the ability to reject matched disturbances completely. Two cases of movement of agents towards the source, i.e., under consensus and formation have been discussed herein. Finally, numerical simulations demonstrate the efficacy of the proposed hierarchical distributed control.